在分層的代碼架構中,層與層之間的對象避免不了要做很多轉換、指派等操作,這些操作重複且繁瑣,于是乎催生出很多工具來優雅,高效地完成這個操作,有BeanUtils、BeanCopier、Dozer、Orika等等,本文将講述上面幾個工具的使用、性能對比及原理分析。
其實這幾個工具要做的事情很簡單,而且在使用上也是類似的,是以我覺得先給大家看看性能分析的對比結果,讓大家有一個大概的認識。我是使用JMH來做性能分析的,代碼如下:
要複制的對象比較簡單,包含了一些基本類型;有一次warmup,因為一些工具是需要“預編譯”和做緩存的,這樣做對比才會比較客觀;分别複制1000、10000、100000個對象,這是比較常用數量級了吧。
在我macbook下運作後的結果如下:
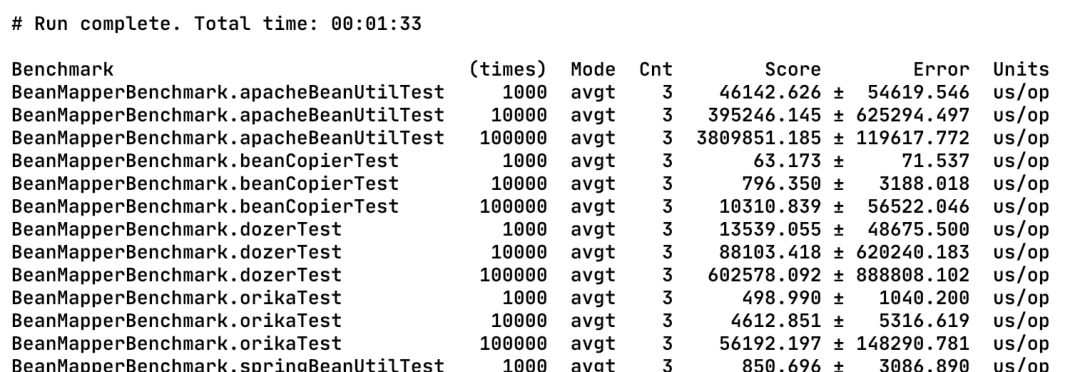
Score表示的是平均運作時間,機關是微秒。從執行效率來看,可以看出 beanCopier > orika > springBeanUtil > dozer > apacheBeanUtil。這樣的結果跟它們各自的實作原理有很大的關系,
下面将詳細每個工具的使用及實作原理。
這個工具可能是大家日常使用最多的,因為是Spring自帶的,使用也簡單:BeanUtils.copyProperties(sourceVO, targetVO);
Spring BeanUtils的實作原理也比較簡答,就是通過Java的Introspector擷取到兩個類的PropertyDescriptor,對比兩個屬性具有相同的名字和類型,如果是,則進行指派(通過ReadMethod擷取值,通過WriteMethod指派),否則忽略。
為了提高性能Spring對BeanInfo和PropertyDescriptor進行了緩存。
(源碼基于:org.springframework:spring-beans:4.3.9.RELEASE)
Spring BeanUtils的實作就是這麼簡潔,這也是它性能比較高的原因。
不過,過于簡潔就失去了靈活性和可擴充性了,Spring BeanUtils的使用限制也比較明顯,要求類屬性的名字和類型一緻,這點在使用時要注意。
Apache的BeanUtils和Spring的BeanUtils的使用是一樣的:
要注意,source和target的入參位置不同。
Apache的BeanUtils的實作原理跟Spring的BeanUtils一樣,也是主要通過Java的Introspector機制擷取到類的屬性來進行指派操作,對BeanInfo和PropertyDescriptor同樣有緩存,但是Apache BeanUtils加了一些不那麼使用的特性(包括支援Map類型、支援自定義的DynaBean類型、支援屬性名的表達式等等)在裡面,使得性能相對Spring的BeanUtils來說有所下降。
(源碼基于:commons-beanutils:commons-beanutils:1.9.3)
Apache BeanUtils的實作跟Spring BeanUtils總體上類似,但是性能卻低很多,這個可以從上面性能比較看出來。阿裡的Java規範是不建議使用的。
BeanCopier在cglib包裡,它的使用也比較簡單:
隻需要預先定義好要轉換的source類和target類就好了,可以選擇是否使用Converter,這個下面會說到。
在上面的性能測試中,BeanCopier是所有中表現最好的,那麼我們分析一下它的實作原理。
BeanCopier的實作原理跟BeanUtils截然不同,它不是利用反射對屬性進行指派,而是直接使用cglib來生成帶有的get/set方法的class類,然後執行。由于是直接生成位元組碼執行,是以BeanCopier的性能接近手寫
get/set。
BeanCopier.create方法
這裡的意思是用KEY_FACTORY建立一個BeanCopier出來,然後調用create方法來生成位元組碼。
KEY_FACTORY其實就是用cglib通過BeanCopierKey接口生成出來的一個類
通過設定
可以讓cglib輸出生成類的class檔案,我們可以反編譯看看裡面的代碼
下面是KEY_FACTORY的類
繼續跟蹤Generator.create方法,由于Generator是繼承AbstractClassGenerator,這個AbstractClassGenerator是cglib用來生成位元組碼的一個模闆類,Generator的super.create其實調用
AbstractClassGenerator的create方法,最終會調用到Generator的模闆方法generateClass方法,我們不去細究AbstractClassGenerator的細節,重點看generateClass。
這個是一個生成java類的方法,了解起來就好像我們平時寫代碼一樣。
即使沒有使用過cglib也能讀懂生成代碼的流程吧,我們看看沒有使用useConverter的情況下生成的代碼:
在對比上面生成代碼的代碼是不是闊然開朗了。
再看看使用useConverter的情況:
BeanCopier性能确實很高,但從源碼可以看出BeanCopier隻會拷貝名稱和類型都相同的屬性,而且如果一旦使用Converter,BeanCopier隻使用Converter定義的規則去拷貝屬性,是以在convert方法中要考慮所有的屬性。
上面提到的BeanUtils和BeanCopier都是功能比較簡單的,需要屬性名稱一樣,甚至類型也要一樣。但是在大多數情況下這個要求就相對苛刻了,要知道有些VO由于各種原因不能修改,有些是外部接口SDK的對象,
有些對象的命名規則不同,例如有駝峰型的,有下劃線的等等,各種什麼情況都有。是以我們更加需要的是更加靈活豐富的功能,甚至可以做到定制化的轉換。
Dozer就提供了這些功能,有支援同名隐式映射,支援基本類型互相轉換,支援顯示指定映射關系,支援exclude字段,支援遞歸比對映射,支援深度比對,支援Date to String的date-formate,支援自定義轉換Converter,支援一次mapping定義多處使用,支援EventListener事件監聽等等。不僅如此,Dozer在使用方式上,除了支援API,還支援XML和注解,滿足大家的喜好。更多的功能可以參考這裡
由于其功能很豐富,不可能每個都示範,這裡隻是給個大概認識,更詳細的功能,或者XML和注解的配置,請看官方文檔。
Dozer的實作原理本質上還是用反射/Introspector那套,但是其豐富的功能,以及支援多種實作方式(API、XML、注解)使得代碼看上去有點複雜,在翻閱代碼時,我們大可不必理會這些類,隻需要知道它們大體的作用就行了,重點關注核心流程和代碼的實作。下面我們重點看看建構mapper的build方法和實作映射的map方法。
build方法很簡單,它是一個初始化的動作,就是通過使用者的配置來建構出一系列後面要用到的配置對象、上下文對象,或其他封裝對象,我們不必深究這些對象是怎麼實作的,從名字上我們大概能猜出這些對象是幹嘛,負責什麼就可以了。
map方法是映射對象的過程,其入口是MappingProcessor的mapGeneral方法
一般情況下createByCreationDirectiveAndMap方法會一直調用到mapFromFieldMap方法,而在沒有自定義converter的情況下會調用mapOrRecurseObject方法
大多數情況下字段的映射會在這個方法做一般的解析
mapCustomObject方法。其實你會發現這個方法最重要的一點就是做遞歸處理,無論是最後調用createByCreationDirectiveAndMap還是mapToDestObject方法。
Dozer功能強大,但底層還是用反射那套,是以在性能測試中它的表現一般,僅次于Apache的BeanUtils。如果不追求性能的話,可以使用。
Orika可以說是幾乎內建了上述幾個工具的優點,不僅具有豐富的功能,底層使用Javassist生成位元組碼,運作 效率很高的。
Orika基本支援了Dozer支援的功能,這裡我也是簡單介紹一下Orika的使用,具體更詳細的API可以參考User Guide。
在講解實作原理時,我們先看看Orika在背後幹了什麼事情。
通過增加以下配置,我們可以看到Orika在做映射過程中生成mapper的源碼和位元組碼。
用上面的例子,我們看看Orika生成的java代碼:
這個mapper類就兩個方法mapAtoB和mapBtoA,從名字看猜到前者是負責src -> dest的映射,後者是負責dest -> src的映射。
好,我們們看看實作的過程。
Orika的使用跟Dozer的類似,首先通過配置生成一個MapperFactory,再用MapperFacade來作為映射的統一入口,這裡MapperFactory和MapperFacade都是單例的。mapperFactory在做配置類映射時,隻是注冊了ClassMap,還沒有真正的生成mapper的位元組碼,是在第一次調用getMapperFacade方法時才初始化mapper。下面看看getMapperFacade。
(源碼基于 ma.glasnost.orika:orika-core:1.5.4)
利用注冊的ClassMap資訊和MappingContext上下文資訊來構造mapper
跟蹤buildMapper方法
MapperGenerator的build方法
生成mapper執行個體
這裡的compilerStrategy的預設是用Javassist(你也可以自定義生成位元組碼的政策)
JavassistCompilerStrategy的compileClass方法
這基本上就是一個使用Javassist的過程,經過前面的各種鋪墊(通過配置資訊、上下文資訊、拼裝java源代碼等等),終于來到這一步
好,mapper類生成了,現在就看在調用MapperFacade的map方法是如何使用這個mapper類的。
其實很簡單,還記得生成的mapper是放到mappersRegistry嗎,跟蹤代碼,在resolveMappingStrategy方法根據typeA和typeB在mappersRegistry找到mapper,在調用mapper的mapAtoB或mapBtoA方法即可。
總體來說,Orika是一個功能強大的而且性能很高的工具,推薦使用。
通過對BeanUtils、BeanCopier、Dozer、Orika這幾個工具的對比,我們得知了它們的性能以及實作原理。在使用時,我們可以根據自己的實際情況選擇,推薦使用Orika。
![拷貝工具BeanUtilsBean擴充拷貝工具BeanUtilsBean擴充[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)