本文示範如何在E-MapReduce上部署Storm叢集和Kafka叢集,并運作Storm作業消費Kafka資料。
這裡我選擇在杭州Region進行測試,版本選擇EMR-3.8.0,本次測試需要的元件版本有:
Kafka:2.11_1.0.0
Storm: 1.0.1
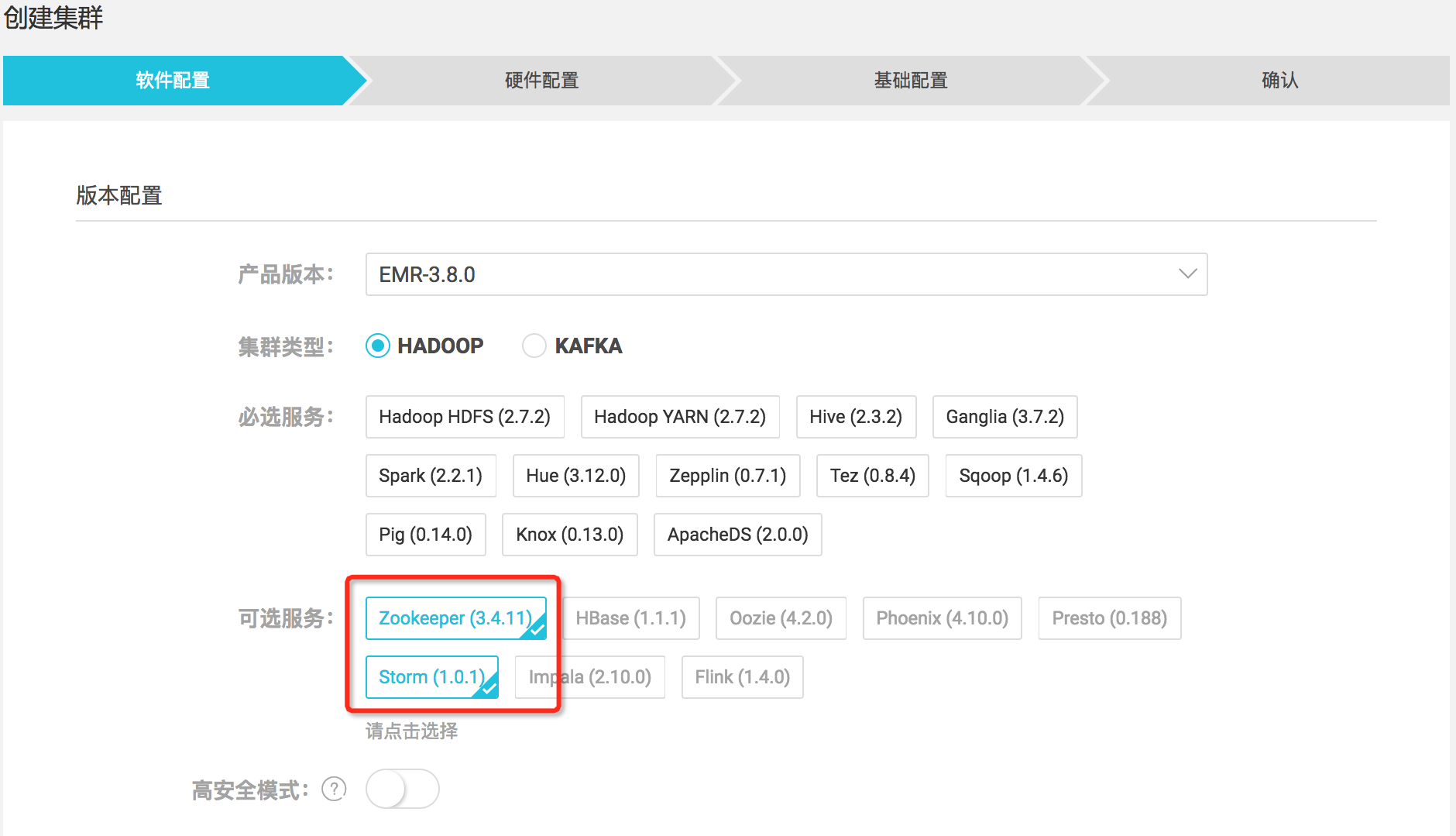
由于Zookeeper和Storm元件預設不是必選的,是以在建立叢集時需要記得勾選上,如下:
接着建立Kafka叢集,叢集類型選擇Kafka,如下:

注意:
如果使用經典網絡,請注意将Hadoop叢集和Kafka叢集放置在同一個安全組下面,這樣可以省去配置安全組,避免網絡不通的問題。
如果使用VPC網絡,請注意将Hadoop叢集和Kafka叢集放置在同一個VPC/VSwitch以及安全組下面,這樣同樣省去配置網路和安全組,避免網絡不通。
如果你熟悉ECS的網絡和安全組,可以按需配置。
如果我們想在Storm上運作作業消費Kafka的話,叢集初始環境下是會失敗的,因為Storm運作環境缺少了不少必須的依賴包,如下:
以上版本依賴包經過測試可用,如果你再測試過程中引入了其他依賴,也一同添加在Storm lib中,如下操作:
上述操作需要在Kafka叢集的每台機器執行一遍。執行完在E-MapReduce控制台重新開機Storm服務,如下:
檢視操作曆史,待Storm重新開機完畢:
E-MapReduce已經提供了現成的示例代碼,直接使用即可,位址如下:
我們一般隻要使用e-mapreduce-demo即可:
登入到Kafka叢集,按照如下步驟建立topic并準備一些資料:
以上指令在kafka叢集的emr-header-1節點執行,當然也可以用戶端機器上執行。
登入到Hadoop叢集,将第二步中編譯得到的examples-1.1-shaded.jar拷貝到叢集emr-header-1上,這裡我放在root根目錄下面。送出作業:
檢視叢集上服務的WebUI有2種方式:
再向kafka寫120條資料
檢視HDFS檔案輸出
至此,我們成功實作了在E-MapReduce上部署一套Storm叢集和一套Kafka叢集,并運作Storm作業消費Kafka資料。當然,E-MapReduce也支援Spark Streaming和Flink元件,同樣可以友善在Hadoop叢集上運作,處理Kafka資料。
有一點需要注意:由于E-MapReduce沒有單獨的Storm叢集類别,是以我們是建立的Hadoop叢集,并安裝了Storm元件。如果你在使用過程中用不到其他元件,可以很友善地在E-MapReduce管理控制台将那些元件停掉。這樣,可以将Hadoop叢集作為一個純粹的Storm叢集使用。