在機器學習、模式識别的模型訓練之前,通常需要對資料進行預處理工作,在哪種情況下選用哪種預處理方法,仍然是很多從業人員比較頭疼的事情。本人前面的兩篇部落格總結了一些比較常用的資料歸一化方法:
資料預處理之歸一化
再談機器學習中的歸一化方法
這兩篇部落格介紹的都是針對非時間序列的資料進行的一些正常操作。由于時間序列的特殊性(1、相鄰序列之間的模式相關性,2、在時間次元上資料是不斷産生的),是以其歸一化方法也有别于非時間序列的歸一化方法。通常時間序列分析的立足點在于發現異常模式或者異常值。在歸一化方法的選用上,也應該盡可能的利于後續算法/模型工作。在此篇部落格中,将對時間序列的歸一化方法進行簡單的介紹。
一、傳統的歸一化方法通常是進行全局歸一化,比如利用全局範圍内的最大值最小值對資料進行限制:
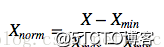
這種方法簡單易于了解,缺點是最大值最小值通常是噪聲造成的,特别是時間序列,由于涉及時間範圍廣,資料的測量裝置可能中途更換、測量條件不同,導緻同一信号的幅值差異巨大,采用此種方法将導緻部分時間序列失真、同時不利于不同時段不同模式的對比。
二、在全局歸一化的基礎上、結合小波/傅裡葉變換中加窗的思想,産生了加窗歸一化。
利用視窗内序列的極大值、極小值對該視窗内的時間序列進行歸一化,這種方法一定程度上解決了時間跨度多大時不同測量條件下序列幅值差異的問題,不過由噪聲引起的極大值極小值仍然嚴重影響了歸一化的效果。
單純的利用最大值最小值、極大值極小值盡管可以将資料進行限制,但是無法滿足時間序列的分析要求。在此介紹一種時間序列的自适應歸一化方法:
給定時間序列S,對S加窗分段後S共由n段視窗長度為L的序列構成:

對S進行自适應歸一化,歸一化後序列為
算法描述如下:
1、該算法在歸一化的同時由于考慮到了相鄰時間序列的相關性(相鄰時間序列的關系因子由參數
控制),是以歸一化成敗的關鍵在于參數
的選取。具體需要結合自己的需要和時間序列特征進行控制,由于算法簡單、計算量小的特點,初次使用時對這兩個參數進行簡單的周遊搜尋是個不錯的選擇;2、由于該算法中極大值極小值對歸一化效果并不占支配地位,通常歸一化後的時間序列中正常值在-1至+1之間,而異常值的幅值将遠遠大于1,是以該算法對發現極端值是非常有效的,比如對某地的近半個世紀的降雨情況進行歸一化處理,部分年份中極端的降雨情況将更加容易發現。
最後,資料預處理的方法仁者見仁、智者見智,實際運用時更多的是需要結合業務和使用的模型這些方面進行考量。