訂單相關表都已經是超大表,最大表的資料量已經是幾十億,資料庫處理能力已經到了極限;單庫包含多個超大表,占用的硬碟空間已經接近了伺服器的硬碟極限,很快将無空間可用;過度解決:我們可以考慮到最直接的方式是增加大容量硬碟,或者對IO有更高要求,還可以考慮增加SSD硬碟來解決容量的問題。此方法無法解決單表資料量問題。可以對資料表曆史資料進行歸檔,但也需要頻繁進行歸檔操作,而且不能解決性能問題硬體上(大小)、單表容量(性能)。
資料庫的讀寫分離
資料庫量還是很龐大,隻是讀和寫資料的分離
換mysql》oracle
免費到收費誰能接受
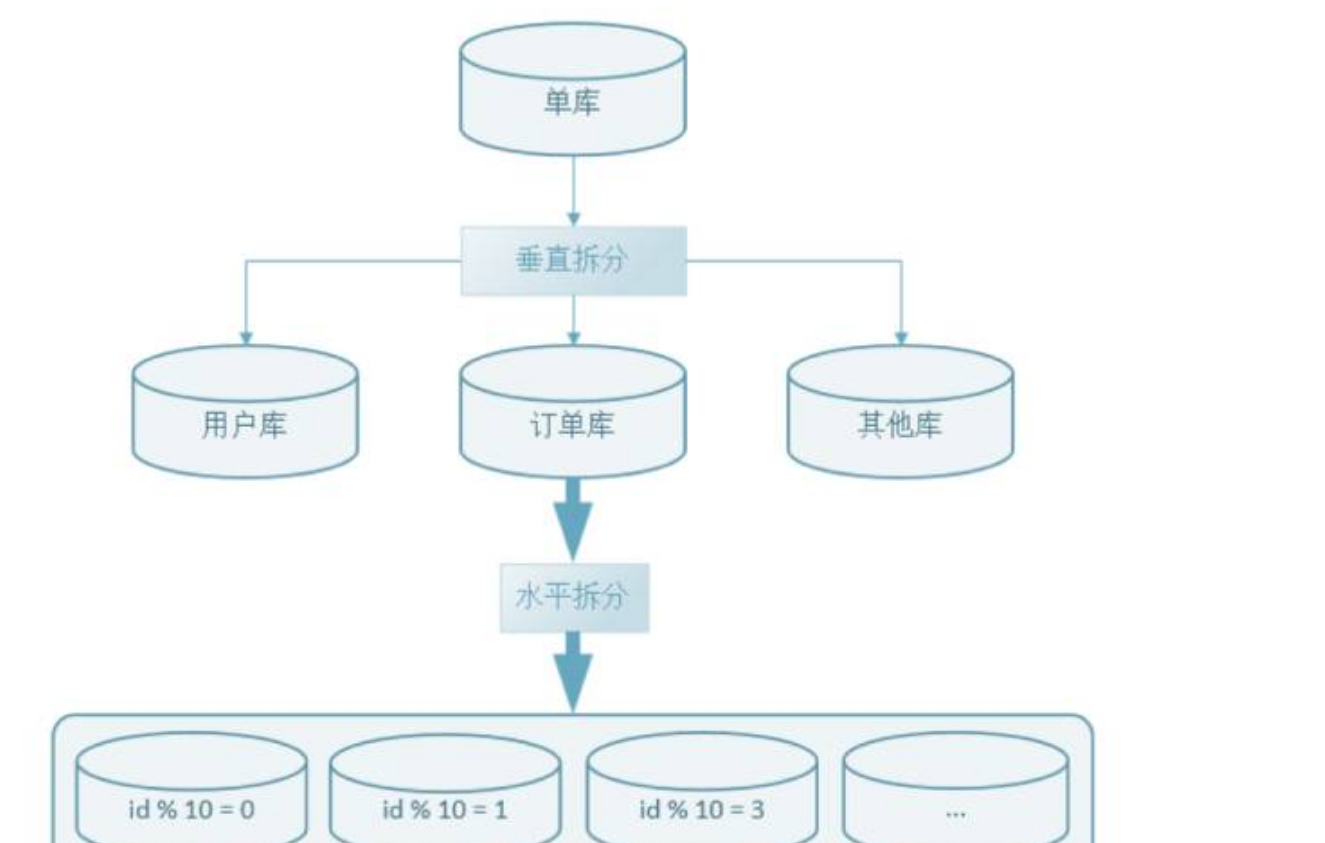
分庫分表
1、散列hash:hashmap可以很好的去解決資料熱點的問題,但是擴容 短闆 2、Range增量:他的庫容很多好,但是他就是沒法解決資料熱點的問題。
shardingsphere的方式來完成分庫分表,表中的一列确定分庫鍵。

分庫分表之分布式唯一ID解決方案
Uuid
通用唯一識别碼
組成部分:目前日期和時間+時鐘序列+全局唯一網卡mac位址擷取
執行任務數:10000
所有線程共耗時:91.292 s
并發執行完耗時:1.221 s
單任務平均耗時:9.1292 ms
單線程最小耗時:0.0 ms
單線程最大耗時:470.0 ms
優點:
代碼實作簡單、不占用寬帶、資料遷移不影響。
缺點:
無序、無法保證趨勢遞增、字元存儲、傳輸、查詢慢。
Snowflke
snowflake是Twitter開源的分布式ID生成算法。
傳統資料庫軟體開發中,主鍵自動生成技術是基本需求。而各個資料庫對于該需求也提供了相應的支援,比如MySQL的自增鍵,Oracle的自增序列等。 資料分片後,不同資料節點生成全局唯一主鍵是非常棘手的問題。同一個邏輯表内的不同實際表之間的自增鍵由于無法互相感覺而産生重複主鍵。 雖然可通過限制自增主鍵初始值和步長的方式避免碰撞,但需引入額外的運維規則,使解決方案缺乏完整性和可擴充性。
io.shardingsphere.core.keygen.DefaultKeyGenerator
所有線程共耗時:15.111 s
并發執行完耗時:217.0 ms
單任務平均耗時:1.5111 ms
單線程最大耗時:97.0 ms
不占用寬帶、本地生成、高位是毫秒,低位遞增。
強依賴時鐘,如果時間回撥,資料遞增不安全。
Mysql
利用資料庫的步長來做的。
CREATE TABLE <code>bit_table</code> (
<code>id</code> varchar(255) NOT NULL,//字元
PRIMARY KEY (<code>id</code>)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE <code>bit_num</code> (
<code>id</code> bigint(11) NOT NULL AUTO_INCREMENT,
KEY (<code>id</code>) USING BTREE
) ENGINE=InnoDB auto_increment=1 DEFAULT CHARSET=utf8;
SET global auto_increment_offset=1; --初始化
SET global auto_increment_increment=100; --初始步長
show global variables;
缺點:
受限資料庫、單點故障、擴充麻煩。
性能可以、可讀性強、數字排序。
Redis
redis原子性:對存儲在指定key的數值執行原子的加1操作。如果指定的key不存在,那麼在執行incr操作之前,會先将它的值設定為0
組成部分:年份+當天當年第多少天+天數+小時+redis 自增
所有線程共耗時:746.767 s
并發執行完耗時:9.381 s
單任務平均耗時:74.6767 ms
單線程最大耗時:4.119 s
有序遞增、可讀性強、符合剛才我們那個擴容方案的id。
占用寬帶(網絡)、依賴第三方、redis。
場景
名稱
适用指數
Token、圖檔id
★★
Snowflake
ELK、MQ、業務系統
★★★★
資料庫
非大型電商系統
★★★
大型系統
★★★★★
PS:分庫分表對于大型系統必須考慮,提前使用第三方工具來完成,如果使用shardsphere來完成比較好,也可以使用mycat。