QL Server 2008 改進了許多并行計劃的已分區表的查詢處理性能,更改了并行和串行計劃的表示方式,增強了編譯時和運作時執行計劃中所提供的分區資訊。本主題将說明這些改進并提供有關如何解釋已分區表和索引的查詢執行計劃的指南,此外還将提供改進已分區對象的查詢性能的最佳方法。
注意
隻有 SQL Server Enterprise Edition、Developer Edition 和 Evaluation Edition 支援已分區表和已分區索引。
<a href="http://msdn.microsoft.com/zh-cn/library/ms345599.aspx"> 新增的可識别分區的查找操作</a>
<a></a>
在 SQL Server 2008 中,已分區表的内部表示形式已發生變化,即已分區表将作為一個多列索引呈現給查詢處理器,其中 PartitionID 是第一列。PartitionID 是一個隐藏的計算列,用于在内部表示包含特定行的分區的 ID。例如,假設一個定義為 T(a, b, c) 的表 T 在 a 列進行了分區,并在 b 列的聚集索引。在 SQL Server 2008 中,此分區表在内部被視為一個具有架構 T(PartitionID, a, b, c) 的未分區表,并具有組合鍵 (PartitionID, b) 的聚集索引。這樣查詢優化器便可以基于 PartitionID 對任何已分區表或索引執行查找操作。
現在,分區的排除任務已在此查找操作中完成。
此外,查詢優化器的功能也得以擴充,可以針對 PartitionID(作為邏輯首列)以及其他可能的索引鍵列執行某一條件下的查找或掃描操作,然後,對于符合第一級查找操作的條件的每個不同值,再針對一個或多個其他列執行不同條件下的二級查找。也就是說,這種稱為“跳躍掃描”的操作允許查詢優化器基于某一條件來執行查找或掃描操作以确定要通路的分區,然後在該運算符内執行一個二級索引查找操作以傳回這些分區中符合另一個不同條件的行。例如,請考慮以下查詢。
SELECT * FROM T WHERE a < 10 and b = 2;
對于本示例,假設定義為 T(a, b, c) 的表 T 對 a 列進行了分區,并具有 b 的聚集索引。表 T 的分區邊界由以下分區函數定義:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
為求解該查詢,查詢處理器将執行第一級查找操作以查找包含符合條件 T.a < 10 的行的每個分區。這将辨別要通路的分區。然後,在所辨別的每個分區内,處理器将針對 b 列的聚集索引執行一個二級查找以查找符合條件 T.b = 2 和 T.a < 10 的行。
下圖所示為跳躍掃描操作的邏輯表示形式,其中顯示了在 a 列和 b 列中包含資料的表 T。分區編号為 1 到 4,分區邊界由垂直虛線表示。對分區執行的第一級查找操作(圖中未顯示)已确定分區 1、2 和 3 符合查找條件(由為該表定義的分區和 a 列的謂詞訓示),即 T.a < 10。曲線訓示了跳躍掃描操作的二級查找部分所周遊的路徑。實際上,跳躍掃描操作将在這些分區的每個分區中查找符合條件 b = 2 的行。跳躍掃描操作的總開銷等于三個單獨索引查找之和。
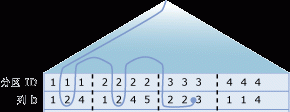
<a href="http://msdn.microsoft.com/zh-cn/library/ms345599.aspx"> 顯示查詢執行計劃中的分區資訊</a>
若要檢查已分區表和索引的查詢執行計劃,可以使用 Transact-SQL SET 語句 SET SHOWPLAN_XML 或 SET STATISTICS XML,或者使用 SQL Server Management Studio 中的圖形執行計劃輸出。例如,單擊查詢編輯器工具欄上的“顯示估計的執行計劃”可以顯示編譯時執行計劃,單擊“包括實際的執行計劃”可以顯示運作時計劃。
使用這些工具,您可以确定以下資訊:
通路已分區表或索引的操作,例如掃描、查找、插入、更新、合并和删除。
查詢通路的分區。例如,運作時執行計劃中包含所通路分區的總計數以及所通路的連續分區的範圍。
何時在查找或掃描操作中使用跳躍掃描操作以便從一個或多個分區中檢索資料。
SQL Server 2008 為編譯時執行計劃和運作時執行計劃都提供了增強的分區資訊。現在,執行計劃可以提供以下資訊:
可選的 Partitioned 屬性,它訓示對某已分區表執行的某個運算符,例如 seek、scan、insert、update、merge 或 delete。
新增的 SeekPredicateNew 元素,它帶有 SeekKeys 子元素,其中包含 PartitionID(作為第一個索引鍵列)和篩選條件(指定針對PartitionID 的查找範圍)。如果存在兩個 SeekKeys 子元素,則表明對 PartitionID 使用了跳躍掃描操作。
用于提供所通路分區的總計的摘要資訊。隻有在運作時計劃中才有此資訊。
為說明此資訊在圖形執行計劃輸出和 XML 顯示計劃輸出中的顯示方式,請考慮對已分區表 fact_sales 的以下查詢。此查詢将更新兩個分區中的資料。
UPDATE fact_sales
SET quantity = quantity * 2
WHERE date_id BETWEEN 20080802 AND 20080902;
下圖顯示了此查詢的編譯時執行計劃中的 Clustered Index Seek 運算符的屬性。若要檢視 fact_sales 表的定義和分區定義,請參閱本主題中的“示例”部分。

對已分區表或索引執行某個運算符(例如 Index Seek)時,Partitioned 屬性将出現在編譯時和運作時計劃中并設為 True (1)。設為 False (0) 時将不會顯示該屬性。
Partitioned 屬性可以出現在以下實體和邏輯運算符中:
Table Scan
Index Scan
Index Seek
Insert
Update
Delete
Merge
如上圖所示,該屬性顯示在包含其定義的運算符的屬性中。在 XML 顯示計劃輸出中,該屬性在包含其定義的運算符的 RelOp 節點中顯示為Partitioned="1"。
在 XML 顯示計劃輸出中,SeekPredicateNew 元素出現在包含其定義的運算符中。它最多可以包含兩個 SeekKeys 子元素執行個體。第一個SeekKeys 執行個體項指定位于邏輯索引的分區 ID 級别的第一級查找操作。也就是說,該查找操作将确定為滿足查詢條件而必須通路的分區。第二個 SeekKeys 執行個體項指定在第一級查找中所辨別的每個分區中進行的跳躍掃描操作的二級查找部分。
在運作時執行計劃中,分區摘要資訊提供了所通路分區的計數以及所通路的實際分區的辨別。您可以使用此資訊來驗證查詢中所通路的分區是否正确以及所有其他分區是否均排除在外。
所提供的資訊包括以下内容:“實際分區計數”和“通路的分區”。
“實際分區計數”是查詢所通路的分區總數。
在 XML 顯示計劃輸出中,“通路的分區”分區摘要資訊顯示在新的 RuntimePartitionSummary 元素中,此元素則位于包含該元素定義的運算符的 RelOp 節點下。下面的示例顯示了 RuntimePartitionSummary 元素的内容,它表明共通路了兩個分區(分區 2 和 3)。
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2">
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
顯示計劃方法 SHOWPLAN_ALL、SHOWPLAN_TEXT 和 STATISTICS PROFILE 并不報告本主題中所述的分區資訊,但以下情況例外。作為 SEEK謂詞的一部分,要通路的分區由表示該分區 ID 的計算列的範圍謂詞辨別。下面的示例顯示了 Clustered Index Seek 運算符的 SEEK 謂詞。通路的分區是分區 2 和 3,并且該查找運算符将篩選符合條件 date_id BETWEEN 20080802 AND 20080902 的行。
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] <= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
<a href="http://msdn.microsoft.com/zh-cn/library/ms345599.aspx"> 解釋已分區堆的執行計劃</a>
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
<a href="http://msdn.microsoft.com/zh-cn/library/ms345599.aspx"> 解釋歸置聯接的執行計劃</a>
使用相同或等效的分區函數對兩個表進行分區并且在查詢的聯接條件中指定了來自聯接兩側的分區依據列時就會發生聯接歸置。查詢優化器可以生成一個計劃,其中具有相等分區 ID 的每個表的分區将分别聯接在一起。歸置聯接可能比非歸置聯接的執行速度快,因為前者可以隻需較少的記憶體和處理時間。優化器會基于成本估計來選擇非歸置計劃或歸置計劃。
在歸置計劃中,Nested Loops 聯接從内側讀取一個或多個聯接表或索引分區。Constant Scan 運算符内的數字表示分區号。
下圖顯示了一個歸置聯接的并行查詢計劃。
<a href="http://msdn.microsoft.com/zh-cn/library/ms345599.aspx"> 已分區對象的并行查詢執行政策</a>
查詢處理器對從已分區對象選擇的查詢使用查詢執行政策。作為執行政策的一部分,查詢處理器會确定查詢所需的表分區,以及要配置設定給每個分區的線程比例。在大多數情況下,查詢處理器會為每個分區配置設定數量相等或幾乎相等的線程,然後在這些分區中并行地執行查詢。以下幾段更詳細地介紹了線程配置設定情況。
如果線程數小于分區數,則查詢處理器會将每個線程配置設定給一個不同的分區,最初會有一個或多個分區沒有獲得配置設定的線程。當線程完成在一個分區上的執行時,查詢處理器會将它配置設定給下一個分區,直到每個分區都配置設定有一個線程。這是查詢處理器将線程重新配置設定給其他分區的唯一情況。
如果線程數與分區數相等,則查詢處理器會為每個分區配置設定一個線程。當線程完成時,不會重新配置設定給另一個分區。
如果線程數大于分區數,則查詢處理器會為每個分區配置設定相等數量的線程。如果線程數并非恰好是分區數的倍數,則查詢處理器會為某些分區額外配置設定一個線程,以使用所有可用線程。請注意,如果隻有一個分區,則會将所有線程都配置設定給該分區。在下圖中,有四個分區和 14 個線程。每個分區都配置設定有 3 個線程,兩個分區具有一個額外的線程,總共配置設定了 14 個線程。當線程完成時,不會重新配置設定給另一個分區。
盡管以上示例指出了一種配置設定線程的簡單方式,但實際政策要複雜一些,并需要考慮在查詢執行過程中出現的其他變化因素。例如,如果表已分區,并在 A 列上有一個聚集索引,并且查詢有謂詞子句 WHERE A IN (13, 17, 25),則查詢處理器将為這三個查找值(A=13、A=17 和A=25))各配置設定一個或多個線程,而不是為每個表分區配置設定一個或多個線程。隻需在包含這些值的分區中執行查詢,并且如果所有這些查找謂詞都恰好在同一個表分區中,則所有線程都将配置設定給同一個表分區。
為了舉出另一個示例,假定表在 A 列上有四個分區(邊界點為 (10, 20, 30)),在 B 列上有一個索引,并且查詢有一個謂詞子句 WHERE B IN (50, 100, 150)。因為表分區是基于值 A,是以值 B 可以出現在任何表分區中。這樣,查詢處理器将分别在四個表分區中查找三個 B 值 (50, 100, 150) 中的每一個值。查詢處理器将按比例配置設定線程,以便它可以并行執行 12 個查詢掃描中的每一個掃描。
基于 A 列的表分區
在每個表分區中查找 B 列
表分區 1:A < 10
B=50, B=100, B=150
表分區 2:A >= 10 AND A < 20
表分區 3:A >= 20 AND A < 30
表分區 4:A >= 30
<a href="http://msdn.microsoft.com/zh-cn/library/ms345599.aspx"> 最佳做法</a>
為提高通路來自大型已分區表和索引的大量資料的查詢性能,我們建議采用以下最佳方法:
跨越許多磁盤建立各個條帶化分區。
盡可能使用具有足夠主記憶體的伺服器以便在記憶體中保留頻繁通路的分區或所有分區,以減少 I/O 開銷。
如果記憶體容納不下所查詢的資料,請壓縮表和索引。這會減少 I/O 開銷。
使用具有快速處理器的伺服器以及盡可能多的處理器核,以充分利用并行查詢處理能力。
確定伺服器具有足夠的 I/O 控制器帶寬。
對每個大型已分區表建立聚集索引,以充分利用 B 樹掃描優化。
<a href="http://msdn.microsoft.com/zh-cn/library/ms345599.aspx"> 示例</a>
下面的示例建立一個測試資料庫,其中包含一個帶有七個分區的表。執行本示例中的查詢時請使用前面所述的工具以檢視編譯時計劃和運作時計劃的分區資訊。
本示例要向表中插入超過 100 萬行資料。根據您的硬體情況,運作本示例可能需要幾分鐘時間。在執行本示例之前,請確定您有超過 1.5 GB 的可用磁盤空間。