Horovod 是Uber于2017年釋出的一個易于使用的高性能的分布式訓練架構,在業界得到了廣泛應用。本系列将通過源碼分析來帶領大家了解 Horovod。本文是第十六篇,看看 horovod **彈性訓練**中 worker 的生命周期。
[源碼解析] 深度學習分布式訓練架構 horovod (16) --- 彈性訓練之Worker生命周期
目錄
0x00 摘要
0x01 Worker 是什麼
1.1 角色
1.2 職責
1.3 組網機制
1.3.1 通信環
1.3.2 彈性建構
1.3.2.1 Driver 監控
1.3.2.2 Driver 重新建構
0x02 總體生命流程
0x03 配置過程
0x04 啟動過程
4.1 總體邏輯
4.2 指派
4.3 擷取 host 資訊
4.3.1 更新 host 和 rank
4.3.2 擷取 host 和 rank
4.3.3 拓展邏輯
4.4 啟動
0x05 運作過程
0x06 注冊,結果 & 協調
6.1 Worker 的邏輯層次
6.2 worker 運作階段
6.2.1 進入 C++ 世界
6.2.2 建構 Gloo
6.2.2.1 去 Rendezvous 擷取資訊
6.2.2.2 RendezvousServer
6.2.3 進入READY 狀态
6.3 WorkerStateRegistry
6.3.1 初始化
6.3.2 啟動
6.3.3 worker 結束
6.3.4 進一步控制
6.4 Driver.resume 場景
0xEE 個人資訊
0xFF 參考
Horovod 是Uber于2017年釋出的一個易于使用的高性能的分布式訓練架構,在業界得到了廣泛應用。
本系列将通過源碼分析來帶領大家了解 Horovod。本文是第十六篇,看看 horovod 彈性訓練中 worker 的生命周期。
我們先給出一個邏輯圖,大家先有一個粗略的了解,本圖左側是 Driver 部分,右側是一個 Worker。
本系列其他文章連結如下:
[源碼解析] 深度學習分布式訓練架構 Horovod (1) --- 基礎知識
[源碼解析] 深度學習分布式訓練架構 horovod (2) --- 從使用者角度切入
[源碼解析] 深度學習分布式訓練架構 horovod (3) --- Horovodrun背後做了什麼
[源碼解析] 深度學習分布式訓練架構 horovod (4) --- 網絡基礎 & Driver
[源碼解析] 深度學習分布式訓練架構 horovod (5) --- 融合架構
[源碼解析] 深度學習分布式訓練架構 horovod (6) --- 背景線程架構
[源碼解析] 深度學習分布式訓練架構 horovod (7) --- DistributedOptimizer
[源碼解析] 深度學習分布式訓練架構 horovod (8) --- on spark
[源碼解析] 深度學習分布式訓練架構 horovod (9) --- 啟動 on spark
[源碼解析] 深度學習分布式訓練架構 horovod (10) --- run on spark
[源碼解析] 深度學習分布式訓練架構 horovod (11) --- on spark --- GLOO 方案
[源碼解析] 深度學習分布式訓練架構 horovod (12) --- 彈性訓練總體架構
[源碼解析] 深度學習分布式訓練架構 horovod (13) --- 彈性訓練之 Driver
[源碼解析] 深度學習分布式訓練架構 horovod (14) --- 彈性訓練發現節點 & State
[源碼解析] 深度學習分布式訓練架構 horovod (15) --- 廣播 & 通知
首先,我們要看看 worker 是什麼。為了可以單獨成文,本章節回憶了很多之前的知識,看過之前文章的同學可以跳過。
”訓練“ 是通過計算梯度下降的方式利用資料來疊代地優化神經網絡參數,最終輸出網絡模型的過程。
我們首先要看看彈性訓練中的角色設定。
Horovod 的彈性訓練包含兩個角色,driver 程序和 worker 程序。driver 程序運作在 CPU 節點上,worker 程序可運作在 CPU 或者 GPU 節點上。在 Horovod 中,訓練程序是平等的參與者,每個 worker 程序既負責梯度的分發,也負責具體的梯度計算。
這兩個角色和 Spark 的 Driver -- Executor 依然很類似。Driver 程序就可以認為是 Spark 的 Driver,或者說是 master 節點。Worker 就類似于 Spark 的 Executor。
具體如圖:
角色的職責如下:
master(主節點)職責:
負責實時探活 worker(工作節點)是否有變化,掉線情況;
負責實時監控 host 是否有變化;
負責配置設定任務到存活的worker(工作節點);
在有程序失敗導緻 AllReduce 調用失敗的 情況下,master 通過 blacklist 機制 組織剩下的活着的程序構造一個新的環。
如果有新 host 加入,則生成新的 worker,新 worker 和 舊 worker 一起構造成一個新的環。
worker(工作節點)職責:
負責彙報(其實是被動的,沒有主動機制)目前worker(工作節點)的狀态(就是訓練完成情況);
負責在該worker(工作節點)負責的資料上執行訓練。
Horovod 在單機的多個 GPU 上采用 NCCL 來通信,在多機之間通過 ring-based AllReduce 算法進行通信。
Horovod 的彈性訓練是指多機的彈性訓練。在多機的 ring-based 通信中的每個 worker 節點有一個左鄰和一個右鄰,每個 worker 隻會向它的右鄰居發送資料,并從左鄰居接受資料。
Driver 程序用于幫助 worker 調用 gloo 構造 AllReduce 通信環。
當 Horovod 在調用 Gloo 來構造通信域時,Horovod 需要給 Gloo 建立一個帶有 KVStore 的 RendezvousServer,其中 KVStore 用于存儲 通信域内每個節點的 host 位址 和 給其在邏輯通信環配置設定的序号 rank 等資訊。
建構過程如下:
Driver 程序建立帶有 KVStore 的 RendezvousServer,即這個 RendezvousServer 運作在 Horovod 的 driver 程序裡。
Driver 程序拿到所有 worker 程序節點的 IP 位址和 GPU 卡數資訊後,會将其寫入RendezvousServer 的 KVStore 中。
每個 worker 節點會通過調用 gloo 進而 請求 RendezvousServer 擷取自己的鄰居節點資訊(ip,port...),進而構造通信域。
當有 worker 失敗或者新的 worker 加入訓練時,每個 worker 會停止目前的訓練,記錄目前模型疊代的步數,并嘗試重新初始化 AllReduce 的通信域。
因為 driver 程序一直在監控 worker 的狀态 和 host 節點情況,是以
當 host 變化時候,當驅動程序通過節點發現腳本發現一個節點被标記為新增或者移除時,它将發送一個通知到 所有workers,在下一次 state.commit() 或者更輕量的 state.check_host_updates() 被調用時,會抛出一個 HostsUpdateInterrupt 異常。
當有 worker 失敗時,driver 會重新擷取存活的 worker 的host,
為了不讓其他 worker 程序退出,Horovod 會捕獲 gloo 抛出的異常,并将異常傳遞給封裝的 Python API。進而 driver 會重新配置 RendezvousServer,進而讓 worker 節點能重新構造通信域。是以 Horovod 是可容錯的。
如果有 host 變化,worker 程序可以通過這個 rendezvous 來構造新的通信域。當新的通信域構造成功後,rank=0 的 worker 會将自身的模型廣播給其他 worker,然後接着上次停止的疊代步數開始訓練。
組網機制如下:
是以,本文就看看 Worker 的一個整體生命流程。
在 Driver 的 launch_gloo_elastic 之中,如下代碼負責啟動 worker。
command 就是傳入的可執行指令,比如 python train.py。經過 get_run_command 之後就得到了 env python train.py 之類的樣子,就是加上環境變量,可以運作了。
exec_command 類似如下: exec_command = _exec_command_fn(settings),就是基于各種配置來生成可以執行指令環境。
可以清晰看出來三個詳細的過程(因為 訓練過程是在 worker 内部,是以 driver 分析沒有深入此部分):
_create_elastic_worker_fn 是配置過程;
driver.start 是啟動過程;
driver.get_results 就是得到 & 注冊 運作結果;
我們接下來就按照這三個過程詳細分析一下。
配置過程 是由 _create_elastic_worker_fn 完成,就是提供一個在某個環境下運作某個指令的能力。
_create_elastic_worker_fn 分為兩部分:
_slot_info_to_command_fn 會建立 slot_info_to_command,套路和之前文章中類似,就是把各種 horovod 環境變量和運作指令 run_command 糅合起來,得到一個可以在“某個 host and slot” 之上運作的指令文本;
傳回 create_worker。
create_worker 是利用 exec_command 和 指令文本 建構的函數。
exec_command 我們在之前介紹過,就是提供了一種運作指令的能力,或者說是運作環境;
是以 create_worker 就是提供一個在某個環境下運作某個指令的能力;
是以,最終得到的 create_worker 是:
這樣,create_worker 就直接可以運作訓練代碼了。
create_worker = _create_elastic_worker_fn 提供了一個在某個環境下運作某個指令的能力,因為 create_worker 方法内部已經包括了執行指令和執行環境,就是說,隻要運作create_worker,就可以自動訓練。下面我們就利用這個能力來啟動 worker。
啟動過程基本都是在 ElasticDriver 類 的 start 方法中完成。
以下邏輯都運作在 ElasticDriver 之中。
首先,會把 上面生成的 create_worker 指派給 self._create_worker_fn。
其次,會調用 _activate_workers 啟動多個 worker,其中包括:
先使用 wait_for_available_slots 等待 min_np 數目的可用的 hosts。之前分析過此函數,就是 無限循環等待,如果 avail_slots >= min_np and avail_hosts >= min_hosts 才會傳回。
使用 _update_host_assignments 來得到 slots;
使用 _start_worker_processes 來啟動多個 worker;
下面逐一看看。
第一步就是上面生成的 create_worker 指派給 self._create_worker_fn。
手機如下:

接下來要使用 _update_host_assignments 來得到 slots,具體分為兩步:
首先建構 host 和 rank 之間的配置設定狀況。
其次
_update_host_assignments 函數中會根據 最新的 host 資訊,重新建構 rendezvous,比如:
self._rendezvous.init(host_assignments_list)。
具體邏輯是:
擷取 活躍的slot :active_slots;
擷取 host 配置設定情況;
確定每個 worker 有前驅者,就是可以傳遞狀态,構成環;
調用 self._rendezvous.init 重新構造 rendezvous;
配置設定 rank 和 slot 的關系;
傳回 pending_slots,就是配置設定的slot之中,不在 活躍slot清單 active_slots 中的。不活躍的就是接下來可以啟動 新 worker 的。
其中,host資訊是通過 _get_host_assignments 來完成
_get_host_assignments 調用get_host_assignments具體完成業務。
get_host_assignments 會依據 host 和 process capacities (slots) 來給 Horovod 之中的程序配置設定,即給出一個 horovod rank 和 slot 的對應關系。設定了幾個 np,就有幾個 slot。
給出的配置設定方案類似如下,這樣就知道了哪個rank對應于哪個host上的哪個slot:
代碼如下:
目前拓展邏輯如下,經過 4.2,4.3 兩步之後,ElasticDriver 中的一些變量被指派了,我們簡化了上圖中的 exec_command 如下(第一步在上圖中):
_start_worker_processes 完成了啟動過程,邏輯遞增如下。
create_worker_fn 就是使用 之前指派的 create_worker = exec_command({horovod_env} {env} {run_command}) ;
run_worker() 中 執行 create_worker_fn(slot_info, [shutdown_event, host_event]) 就是 運作訓練代碼;
threading.Thread(target=run_worker) 就是在一個 thread 之中運作訓練代碼;
_start_worker_processes 就是在多個 thread 之中運作多份訓練代碼;
啟動之後,邏輯如下,可以看到,經過 4 步之後,啟動了 count(slot_info)這麼多的 Thread,每個 Thread 之中,有一個 _create_worker_fn 運作在一個 Slot 之上:
運作過程其實在上面已經提到了,就是在 Thread 之中運作 exec_command({horovod_env} {env} {run_command})。這就是調用使用者代碼進行訓練。
這裡要說明的是 self._results = ResultsRecorder() 。具體在其中記錄每一個運作的 Thread。
于是我們的邏輯變成如下,self._results 裡面記錄了所有的 Threads:
本節主要對應架構圖中的下面三部分。
此部分的邏輯層次在後續介紹的 容錯機制之上。容錯機制是在 Worker 内部,此部分是在 Worker 之上。
worker 是在 訓練腳本之上的階段,即 Worker 來運作使用 "python train.py" 來運作訓練腳本。
是以,上圖我們簡化如下:
于是我們提出了新問題如下:
worker 的運作,怎麼才算一個階段?一共有幾個階段(狀态)?
Driver 根據什麼特征來記錄 Worker 的運作結果?
從源碼中我們可以看到,Worker 有三個狀态如下:
是以,Worker 可以分為四個階段,RUNNING 是我自己加上去的,就是運作訓練腳本這個過程,官方沒有這個狀态,但是我覺得這樣應該更清晰。而 SUCCESS 和 FAILURE 就是腳本運作成功與否。
我們接下來看看運作階段。
當 Driver 初始化 / resume(比如收到了HostsUpdateInterrupt ) 時候,就會調用到 hvd.init。
進入 hvd.init 有幾個調用途徑(按照下面1,2,3 順序邏輯進行):
依靠 WorkerStateRegistry . _barrier : 作用是當所有 worker 完成之後,會進一步處理。有三個途徑會觸發這個barrier:
start 一個 worker,worker會 hvd.init,進而調用了 gloo in c++,進而 聯系 rendezvous,rendezvous 通知 driver,進而在 WorkerStateRegistry 設定自己的狀态是 READY,如果達到了 min_np,則會觸發了 _barrier (途徑 1);
新發現一個host,進而導緻觸發一個 HostsUpdateInterrupt,worker 捕獲這個異常之後,進而會 reset,reset 時候會調用 hvd.init,進而和上述一樣,最終觸發_barrier (途徑 2);
worker失敗,會調用會 _handle_worker_exit,進而在 WorkerStateRegistry 設定自己的狀态是 FAILURE,會觸發了 _barrier (途徑 3);
_barrier 繼續執行時候,會調用建構時候設定的 handler,即 _action 函數,進而調用到了 _on_workers_recorded,最終調用到了 self._driver.resume();
resume 函數 會self._activate_workers(self._min_np),最終就是重新生成(也許是部分,根據 pending_slots決定)worker。
前文我們提到過,在 python 世界調用 hvd.init 的時候,會進入到 C++世界,這時候如果編譯了 GLOO,就建立了一個 GlooContext。
GlooContext 就得到了一個與 RendezvousServer 通訊的接口。
從 GlooContext::Initialize 可以知道,需要擷取大量配置資訊,其中最重要的就是 rank 等資訊。
這些資訊是在 RendezvousServer 設定存儲的。是以 GlooContext 會去 RendezvousServer 進行 http 互動,下面代碼還是比較清晰易懂的。
RendezvousServer 對外提供了 GET 方法。
ElasticRendezvousHandler 是 RendezvousServer 的響應handler,其中 ElasticRendezvousHandler._get_rank_and_size 函數是:
這裡會調用到 driver.record_ready,就是通知 Driver,現在有一個 worker 是 READY 狀态。
當調用 hvd.init -----> GlooContext 建立 之後,會與RendezvousServer 通訊,這之後 Worker 就進入到 READY 狀态。
我們需要繼續深化下,看看一個 worker 從開始運作到 READY 狀态 之間都發生了什麼。
Worker 開始調用 python train.py;
在 train.py 之中,調用 hvd.init(),此方法會深入到 C++ 世界,進而生成了 GlooContext;
GlooContext 之中,會從環境變量之中得到 Rendezvous Server 的ip, port,進而調用 init_store 生成一個 HTTPStore;
調用 init_store.get(hostname + ":" + std::to_string(local_rank)) 向 Rendezvous Server 發送請求,要求獲得本worker 的 rank 對應的 各種配置(local_rank, cross_rank...,因為 Rendezvous Server 可能會重新初始化進而重新配置設定);
ElasticRendezvousHandler 是 響應函數,其中會 調用 driver.record_ready(host, local_rank) 進而在 WorkerStateRegistry 的 READY 字典中記錄下來,worker 2 已經是 READY 了。
會調用 driver.get_slot_info(host, local_rank) 從 driver 獲得 slot info;
此時,Worker 的狀态就是 READY(其實 Worker 本身沒有這個狀态,隻是 WorkerStateRegistry 有這個狀态);
ElasticRendezvousHandler 會傳回 slot info 到 worker 的 C++ 世界;
在 worker 的 C++ 世界 之中繼續執行,把 slot info 傳回給 GlooContext,進行各種設定;
具體邏輯圖如下:
至此,Worker 就可以開始運作了。
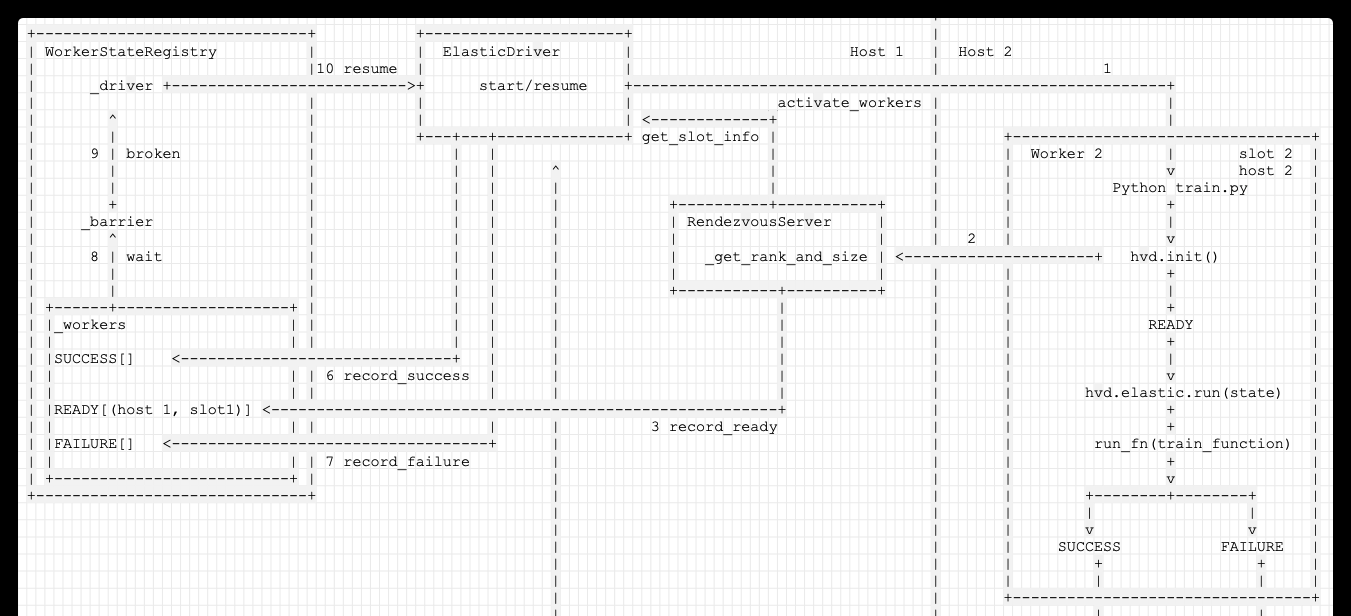
WorkerStateRegistry 的作用是 注冊運作結果,然後進行對應協調。
其主要成員變量是:
_driver :用來聯系 Driver,因為會調用 driver 來做處理;
_host_manager :用來發現 host;
_workers : 紀錄每種狀态的worker,狀态包括:'READY','SUCCESS','FAILURE';
_states : 紀錄 worker 的狀态;
_barrier : 作用是當所有 worker 完成之後,會進一步處理;
具體定義如下:
WorkerStateRegistry 在 Driver 之中 進行初始化,并且把自己設定為 Driver 的一個成員變量,這樣 Driver 就可以友善調用:
在 master 啟動所有 worker 之前,會調用 reset。
reset 函數中有複雜邏輯。
有兩個問題:
為什麼要有 _barrier?原因是:大部分機器學習算法機制是需要當所有 worker(或者若幹worker) 完成之後,才會進一步處理,是以需要等待。
這裡 barrier 的參數 parties 具體數值是 self.world_size(),就是說,隻有等到barrier 内部計數達到 self.world_size() 時候,就會激發 self._action 函數。
每個worker 結束時候,都會調用到 _handle_worker_exit,最終會 self._barrier.wait()。
這樣,當所有 worker 都結束時候,barrier 會激發 self._action 函數。
設定的 _action 起到什麼作用?其作用是:根據本次訓練結果,進一步控制,決定下一步動作;
當 worker 結束時候,會回到 Driver 設定的 _handle_worker_exit。根據 exit_code 來決定是調用 success 函數還是 failure 函數。
進而調用到 WorkerStateRegistry 之中。
而 _record_state 函數會使用 self._workers[state].add(key) 來紀錄狀态,并且調用 _wait。
_wait 會并且調用 self._barrier.wait() 來等待,這是為了等待其他 worker 的資訊,最後一起處理。
_action 函數會在所有worker 結束之後,進行判斷,控制。
_on_workers_recorded 函數會完成控制邏輯。
判斷是否有一個 worker 成功,如果有一個 worker 成功了,就關閉其他process,結束訓練;因為此時所有 worker 都已經運作結束,是以隻要有一個 worker 成功,就可以跳出循環;
如果所有的 worker 都失敗了,就結束訓練;
把失敗的 worker 紀錄到 黑名單;
如果所有的 host 都在黑名單,則結束訓練;
如果已經到了最大重試數目,則結束訓練;
否則調用 _driver.resume() 重新開機訓練,因為已經 commit 了,是以會自動恢複訓練;
具體代碼如下:
resume 的作用 就是 所有都重新來過。
我們之前分析的場景是:一個 worker 從開始運作到 READY 狀态 之間都發生了什麼。
現在,我們加上一個情形:就是當 Driver 在 resume 的時候,發現居然有新節點,随即啟動了一個新 worker 3。
Worker 2 開始調用 python train.py;
把 slot info 傳回給 worker 中的 Http_store;
在 worker 2 之中繼續執行,把 slot info 傳回給 GlooContext,進行各種設定;
我們接着 第 5 項繼續進行;record_ready 之中 會調用 rendezvous_id = self._wait(key, state, rendezvous_id) 來在 WorkerStateRegistry . _barrier 之上等待; _barrier 的類型是threading.Barrier(parties=size, action=self._action) ,
如果 READY 的 worker 數目達到了 Horovod 設定的 min-np,就是可以啟動的最小 worker 數目, _barrier 就結束使命,就 broken,繼續執行;
ElasticDriver 的 resume 函數調用到了 _activate_workers,其定義如下,可以看到,如果此時 discovery 腳本已經發現了新節點,進而傳回了 pending_slots,pending_slots 就是可以在這些 slot 之上啟動新 worker 的,于是 就會 調用 _start_worker_processes:
_start_worker_processes 會開啟一個新的 worker : Worker 3;
Worker 3 也執行 python train.py,至此,新worker啟動完畢;
回到worker 2,如果訓練結束,則會依據訓練結果,傳回 SUCCESS 或者 FAILURE 到 Driver ;
Driver 會調用 _handle_worker_exit 對訓練結果進行處理;
至此,新的邏輯完成。
我們可以擴大部分細節看看,就是Driver + 一個 Worker,這樣看得更清楚:
至此,worker部分分析完畢,下一篇我們看看如何處理錯誤。
PaddlePaddle Fluid:彈性深度學習在Kubernetes中的實踐
Horovod 彈性訓練
ElasticDL調用 Horovod 在Kubernetes上實作彈性 AllReduce(一)
Kubernetes-native 彈性分布式深度學習系統
雲原生的彈性 AI 訓練系列之一:基于 AllReduce 的彈性分布式訓練實踐