1. 引言
從今天開始系統的學習網絡爬蟲。寫這篇部落格的目的在于,一來記錄下自己的學習過程;二來希望可以給像我一樣不懂爬蟲但又對爬蟲十分感興趣的人帶來一些幫助。
昨天去圖書館找有關爬蟲書籍,居然寥寥無幾,且都是泛泛而談。之後上某寶淘來淘去,隻找到一本相關書籍《自己動手寫網絡爬蟲》,雖然在某瓣上看到此書的無數差評,但最終還是忍痛買下……
對我而言,學習爬蟲不是學習如何使用API(學API看幫助文檔就ok了),而是學習爬蟲的算法和資料結構,即學習爬蟲的爬取政策,任務排程,資料挖掘,資料存儲以及整個系統的架構。是以我會花較多的篇幅去記錄以上提到的點,而不會去過多地介紹API如何調用。
這篇文章作為自己第一篇學習爬蟲的博文,隻想記錄一些最最基本的概念,并簡單實作一個最最基本的爬蟲:它能夠根據種子節點以特定的政策來爬取頁面,直到達到設定的條件,并将這些頁面儲存在磁盤中。 我們使用Java作為程式設計語言。
2. 分析
(1) 算法分析
我們現在從需求中提取關鍵詞來逐漸分析問題。
首先是“種子節點”。它就是一個或多個在爬蟲程式運作前手動給出的URL(網址),爬蟲正是下載下傳并解析這些種子URL指向的頁面,從中提取出新的URL,然後重複以上的工作,直到達到設定的條件才停止。
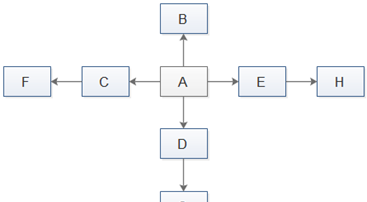
然後是“特定的政策”。這裡所說的政策就是以怎樣的順序去請求這些URL。如下圖是一個簡單的頁面指向示意圖(實際情況遠比這個複雜),頁面A是種子節點,當然最先請求。但是剩下的頁面該以何種順序請求呢?我們可以采用深度優先周遊政策,通俗講就是一條路走到底,走完一條路才再走另一條路,在下圖中就是按A,B,C,F,D,G,E,H的順序通路。我們也可以采用橫向優先搜尋政策,就是按深度順序去周遊,在下圖中就是按A,B,C,D,E,F,G,H的順序請求各頁面。還有許多其他的周遊政策,如Google經典的PageRank政策,OPIC政策政策,大站優先政策等,這裡不一一介紹了。我們還需要注意的一個問題是,很有可能某個頁面被多個頁面同時指向,這樣我們可能重複請求某一頁面,是以我們還必須過濾掉已經請求過的頁面。
最後是“設定的條件”,爬蟲程式終止的條件可以根據實際情況靈活設定,比如設定爬取時間,爬取數量,爬行深度等。
到此,我們分析完了爬蟲如何開始,怎麼運作,如何結束(當然,要實作一個強大,完備的爬蟲要考慮的遠比這些複雜,這裡隻是入門分析),下面給出整個運作的流程圖:

(2) 資料結構分析
根據以上的分析,我們需要用一種資料結構來儲存初始的種子URL和解析下載下傳的頁面得到的URL,并且我們希望先解析出的URL先執行請求,是以我們用隊列來儲存URL。因為我們要頻繁的添加,取出URL,是以我們采用鍊式存儲。下載下傳的頁面解析後直接原封不動的儲存到磁盤。
(3) 技術分析
所謂網絡爬蟲,我們當然要通路網絡,我們這裡使用jsoup,它對http請求和html解析都做了良好的封裝,使用起來十分友善。根據資料結構分析,我們用LinkedList實作隊列,用來儲存未通路的URL,用HashSet來儲存通路過的URL(因為我們要大量的判斷該URL是否在該集合内,而HashSet用元素的Hash值作為“索引”,查找速度很快)。
3. 實作
(1) 代碼
以上分析,我們一共要實作2個類:
① JsoupDownloader,該類是對Jsoup做一個簡單的封裝,友善調用。暴露出以下幾個方法:
—public Document downloadPage(String url);根據url下載下傳頁面 —public Set<String> parsePage(Document doc, String regex);從Document中解析出比對regex的url。 —public void savePage(Document doc, String saveDir, String saveName, String regex);儲存比對regex的url對應的Document到指定路徑。
② UrlQueue,該類用來儲存和擷取URL。暴露出以下幾個方法:
—public void enQueue(String url);添加url。 —public String deQueue();取出url。 —public int getVisitedCount();擷取通路過的url的數量;
下面給出具體代碼:
JsoupDownloader.java
UrlQueue.java
(2) 測試
下面進行測試,我們來抓取園子裡排行No1的Artech的文章,以他的部落格首頁位址:http://www.cnblogs.com/artech/作為種子節點。通過分析發現,形如:http://www.cnblogs.com/artech/p/…和http://www.cnblogs.com/artech/archive/2012/09/08/…的連結都是有效的文章位址,而形如:http://www.cnblogs.com/artech/default/…的連結是下一頁連結,這些都作為我們篩選url的依據。我們采用橫向優先搜尋政策。Artech的文章數是500餘篇,是以我們以請求頁面數達到1000或周遊完所有滿足條件的url為終止條件。下面是具體的測試代碼:
運作結果:
4. 總結
仔細分析以上過程,還有許多值得優化改進的地方:
① 我們在請求頁面時,隻是做了簡單的異常處理。好的做法是根據http響應的狀态碼來做不同的處理。如對于請求重定向的url我們重新定向;對于找不到資源的url直接丢棄;對于連接配接逾時的url我們可以重新将其放入未通路url隊列中… ② 我們的待通路和已通路url都是直接儲存在記憶體中的。當url數量很多時,可能會發生記憶體溢出。是以需要将資料持久化到硬碟上,但是又要節約空間,能夠快速通路資料。 ③ UrlQueue的enqueue和dequeue方法實際上是有問題的,當解析url速度慢于下載下傳頁面速度或其他原因引起的dequeue快于enqueue時,會導緻程式提前終止。我們可以采用多線程,阻塞隊列(BlockingQueue)來解決這一問題。 ④ 我們目前的爬蟲效率太低,僅爬取600個左右頁面就花費了1分多鐘。我們可以采用多線程,分布式爬取,來提高爬蟲效率。 ⑤ 爬蟲的架構過于簡單,擴充性,靈活性不強。
但不管怎樣,我們的實作基本滿足了文章開始提出的需求,以後會在此基礎上慢慢進行疊代。在下一篇中我們會引入多線程來提高爬蟲的效率;并采用Bloom Filter(布隆過濾器)來建構visited集合;引入Berkeley DB來進行url資料的持久化。