移動網際網路時代,海量的使用者每天産生海量的數量,比如:
- 使用者表
- 訂單表
- 交易流水表
以支付寶使用者為例,8億;微信使用者更是10億。訂單表更誇張,比如美團外賣,每天都是幾千萬的訂單。淘寶的曆史訂單總量應該百億,甚至千億級别,這些海量資料遠不是一張表能Hold住的。事實上MySQL單表可以存儲10億級資料,隻是這時候性能比較差,業界公認MySQL單表容量在1KW量級是最佳狀态,因為這時它的BTREE索引樹高在3~5之間。
既然一張表無法搞定,那麼就想辦法将資料放到多個地方,目前比較普遍的方案有3個:
- 分區;
- 分庫分表;
- NoSQL/NewSQL;
說明:隻分庫,或者隻分表,或者分庫分表融合方案都統一認為是分庫分表方案,因為分庫,或者分表隻是一種特殊的分庫分表而已。NoSQL比較具有代表性的是MongoDB,es。NewSQL比較具有代表性的是TiDB。
Why Not NoSQL/NewSQL?
-
首先,為什麼不選擇第三種方案NoSQL/NewSQL,我認為主要是RDBMS有以下幾個優點:
RDBMS生态完善
RDBMS絕對穩定
RDBMS的事務特性
NoSQL/NewSQL作為新生兒,在我們把可靠性當做首要考察對象時,它是無法與RDBMS相提并論的。RDBMS發展幾十年,隻要有軟體的地方,它都是核心存儲的首選。
目前絕大部分公司的核心資料都是:以RDBMS存儲為主,NoSQL/NewSQL存儲為輔!網際網路公司又以MySQL為主,國企&銀行等不差錢的企業以Oracle/DB2為主!NoSQL/NewSQL宣傳的無論多牛逼,就現在各大公司對它的定位,都是RDBMS的補充,而不是取而代之!
Why Not 分區?
我們再看分區表方案。了解這個方案之前,先了解它的原理:
分區表是由多個相關的底層表實作,這些底層表也是由句柄對象表示,是以我們也可以直接通路各個分區,存儲引擎管理分區的各個底層表和管理普通表一樣(所有的底層表都必須使用相同的存儲引擎),分區表的索引隻是在各個底層表上各自加上一個相同的索引,從存儲引擎的角度來看,底層表和一個普通表沒有任何不同,存儲引擎也無須知道這是一個普通表還是一個分區表的一部分。
事實上,這個方案也不錯,它對使用者屏蔽了sharding的細節,即使查詢條件沒有sharding column,它也能正常工作(隻是這時候性能一般)。不過它的缺點很明顯:很多的資源都受到單機的限制,例如連接配接數,網絡吞吐等!雖然每個分區可以獨立存儲,但是分區表的總入口還是一個MySQL示例。進而導緻它的并發能力非常一般,遠遠達不到網際網路高并發的要求!
至于網上提到的一些其他缺點比如:無法使用外鍵,不支援全文索引。我認為這都不算缺點,21世紀的項目如果還是使用外鍵和資料庫的全文索引,我都懶得吐槽了!
是以,如果使用分區表,你的業務應該具備如下兩個特點:
- 資料不是海量(分區數有限,存儲能力就有限);
- 并發能力要求不高;
Why 分庫分表?
最後要介紹的就是目前網際網路行業處理海量資料的通用方法:分庫分表。
雖然大家都是采用分庫分表方案來處理海量核心資料,但是還沒有一個一統江湖的中間件,筆者這裡列舉一些有一定知名度的分庫分表中間件:
- 阿裡的TDDL,DRDS和cobar,
- 開源社群的sharding-jdbc(3.x已經更名為sharding-sphere);
- 民間組織的MyCAT;
- 360的Atlas;
- 美團的zebra;
但是這麼多的分庫分表中間件全部可以歸結為兩大類型:
- CLIENT模式;
- PROXY模式;
CLIENT模式代表有阿裡的TDDL,開源社群的sharding-jdbc(sharding-jdbc的3.x版本即sharding-sphere已經支援了proxy模式)。架構如下:
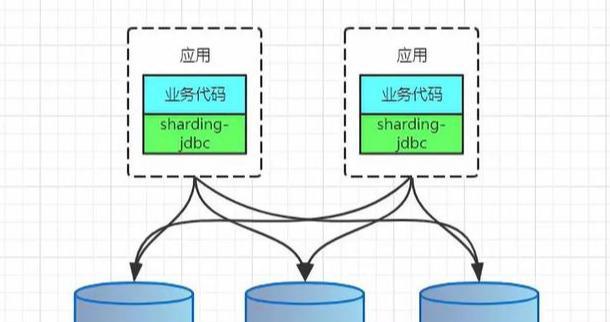
client arch
PROXY模式代表有阿裡的cobar,民間組織的MyCAT。架構如下:

proxy arch
但是,無論是CLIENT模式,還是PROXY模式。幾個核心的步驟是一樣的:SQL解析,重寫,路由,執行,結果歸并。
筆者比較傾向于CLIENT模式,架構簡單,性能損耗較小,運維成本低。
接下來,以幾個常見的大表為案例,說明分庫分表如何落地!
實戰案例
分庫分表第一步也是最重要的一步,即sharding column的選取,sharding column選擇的好壞将直接決定整個分庫分表方案最終是否成功。而sharding column的選取跟業務強相關,筆者認為選擇sharding column的方法最主要分析你的API流量,優先考慮流量大的API,将流量比較大的API對應的SQL提取出來,将這些SQL共同的條件作為sharding column。例如一般的OLTP系統都是對使用者提供服務,這些API對應的SQL都有條件使用者ID,那麼,使用者ID就是非常好的sharding column。
這裡列舉分庫分表的幾種主要處理思路:
- 隻選取一個sharding column進行分庫分表 ;
- 多個sharding column多個分庫分表;
- sharding column分庫分表 + es;
再以幾張實際表為例,說明如何分庫分表。
訂單表
訂單表幾個核心字段一般如下:
訂單表
以阿裡訂單系統為例(參考《企業IT架構轉型之道:阿裡巴巴中台戰略思想與架構實作》),它選擇了三個column作為三個獨立的sharding column,即:order_id,user_id,merchant_code。user_id和merchant_code就是買家ID和賣家ID,因為阿裡的訂單系統中買家和賣家的查詢流量都比較大,并且查詢對實時性要求都很高。而根據order_id進行分庫分表,應該是根據order_id的查詢也比較多。
這裡還有一點需要提及,多個sharding-column的分庫分表是備援全量還是隻備援關系索引表,需要我們自己權衡。
備援全量的情況如下–每個sharding列對應的表的資料都是全量的,這樣做的優點是不需要二次查詢,性能更好,缺點是比較浪費存儲空間(淺綠色字段就是sharding-column):
備援全量
備援關系索引表的情況如下–隻有一個sharding column的分庫分表的資料是全量的,其他分庫分表隻是與這個sharding column的關系表,這樣做的優點是節省空間,缺點是除了第一個sharding column的查詢,其他sharding column的查詢都需要二次查詢,這三張表的關系如下圖所示(淺綠色字段就是sharding column):
表之間的關系圖
備援全量表PK.備援關系表
- 速度對比:備援全量表速度更快,備援關系表需要二次查詢,即使有引入緩存,還是多一次網絡開銷;
- 存儲成本:備援全量表需要幾倍于備援關系表的存儲成本;
- 維護代價:備援全量表維護代價更大,涉及到資料變更時,多張表都要進行修改。
總結:選擇備援全量表還是索引關系表,這是一種架構上的trade off,兩者的優缺點明顯,阿裡的訂單表是備援全量表。
使用者表
使用者表幾個核心字段一般如下:
使用者表
一般使用者登入場景既可以通過mobile_no,又可以通過email,還可以通過username進行登入。但是一些使用者相關的API,又都包含user_id,那麼可能需要根據這4個column都進行分庫分表,即4個列都是sharding-column。
賬戶表
賬戶表幾個核心字段一般如下:
賬戶表
與賬戶表相關的API,一般條件都有account_no,是以以account_no作為sharding-column即可。
複雜查詢
上面提到的都是條件中有sharding column的SQL執行。但是,總有一些查詢條件是不包含sharding column的,同時,我們也不可能為了這些請求量并不高的查詢,無限制的備援分庫分表。那麼這些條件中沒有sharding column的SQL怎麼處理?以sharding-jdbc為例,有多少個分庫分表,就要并發路由到多少個分庫分表中執行,然後對結果進行合并。具體如何合并,可以看筆者sharding-jdbc系列文章,有分析源碼講解合并原理。
這種條件查詢相對于有sharding column的條件查詢性能很明顯會下降很多。如果有幾十個,甚至上百個分庫分表,隻要某個表的執行由于某些因素變慢,就會導緻整個SQL的執行響應變慢,這非常符合木桶理論。
更有甚者,那些營運系統中的模糊條件查詢,或者上十個條件篩選。這種情況下,即使單表都不好建立索引,更不要說分庫分表的情況下。那麼怎麼辦呢?這個時候大名鼎鼎的elasticsearch,即es就派上用場了。将分庫分表所有資料全量備援到es中,将那些複雜的查詢交給es處理。
淘寶我的所有訂單頁面如下,篩選條件有多個,且商品标題可以模糊比對,這即使是單表都解決不了的問題(索引滿足不了這種場景),更不要說分庫分表了:
條件篩選
是以,以訂單表為例,整個架構如下:
archeitecture
具體情況具體分析:多sharding column不到萬不得已的情況下最好不要使用,成本較大,上面提到的使用者表筆者就不太建議使用。因為使用者表有一個很大的特點就是它的上限是肯定的,即使全球70億人全是你的使用者,這點資料量也不大,是以筆者更建議采用單sharding column + es的模式簡化架構。
ElasticSearch+HBase簡要
這裡需要提前說明的是,solr+HBase結合的方案在社群中出現的頻率可能更高,本篇文章為了保持一緻性,所有全文索引方案選型都是es。至于es+HBase和solr+HBase孰優孰劣,或者說es和solr孰優孰劣,不是本文需要讨論的範疇,事實上也沒有太多讨論的意義。es和solr本就是兩個非常優秀且旗鼓相當的中間件。最近幾年es更火爆:
es V.S. solr
如果抛開選型過程中所有曆史包袱,單論es+HBase和solr+HBase的優劣,很明顯後者是更好的選擇。solr+HBase高度內建,引入索引服務後我們最關心,也是最重要的索引一緻性問題,solr+HBase已經有了非常成熟的解決方案一一Lily HBase Indexer。
延伸閱讀
ElasticSearch+HBase原理
剛剛讨論到上面的以MySQL為核心,分庫分表+es的方案,随着資料量越來越來,雖然分庫分表可以繼續成倍擴容,但是這時候壓力又落到了es這裡,這個架構也會慢慢暴露出問題!
一般訂單表,積分明細表等需要分庫分表的核心表都會有好幾十列,甚至上百列(假設有50列),但是整個表真正需要參與條件索引的可能就不到10個條件(假設有10列)。這時候把50個列所有字段的資料全量索引到es中,對es叢集有很大的壓力,後面的es分片故障恢複也會需要很長的時間。
這個時候我們可以考慮減少es的壓力,讓es叢集有限的資源盡可能儲存條件檢索時最需要的最有價值的資料,即隻把可能參與條件檢索的字段索引到es中,這樣整個es叢集壓力減少到原來的1/5(核心表50個字段,隻有10個字段參與條件),而50個字段的全量資料儲存到HBase中,這就是經典的es+HBase組合方案,即索引與資料存儲隔離的方案。
Hadoop體系下的HBase存儲能力我們都知道是海量的,而且根據它的rowkey查詢性能那叫一個快如閃電。而es的多條件檢索能力非常強大。這個方案把es和HBase的優點發揮的淋漓盡緻,同時又規避了它們的缺點,可以說是一個揚長避免的最佳實踐。
它們之間的互動大概是這樣的:先根據使用者輸入的條件去es查詢擷取符合過濾條件的rowkey值,然後用rowkey值去HBase查詢,後面這一查詢步驟的時間幾乎可以忽略,因為這是HBase最擅長的場景,互動圖如下所示:
文章來源:https://youyou-tech.com/2019/11/23/HBase%E5%AE%9E%E6%88%98%E4%B8%A8%E4%BB%8EMySQL%E5%88%B0HBase/