【Kafka】Leader選舉(broker /分區)
Kafka叢集Leader選舉原理
我們知道Zookeeper叢集中也有選舉機制,是通過Paxos算法,通過不同節點向其他節點發送資訊來投票選舉出leader,但是Kafka的leader的選舉就沒有這麼複雜了。
Kafka的Leader選舉是通過在zookeeper上建立/controller臨時節點來實作leader選舉,并在該節點中寫入目前broker的資訊
{“version”:1,”brokerid”:1,”timestamp”:”1512018424988”}
利用Zookeeper的強一緻性特性,一個節點隻能被一個用戶端建立成功,建立成功的broker即為leader,即先到先得原則,leader也就是叢集中的controller,負責叢集中所有大小事務。
當leader和zookeeper失去連接配接時,臨時節點會删除,而其他broker會監聽該節點的變化,當節點删除時,其他broker會收到事件通知,重新發起leader選舉。
Kafka的Leader是什麼
首先Kafka會将接收到的消息分區(partition),每個主題(topic)的消息有不同的分區。這樣一方面消息的存儲就不會受到單一伺服器存儲空間大小的限制,另一方面消息的處理也可以在多個伺服器上并行。
其次為了保證高可用,每個分區都會有一定數量的副本(replica)。這樣如果有部分伺服器不可用,副本所在的伺服器就會接替上來,保證應用的持續性。
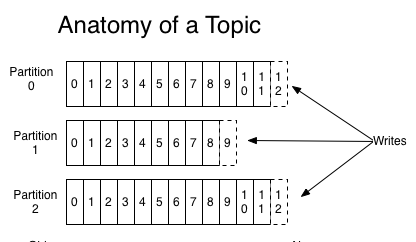
但是,為了保證較高的處理效率,消息的讀寫都是在固定的一個副本上完成。這個副本就是所謂的Leader,而其他副本則是Follower。而Follower則會定期地到Leader上同步資料。
如果某個分區所在的伺服器除了問題,不可用,kafka會從該分區的其他的副本中選擇一個作為新的Leader。之後所有的讀寫就會轉移到這個新的Leader上。現在的問題是應當選擇哪個作為新的Leader。顯然,隻有那些跟Leader保持同步的Follower才應該被選作新的Leader。
Kafka會在Zookeeper上針對每個Topic維護一個稱為ISR(in-sync replica,已同步的副本)的集合,該集合中是一些分區的副本。隻有當這些副本都跟Leader中的副本同步了之後,kafka才會認為消息已送出,并回報給消息的生産者。如果這個集合有增減,kafka會更新zookeeper上的記錄。
如果某個分區的Leader不可用,Kafka就會從ISR集合中選擇一個副本作為新的Leader。
顯然通過ISR,kafka需要的備援度較低,可以容忍的失敗數比較高。假設某個topic有f+1個副本,kafka可以容忍f個伺服器不可用。
少數服從多數是一種比較常見的一緻性算法和Leader選舉法。
它的含義是隻有超過半數的副本同步了,系統才會認為資料已同步;
選擇Leader時也是從超過半數的同步的副本中選擇。
這種算法需要較高的備援度。
譬如隻允許一台機器失敗,需要有三個副本;而如果隻容忍兩台機器失敗,則需要五個副本。
而kafka的ISR集合方法,分别隻需要兩個和三個副本。
如果所有的ISR副本都失敗了怎麼辦?
此時有兩種方法可選,一種是等待ISR集合中的副本複活,一種是選擇任何一個立即可用的副本,而這個副本不一定是在ISR集合中。這兩種方法各有利弊,實際生産中按需選擇。
如果要等待ISR副本複活,雖然可以保證一緻性,但可能需要很長時間。而如果選擇立即可用的副本,則很可能該副本并不一緻。
![虛拟機---kafka的安裝[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)