[TOC]
上一講我們講述了線程池整個的過程,這一講我們來先底層的3個元件,synchronized,Unsafe以及LockSupport
首先從名字就可以看出來這個類是不安全的,比較敏感,是以jdk底層也沒有開放使用這個類,該類提供了單利模式擷取Unsafe對象的方法:
是以我們在應用中要擷取該類的執行個體,就得通過反射擷取了,反射擷取靜态私有屬性的方式:
對象的屬性偏移量位址經過編譯後,一般不會再發生變化
這裡需要注意下,修改對象的屬性值,如果是基本屬性,有對應的方法,其他包裝類型或者對象的屬性,需要用unsafe.putObject();
代碼結果
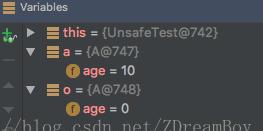
從執行的結果可以看到雖然unsafe可以擷取配置設定對象執行個體,但是這是繞過了對象的構造方法的,執行個體的屬性全部都是沒有經過初始化的,可以了解為unsafe隻是配置設定了對象所屬大小的一段記憶體而已。
注意:通過unsafe.allocateInstance()配置設定的記憶體不屬于java對記憶體,不受jvm控制,是以這裡需要非常謹慎下,必須手動釋放,不然會出現記憶體洩漏,在使用unsafe的時候可以當做在使用C++一樣,自己配置設定的記憶體必須手動釋放!
所謂CAS就是先對比,對比是期望的值再進行修改:
該操作是個原子的,也就是先對比,再進行修改。那是怎麼保證這個原子性的呢?這是個本地方法,是以其實作是通過c++來實作的:
我們看到其源碼中有個spinlock,對應的彙編代碼:

我們看到會在cmpxchg指令前面加上了lock字首,如果是單cpu的話,cmpxchg會忽略lock字首,如果是多cpu的話,會通過總線鎖定和緩存行鎖定來保證讀-改-寫操作的原子性。我們可以舉個例子:
cpu1和cpu2都同時執行:
從記憶體讀取i(此時i=1)變量
執行i = i + 1
把i的最新值寫回到記憶體
那分别看下總線鎖定和緩存行鎖定對這個例子的操作
cpu1執行的時候,會在處理器和記憶體之間的總線上發送一個LOCK#信号,這個時候其他處理器就被阻斷了和記憶體之間的互動,隻有cpu1可以獨享記憶體,是以cpu1就可以非常安全的完成i++的操作。而弊端也非常明顯,因為總線鎖會導緻其他處理器都阻斷了和記憶體之間的互動,是以開銷是非常大的。
緩存行鎖定即在處理器内部進行鎖定。我們知道,每個處理器内部有L1,L2緩存,屬于每個處理器獨享,緩存行所在的記憶體區域,會在lock期間被鎖定,并且通過緩存一緻性協定來保證其他處理器無法操作該資料對應的緩存行,因為緩存一緻性機制會阻止同時修改被兩個以上處理器緩存的記憶體區域資料,當其他處理器回寫已被鎖定的緩存行的資料時會起緩存行無效,即當cpu1中修改i鎖定了記憶體中i對應的緩存行,cpu2就緩存i的緩存行,使用緩存行相比總線鎖定,大大降低處理器之間的開銷。
不過緩存行鎖定也有不能使用的時候:
不能跨緩存行鎖定,如果處理器操作的資料跨多個緩存行,那就隻能使用總線鎖定
如果是早期的處理器,不支援緩存行鎖定也會直接使用總線鎖定
我麼可以看到,通過這兩種機制,處理器會保證對一個變量的讀-改-寫保證原子操作,回到Unsafe.compareAndSwapObject()這個方法上來,那這個方法的執行是可以保證原子性的。
我們常用的Atomic*系列原子類,底層也就是通過Unsafe來操作的,可以舉個例子,AtomicInteger,看下這個類的幾個api
ABA問題,可以類比我們常用的資料庫的操作,我們在更新一些敏感字段的時候,如果是多線程操作,不加分布式鎖或者其他處理的話,會存在丢失更新的問題,我們平常的處理都會加樂觀鎖,也可以通過分布式鎖去處理,那其實在jdk也為我們提供了這樣類似的方式:AtomicStampedReference
循環問題,如果一直不成功的話,會極大的占用cpu資源.看下unsafe中的實作:
如果JVM能支援處理器提供的pause指令那麼效率會有一定的提升,pause指令有兩個作用,第一它可以延遲流水線執行指令(de-pipeline),使CPU不會消耗過多的執行資源,延遲的時間取決于具體實作的版本,在一些處理器上延遲時間是零。第二它可以避免在退出循環的時候因記憶體順序沖突(memory order violation)而引起CPU流水線被清空(CPU pipeline flush),進而提高CPU的執行效率.
提起synchronized這個鎖,總是不太敢在程式中用,這個一直給人的印象就是一個重量級鎖,使用的時候必定得帶着性能的考量,能不用鎖就一定不用,用的話也會優先級考慮Lock,其實jdk已經對這個鎖的實作有了很多的優化,并沒有想象中的那麼重量級,jdk的優化主要展現在引入了“偏向鎖”和“輕量級鎖”的概念。下面我們詳細了解下
我們知道代碼中同步主要分為三種情況:
同步普通方法,鎖的是執行個體對象
同步靜态方法,鎖的是class對象
同步代碼塊,鎖的是synchronized裡面的對象
而對于代碼塊的同步,我們可以通過反編譯代碼看出來,是通過monitorenter和monitorexit來實作的,而對于同步方法,是通過在方法聲明處辨別ACC_SYNCHRONIZED
javac SynchronizedTest.java之後,再javap -c SynchronizedTest 如下結果:
其中兩個monitorexit分别插在代碼塊的結束處和發生異常的位置。jvm規範規定,代碼在執行到這兩個指令的時候會去檢查下鎖的狀态,如果鎖目前的狀态為空或者目前線程已經擁有該鎖了,那鎖計數器會加1,并且直接進入代碼塊,否則需要阻塞目前線程。那麼為什麼這個過程會很重呢?是因為java中的線程都會直接映射到作業系統原生的線程之上的,對于線上的阻塞和喚醒狀态的操作,需要系統從使用者态轉換到核心态在進行執行,這個過程是非常消耗處理器資源的。有可能都會出現使用者代碼執行的時間都比這個狀态切換的少。是以在jdk1.6出現了多鎖的優化,分别有偏向鎖,輕量級鎖。
jvm中把對象分為兩部分,第一部分存儲對象本身運作時的資料,如hashcode,gc分代年齡,鎖标志位等這部分成為markword,另一部分是指向目前對象的在方法區的類型資料的指針。對象頭中存儲的資料在運作時會根據對象的狀态發生變化
mark word
鎖标志位
代表鎖狀态
對象哈希碼、對象分代年齡
01
未鎖定
指向鎖記錄的指針
00
輕量級鎖定
指向重量級鎖的指針
10
膨脹(重量級鎖定)
空,不需要記錄資訊
11
GC标記
偏向線程ID、偏向時間戳、對象分代年齡
可偏向
偏向鎖主要用在同步塊隻有單線程在執行的時候,這種情況,當線程進入同步快的時候,判斷下對象頭是否是為鎖定狀态,以及偏向狀态是否設定為1,如果是,通過CAS将mark word設定為目前線程的thread id,如果成功直接執行代碼塊。如果失敗需要判斷下mark word中标記的線程id是否是目前線程,如果是的話,直接執行代碼塊,否則,說明有競争,需要撤銷偏向,将可偏向狀态設為0,mark word設為空,這個時候就需要更新到輕量級鎖的流程。
線程在擷取鎖之前,會在其棧幀建立一份存儲鎖記錄的空間lock record,如下圖:
并将對象頭中的Mark Word複制到lock record中。然後線程嘗試使用CAS将對象頭中的Mark Word替換為指向lock record的指針,并修改mark word中所得狀态。
如果成功,目前線程獲得鎖,如果失敗,表示其他線程競争鎖,目前線程便嘗試使用自旋來擷取鎖。如果自旋失敗,鎖需要繼續更新為重量級鎖,這個時候需要阻塞自己。
線程需要通過CAS将lock record中複制到的對象頭和mark word中的lock record指針進行替換,如果替換成功,鎖釋放成功,如果失敗,說明有其他線程試圖擷取鎖,需要釋放鎖之後喚醒其他線程。
LockSupport.park()/unpark()可以實作挂起一個線程和喚醒線程,我們簡單看下一個使用的demo:
執行結果:
其實對于unpark()來說,就是給指定線程釋放一個許可,park()就是擷取線程的一個許可,如果沒有即阻塞。LockSupport和每個使用它的線程都與一個許可(permit)關聯。permit相當于1,0的開關,預設是0,調用一次unpark就加1變成1,調用一次park會消費permit, 也就是将1變成0,同時park立即傳回。再次調用park會變成block(因為permit為0了,會阻塞在這裡,直到permit變為1), 這時調用unpark會把permit置為1。每個線程都有一個相關的permit, permit最多隻有一個,重複調用unpark也不會積累。
LockSupport還提供了一個帶參數的park()方法:
強烈建議使用這個帶參數的park方法!還是上面的demo<我們看一個參數和不帶參數的線程dump的差別:
我們可以看出來,使用帶參數的park(Object blocker)方法,線上程堆棧中,可以看到更多的資訊,以幫助我們去分析線程阻塞的原因。
在使用wait/notify的時候,首先我們同構notify沒法保證要讓哪個線程去競争鎖,因為這個方法隻會在等待的隊列中随機選一個線程去喚醒,是以可能我們更多的都是通過notifyAll來喚醒所有的線程,所有的線程都喚醒了,無疑又增大了鎖的競争,又會出現大批線程的狀态的切換,而通過LockSupport.unpark(Thread t) 我們可以有針對的去指定要讓哪個線程喚醒,這讓我們的應用更具有可控性,同時也避免了大量線程同時去競争鎖的資源消耗。
notify/notifyAll必須在wait之後調用,如果在wait之前調用了,可能會出現線程一直被阻塞,無法喚醒的狀态。而unpark/park 無需關心次序,調用一次unpark()就是給了一次許可,調用park就是擷取了這個許可,是以在使用上park/unpark 更友善些。
執行結果,隻有調用了notify,主線程才可以被喚醒:
LockSupport用到的成員變量不多,就兩個,其他的都是内部的UNFAFE要用的:
parkBlockerOffset這個變量看着就熟悉了,剛剛我們看到的可以記錄線程被誰阻塞的,給監控工具和線程堆棧提供可用的分析資訊,我們可以通過api來擷取這個blocker
而這個parkBlockerOffset對應的屬性其實是在Thread源碼裡面定義的parkBlocker成員變量
即我們調用LockSupport的park/unpark方法的時候,也會線上程裡面通過setBlocker來設定這個parkBlocker
這裡可能會有人有個疑問,為什麼給線程的變量設定一個值還得用到unsafe來擷取到線程類的屬性然後再去設定這麼麻煩,直接通過get/set方法設定不就得了?
這裡是因為parkBlocker就是線上程處于阻塞的狀态的時候去設定的,而線程處于阻塞的狀态,我們調用線程内部的任何方法,線程是不會響應的,是以需要去通過這種方式來擷取。
其他的api都比較簡單,這裡就不一一多說了。
我們已經分别介紹了在J.U.C中常用的并發工具類的使用以及原理,這些都是我們在并發中常用的一些操作,同時為後面鎖的分析打入一些基礎,下篇文章我們來看下Lock
<a href="https://www.cnblogs.com/suxuan/p/4948608.html">https://www.cnblogs.com/suxuan/p/4948608.html</a>
<a href="https://www.cnblogs.com/mickole/articles/3757278.html">https://www.cnblogs.com/mickole/articles/3757278.html</a>
<a href="http://icyfenix.iteye.com/blog/1018932">http://icyfenix.iteye.com/blog/1018932</a>
<a href="http://www.infoq.com/cn/articles/java-se-16-synchronized">http://www.infoq.com/cn/articles/java-se-16-synchronized</a>
<a href="https://www.jianshu.com/p/19f861ab749e">https://www.jianshu.com/p/19f861ab749e</a>
<a href="http://blog.csdn.net/q262800095/article/details/48178847">http://blog.csdn.net/q262800095/article/details/48178847</a>
<a href="http://blog.csdn.net/chen77716/article/details/6618779">http://blog.csdn.net/chen77716/article/details/6618779</a>
<a href="http://blog.csdn.net/liu88010988/article/details/50799978">http://blog.csdn.net/liu88010988/article/details/50799978</a>
<a href="https://segmentfault.com/a/1190000008420938">https://segmentfault.com/a/1190000008420938</a>