AG的性能的性能方面,在關鍵任務資料庫上進行語句級維護性能是很重要的。了解AG如何傳輸日志到secondary副本對評估RTO和RPO,表明AG是否性能不好。
為了評估是否有性能問題,首先需要了解同步過程。性能問題可能出現在同步過程的任何一個環節,瓶頸的定位可以讓你深入的了解問題。以下圖示示範了資料通過過程:
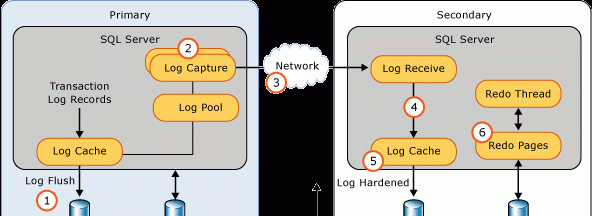
Sequence
Step Description
Comments
Useful Metrics
1
Log Generation
日志資料被重新整理到磁盤。日志必須被複制到secondary副本。日志記錄進入到發送隊列.
<a href="https://msdn.microsoft.com/zh-cn/library/ms189883(v=sql.110).aspx">SQL Server:Database > Log bytes flushed\sec</a>
2
Capture
每個資料庫的日志被擷取并且發送到相關的partner隊列,每個資料庫副本都有一個隊列。在可用組在連接配接的情況下,并且資料移動并沒有被挂起,擷取程序持續運作,并且資料庫副本顯示要不是同步的,要不是正在同步,如果擷取程序不能及時掃描并把消息放入隊列,日志發送隊列就會築高。
3
Send
資料庫副本中的消息出隊列,并且發送到相關的secondary副本.
4
Receive and Cache
每個secondary副本接受并且緩存這些資訊.
5
Harden
日志在secondary副本被重新整理。在日志重新整理後,一個通知被發送到primary副本。一旦日志被固化,就表示不會再有資料丢失。
6
Redo
Redo重新整理secondary副本中的page。Page被存放在redo隊列等待被redo完成。
<a href="https://msdn.microsoft.com/zh-cn/library/ff878356(v=sql.110).aspx">SQL Server:Database Replica > Redone Bytes/sec</a>
AG被設計時,在primary副本上帶了流量控制,為了避免太多資源消耗,比如網絡,記憶體資源在所有可用副本上的消耗。這些流量控制不會影響可用副本的健康狀态,但是會影響可用資料庫性能,包括RPO。
日志被primary副本捕獲之後,有2個級别的流量控制。
Level
Number of Gates
Number of messages
Transport
1 per availabiltiy replica
8192
Extended event database_transport_flow_control_action
Database
1 per availability database
11200 (x64)
1600 (x86)
<a href="https://msdn.microsoft.com/zh-cn/library/ms179984(v=sql.110).aspx">DBMIRROR_SEND</a>
Extended event hadron_database_flow_control_action
一旦到達任意一個閥值,log資訊就不會被發送到指定副本或者指定資料庫。一旦從副本收到通知,已發送的消息下降,就可以再發。
除了流量控制,還有一個因素會阻止日志發送。副本的同步要保證LSN是順序的被發送的。在日志被發送之前,日志的LSN會通過最小通知LSN檢查,保證小于閥值。如果2個LSN的空隙大于閥值,消息就不會被發送。一旦空隙小于閥值,消息就會被發送。
故障轉移時間的公式如下:

如果AG有多個可用庫,最高的故障轉移時間變長了限制RTO總要因素。
Tdetection錯誤診斷時間,是用來發現系統錯誤的時間。這個時間依賴于叢集設定級别,而不是個别可用性副本的設定。根據設定的自動故障轉移的條件,故障轉移在SQL
Secondary副本唯一要做的事情就是,redo這些擷取的日志。Redo時間是Tredo,公式如下:
Redo_queue是redo隊列的長度,redo_rate是redo的速度。這2個值可以檢視:sys.dm_hadr_database_replica_states
Toverhead
over head的時間就是WSFC叢集故障轉移,資料庫online的時間。通常這個時間都很小。
RPO,RPO的公司如下:
如果AG包含了多個可用性資料庫,最大的 Tdata_loss
會變成限制RPO的關鍵。
Log發送隊清單示所有資料會因為嚴重錯誤丢失的。不能使用log_send_rate來代替log生成速度,因為RPO評估資料丢失是基于日志生成速度的,而不是基于同步速度的。
最簡單的評估 Tdata_loss 是使用last_commit_time.priamry會把這個值發給所有的secondary,你可以計算primary副本和secondary 副本的值的差,來評估需要多久secondary副本可以追上primary副本。雖然不能準确的表示資料丢失,但是已經很接近了。
本章介紹如何對RPO和RTO進行監控,RPO和RTO的計算請檢視上面2節的介紹。你可以監控這2個值,在超過閥值時發送告警。
通過以下步驟建立AG的告警:
1.啟動ageng服務
2.點開ALwaysOn啟動使用者定義AlwaysOn政策
3.建立條件, Database Replica State/ Add(@EstimatedRecoveryTime,
60) <= 600
4.建立條件 Database Replica State/EstimatedDataLoss<=3600
5.建立RTO政策,建立RPO政策
Scenario
Description
<a href="http://www.cnblogs.com/Amaranthus/p/4981217.html">排查:AG超過RTO</a>
自動或者手動故障轉移後,沒有資料丢失,但是故障轉移超過了RTO。或者評估發現故障轉移時間超過了
<a href="http://www.cnblogs.com/Amaranthus/p/4981484.html">排查:AG超過RPO</a>
強制故障轉移後,都是的資料超過了RPO。或者異步送出的replica能夠承受的資料丢失超過了RPO。
<a href="http://www.cnblogs.com/Amaranthus/p/4982563.html">排查:Primary上的修改無法在Secondary展現</a>
用戶端程式可以成功的完成primary的修改,但是查詢replia卻沒有反應。
以下擴充時間可以用來排查副本在同步中的情況:
Event Name
Category
Channel
Availability Replica
redo_caught_up
transactions
Debug
Secondary
redo_worker_entry
hadr_transport_dump_message
alwayson
Primary
hadr_worker_pool_task
hadr_dump_primary_progress
hadr_dump_log_progress
hadr_undo_of_redo_log_scan
Analytic