首先,說明幾個知識要點:
(1)所有3種類型的VMware網絡都支援NICTeaming(複習提問:哪3種類型?答:VMkernel,ServiceConsole和VMportgroup)
(2)uplink連接配接到那些實體交換機的端口都必須在同一個Broadcastdomain中。(也就是必須在同一個VLAN中,不能跨路由)
(3)如果uplink要配置VLAN,則每個uplink必須都配置成VLANTrunk并且具有相同的VLAN配置。
(4)VMware的負載均衡(LoadBalancing)隻是出站(Outbound)的負載均衡。(概念類似于HP術語中的TLB。關于HP負載均衡的術語詳見拙文《HPNICTeaming技術探讨》,但是它和TLB其實不同,關于這一點,請看後文解釋)
(參考:p192.ScottLowe,《MasteringVMwarevSphere4.0》)
(5)NICTeaming的LoadBalancing和一些進階路由算法的LoadBalancing不同,它不是按照Teaming中網卡上通過的資料流量來負載均衡,而是根據網卡上的連接配接(connection)來進行負載均衡。
【VMware的3種負載均衡】
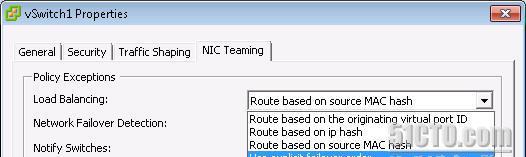
VMware的NICTeamingLoadBalancing政策有3種。
(1)基于端口的負載均衡(預設)
(2)基于源MAC的負載均衡
(3)基于IPhash的負載均衡
基于端口的負載均衡(RoutebasedontheoriginatingvirtualportID)
這種方式下,負載均衡是基于vPortID的。一個vPort和Host上的一個pNIC(從vSwitch角度看就是某個uplink)捆綁在一起,隻有當這個pNIC失效的時候,才切到另外的pNIC鍊路上。這種方式的負載均衡隻有在vPort數量大于pNIC的數量時才生效。
什麼是vport?一個VM上的vNIC或者某一個VMKernel或者ServiceConsole的某個vswif。用一個圖來直覺的表述,vPort在下圖中顯示為vSwitch上左側的那些綠點。而pNIC在圖中顯示為右邊的vmnicX。(還記得建立一個vSwitch時候,預設的port數是56嗎?你可以設定一個vSwitch的Port數為8,24,56,120,248,504或1016,看出什麼規律來了沒?對的,是2的某次方減8。這是因為VMKernel需要保留8個port的緣故)

對于VM來說,因為某台VM的vNIC是捆綁在某一個pNIC上的,也就是說這台VM(如果隻有一個vNIC的話)對外的資料流量将固定在某一個pNIC上。這種負載均衡是在VM之間的均衡,對于某一台VM而言,其uplink的速率不可能大于單個pNIC的速率。此外,隻有當VM的數量足夠多,并且這些VM之間的資料流量基本一緻的情況下,Host上的NICTeaming的LoadBalancing才較為有效。對于以下這些極端情況,基于端口方式的負載均衡根本不起作用或者效果很差,充其量隻能說是一種端口備援。
(1)Host上隻有一台隻具有單vNIC的VM(此時完全沒有Loadbalancing)
(2)Host上的VM數量比pNIC少(比如有4台VM但是Teaming中有5塊pNIC,此時有一塊pNIC完全沒用上,其他每個vNIC各自使用一塊pNIC,此時也沒有任何負載均衡實作)
(3)Host上雖然有多台VM,但是99%的網絡流量都是某一台VM産生的
基于源MAC位址的負載均衡RoutebasedonsourceMAChash
這種方式下,負載均衡的實作是基于源MAC位址的。因為每個vNIC總是具有一個固定的MAC位址,是以這種方式的負載均衡同基于端口的負載均衡具有同樣的缺點。同樣是要求vPort數量大于pNIC的時候才會有效。同樣是vNIC的速率不會大于單個pNIC的速率。
基于IPHash的負載均衡RoutebasedonIPhash
這種方式下,負載均衡的實作是根據源IP位址和目的IP位址的。是以同一台VM(源IP位址總是固定的)到不同目的的資料流,就會因為目的IP的不同,走不同的pNIC。隻有這種方式下,VM對外的流量的負載均衡才能真正實作。
不要忘記,VMware是不關心對端實體交換機的配置的,VMware的負載均衡隻負責從Host出站的流量(outbound),是以要做到Inbound的負載均衡,必須在實體交換機上做同樣IPHash方式的配置。此時,pNIC必須連接配接到同一個實體交換機上。
需要注意的是,VMware不支援動态鍊路聚合協定(例如802.3adLACP或者Cisco的PAgP),是以隻能實作靜态的鍊路聚合。(類似于HP的SLB)。不僅如此,對端的交換機設定靜态鍊路聚合的時候也要設定成IPHash的算法。否則這種方式的負載均衡将無法實作。
比如Cisco3560上的預設Etherchannel的算法是源MAC,是以需要将其修改成源和目的IP。
首先檢視交換機的負載均衡的算法:
show etherchannel load-balance
然後用修改負載均衡算法為src-dst-ip
port-channel load-balance src-dst-ip
要點:配置IPHash方式pNIC對端的實體交換機端口,要記得關閉802.3adLACP和PAgP以減少這些動态協定帶來的不必要網絡開銷,加快鍊路在failover時的轉換速度。
這種方式的缺點是,因為pNIC是連接配接到同一台實體交換機的,是以存在交換機的單點失敗問題。(這和HPSLB的缺點一樣,詳見拙文《HPNICTeaming技術探讨》)。此外,在點對點的鍊路中(比如VMotion),2端位址總是固定的,是以基于IPHash的鍊路選擇算法就失去了意義。
不管采用以上哪一種方法的LoadBalancing,它會增加總聚合帶寬,但不會提升某單個連接配接所獲的帶寬。為啥會這樣?同一個Session中的資料包為啥不能做到LoadBalancing?這是因為網絡的7層模型中,一個Session在傳輸過程中會被拆分成多個資料包,并且到目的之後再重組,他們必須具有一定的順序,如果這個順序弄亂了,那麼到達目的重組出來的資訊就是一堆無意義的亂碼。這就要求同一個session的資料包必須在同一個實體鍊路中按照順序傳輸過去。是以,10條1Gb鍊路組成的10Gb的聚合鍊路,一定不如單條10Gb鍊路來的高速和有效。(詳見Fraizer:IEEE802.3adLinkAggregation(LAG)-Whatitis,andwhatitisnot)
【選擇】
那麼應該選擇哪種NICTeaming方式呢?大拿ScottLowe建議:
如果使用鍊路聚合,必須設為“RoutebasedonIPhash”
如果不是使用鍊路聚合,可以設為任何其它設定。大多數情況下,接受預設設定“RoutebasedonoriginatingvirtualportID”是最好的。
【更好的選擇及其缺陷】
還有沒有更好選擇?答案是有。Cross-StackLinkAggregation,跨堆疊交換機的鍊路聚合。
堆疊交換機通過堆疊線連接配接在一起,組成一個交換機堆疊棧。堆疊棧中的交換機共享同一個ForwardingTable。
堆疊交換機組在邏輯上被視作1台交換機,但是在實體上則是2台或多台不同的裝置。
這和NICTeaming是不是很像?
Teamport在邏輯上是一個端口,但是在實體上卻是2個或多個端口。
(突然想到,在一切都套上“虛拟化”的帽子的今日,不知道以後交換機堆疊技術會不會改名為交換機虛拟化?就像存在了多少年的RAID突然被套上了磁盤虛拟化的帽子一樣,笑~~)
如圖,SLB中的2條鍊路就可以不局限在同一台實體交換機上了,而可以分别連接配接到2台堆疊在一起的實體交換機上(切記,交換機堆疊必須連成環以保證備援性)。此時,SLB的最大缺陷——交換機的單點失敗就被克服了。這樣,就可以既達到容錯又達到雙向負載均衡的目的了。
但是,這種方式的缺點是要求實體交換機具有堆疊能力。很遺憾的是,HP支援工程師告訴我,到目前為止,HP用于c-class刀片伺服器機箱的所有以太網交換機都不支援堆疊。(資訊擷取時間2010年1月,不排除以後HP會提供支援堆疊的刀片交換機)
【參考文檔】
本文的主要參考的文檔如下:
(1)ScottLowe,《MasteringVMwarevSphere4.0》
(2)VMwareInfrastructure3環境下的實體網絡設計(ScottLowe)
http://www.searchsv.com.cn/showcontent_14740.htm?lg=t
(3)如何在VMwareESX上實作網卡聚合?
http://www.searchsv.com.cn/showcontent_24716.htm
(4)ESXServer,NICTeaming,andVLANTrunking(ScottLowe)
http://blog.scottlowe.org/2006/12/04/esx-server-nic-teaming-and-vlan-trunking/
(5)IEEE802.3adLinkAggregation(LAG)-Whatitis,andwhatitisnot
http://www.ieee802.org/3/hssg/public/apr07/frazier_01_0407.pdf
本文出自“delxuTechNotebook”部落格,請務必保留此出處http://delxu.blog.51cto.com/975660/276642