主要内容:
Kafka概述
Kafka叢集部署
Kafka與Flume比較
6.1 Kafka概述
6.1.1 消息隊列
消息系統負責将資料從一個應用程式傳輸到另一個應用程式,是以應用程式可以專注于資料本身,而不用擔心如何共享它。
消息系統有兩種消息模式可用
點對點消息系統
釋出 - 訂閱(pub-sub)消息系統
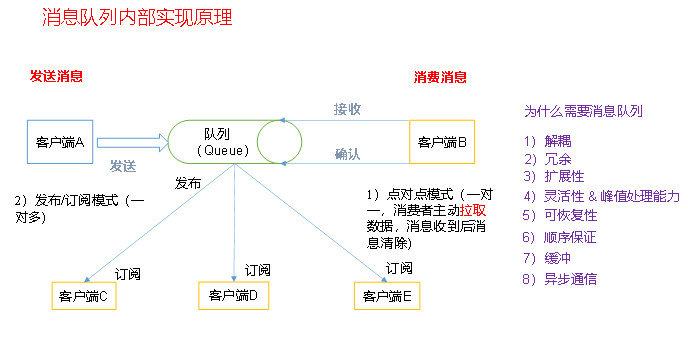
(1)點對點模式(一對一,消費者主動拉取資料,消息收到後消息清除)
點對點模型通常是一個基于拉取或者輪詢的消息傳送模型,這種模型從隊列中請求資訊,而不是将消息推送到用戶端。這個模型的特點是發送到隊列的消息被一個且隻有一個接收者接收處理,即使有多個消息監聽者也是如此。
(2)釋出/訂閱模式(一對多)
釋出訂閱模型則是另一個消息傳送模型。釋出訂閱模型可以有多種不同的訂閱者,臨時訂閱者隻在主動監聽主題時才接收消息,而持久訂閱者則監聽主題的所有消息,即使目前訂閱者不可用,處于離線狀态。
6.1.2 為什麼需要消息隊列
1)解耦:
允許你獨立的擴充或修改兩邊的處理過程,隻要確定它們遵守同樣的接口限制。
2)備援:
消息隊列把資料進行持久化直到它們已經被完全處理,通過這一方式規避了資料丢失風險。許多消息隊列所采用的"插入-擷取-删除"範式中,在把一個消息從隊列中删除之前,需要你的處理系統明确的指出該消息已經被處理完畢,進而確定你的資料被安全的儲存直到你使用完畢。
3)擴充性:
因為消息隊列解耦了你的處理過程,是以增大消息入隊和處理的頻率是很容易的,隻要另外增加處理過程即可。
4)靈活性 & 峰值處理能力:
在通路量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量并不常見。如果為以能處理這類峰值通路為标準來投入資源随時待命無疑是巨大的浪費。使用消息隊列能夠使關鍵元件頂住突發的通路壓力,而不會因為突發的超負荷的請求而完全崩潰。
5)可恢複性:
系統的一部分元件失效時,不會影響到整個系統。消息隊列降低了程序間的耦合度,是以即使一個處理消息的程序挂掉,加入隊列中的消息仍然可以在系統恢複後被處理。
6)順序保證:
在大多使用場景下,資料處理的順序都很重要。大部分消息隊列本來就是排序的,并且能保證資料會按照特定的順序來處理。(Kafka保證一個Partition内的消息的有序性)
7)緩沖:
有助于控制和優化資料流經過系統的速度,解決生産消息和消費消息的處理速度不一緻的情況。
8)異步通信:
很多時候,使用者不想也不需要立即處理消息。消息隊列提供了異步處理機制,允許使用者把一個消息放入隊列,但并不立即處理它。想向隊列中放入多少消息就放多少,然後在需要的時候再去處理它們。
6.1.3 什麼是Kafka
在流式計算中,Kafka一般用來緩存資料,Spark通過消費Kafka的資料進行計算。
1)Apache Kafka是一個開源消息系統,由Scala寫成。是由Apache軟體基金會開發的一個開源消息系統項目。
2)Kafka最初是由LinkedIn公司開發,并于2011年初開源。2012年10月從Apache Incubator畢業。該項目的目标是為處理實時資料提供一個統一、高通量、低等待的平台。
3)Kafka是一個分布式消息隊列。Kafka對消息儲存是根據Topic進行歸類,發送消息者稱為Producer,消息接受者稱為Consumer,此外kafka叢集有多個kafka執行個體組成,每個執行個體(server)稱為broker。
4)無論是kafka叢集,還是consumer都依賴于zookeeper叢集儲存一些meta資訊,來保證系統可用性。
6.1.4 Kafka架

Kafka整體架構圖
Kafka詳細架構圖
1)Producer :消息生産者,就是向kafka broker發消息的用戶端;
2)Consumer :消息消費者,向kafka broker取消息的用戶端;
其中的offset(記錄着下一條将要發送給Consumer的消息的序号)需要存在其他位置,低版本0.9之前将offset儲存在Zookeeper中,0.9及之後儲存在Kafka的“__consumer_offsets”主題中。
3)Topic :可以了解為一個隊列;
4) Consumer Group (CG):這是kafka用來實作一個topic消息的廣播(發給所有的consumer)和單點傳播(發給任意一個consumer)的手段。
一個topic可以有多個CG。topic的消息會複制(不是真的複制,是概念上的)到所有的CG,但每個partion隻會把消息發給該CG中的一個consumer。
如果需要實作廣播,隻要每個consumer有一個獨立的CG就可以了。要實作單點傳播隻要所有的consumer在同一個CG。用CG還可以将consumer進行自由的分組而不需要多次發送消息到不同的topic;
5)Broker :一台kafka伺服器就是一個broker。一個叢集由多個broker組成。一個broker可以容納多個topic;
6)Partition:為了實作擴充性,一個非常大的topic可以分布到多個broker(即伺服器)上,一個topic可以分為多個partition,每個partition是一個有序的隊列。
partition中的每條消息都會被配置設定一個有序的id(offset)。kafka隻保證按一個partition中的順序将消息發給consumer,不保證一個topic的整體(多個partition間)的順序;
6.2 Kafka叢集部署
6.2.1 環境準備
1 叢集規劃
01node 02node 03node
zk zk zk
kafka kafka kafka
2 jar包下載下傳
http://kafka.apache.org/downloads.ht
6.2.2 Kafka叢集部署
1)解壓安裝包,目前案例中使用的是2.4.0版本
2)修改解壓後的檔案名稱
3)修改配置檔案
修改以下内容:
4)配置環境變量
5)分發安裝包
記得重新整理02和03節點的配置檔案
6)分别在02node和03node上修改配置檔案server.properties中的broker.id=1、broker.id=2
注:broker.id不得重複
7)在三個節點上啟動zookeeper叢集
8)啟動kafka叢集
依次在01node、02node、03node節點上啟動kafka
9)關閉叢集
6.2.3 Kafka指令行操作
1)檢視目前伺服器中的所有topic
2)建立topic
選項說明:
--topic 定義topic名
--replication-factor 定義副本數
--partitions 定義分區數
3)删除topic
需要server.properties中設定delete.topic.enable=true否則隻是标記删除或者直接重新開機。
4)發送消息
5)消費消息
--from-beginning:會把主題中以往所有的資料都讀取出來。
6)檢視某個Topic的詳情
6.3 Kafka與Flume比較
在企業中必須要清楚流式資料采集架構flume和kafka的定位是什麼:
flume:cloudera公司研發:
适合多個生産者;
适合下遊資料消費者不多的情況;
适合資料安全性要求不高的操作;
适合與Hadoop生态圈對接的操作。
kafka:linkedin公司研發:
适合資料下遊消費衆多的情況;
适合資料安全性要求較高的操作,支援replication。
是以我們常用的一種模型是:
線上資料 --> flume --> kafka --> flume(根據情景增删該流程) --> HDFS