Lucene
01.資料的分類
結構化資料:有固定類型或者有固定長度的資料
例如:資料庫中的資料(mysql,oracle等), 中繼資料(就是windows中的資料)
結構化資料搜尋方法:
資料庫中資料通過sql語句可以搜尋
中繼資料(windows中的)通過windows提供的搜尋欄進行搜尋
非結構化資料:沒有固定類型和固定長度的資料
例如: world文檔中的資料, 郵件中的資料
非結構化資料搜尋方法:
Word文檔使用ctrl+F來搜尋
順序掃描法:
Ctrl+F中是使用的順序掃描法,拿到搜尋的關鍵字,去文檔中,逐字比對,直到找到和關鍵字一緻的内容為止.
優點: 如果文檔中存在要找的關鍵字就一定能找到想要的内容
缺點: 慢, 效率低
全文檢索算法(反向索引算法):
将檔案中的内容提取出來, 将文字拆封成一個一個的詞(分詞), 将這些詞組成索引(字典中的目錄), 搜尋的時候先搜尋索引,通過索引找文檔,這個過程就叫做全文檢索.
分詞: 去掉停用詞(a, an, the ,的, 地, 得, 啊, 嗯 ,呵呵),因為搜尋的時候搜尋這些詞沒有意義,将句子拆分成詞,去掉标點符号和空格
優點: 搜尋速度快
缺點: 因為建立的索引需要占用磁盤空間,是以這個算法會使用掉更多的磁盤空間,這是用空間換時間
原理:
相當于字典,分為目錄和正文兩部分,查詢的時候通過先查目錄,然後通過目錄上标注的頁數去正文頁查找需要的内容
02.Lucene
什麼是lucene
Lucene是apache旗下的頂級項目,是一個全文檢索工具包
Lucene就是一個可以建立全文檢索引擎系統的一堆jar包.可以使用它來建構全文檢索引擎系統,但是它不能獨立運
全文檢索引擎系統
放在tomcat下可以獨立運作,對外提供全文檢索服務.
03.Lucene應用領域
1. 網際網路全文檢索引擎(比如百度, 谷歌, 必應)
2. 站内全文檢索引擎(淘寶, 京東搜尋功能)
3. 優化資料庫查詢(因為資料庫中使用like關鍵字是全表掃描也就是順序掃描算法,查詢慢)
Lucene下載下傳
官方網站:http://lucene.apache.org/
版本:lucene4.10.3
Jdk要求:1.7以上
IDE:Eclipse
04.Lucene結構
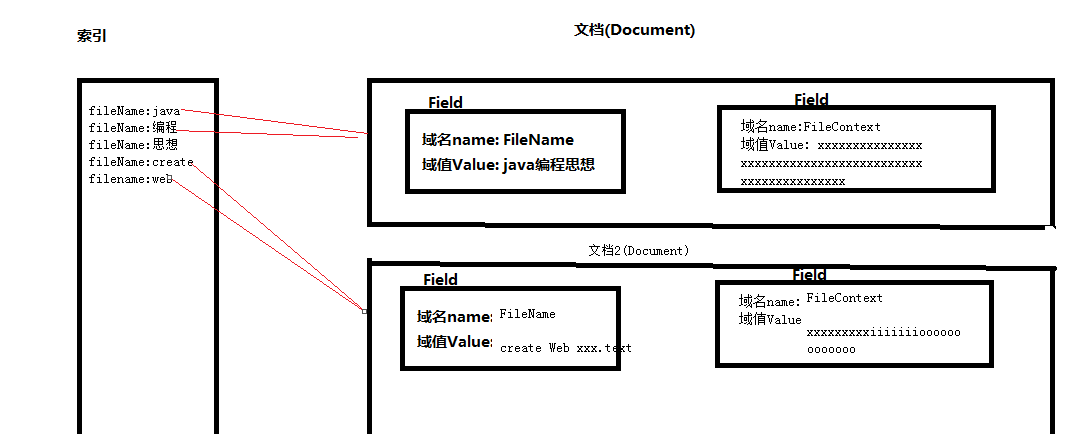
索引:
域名:詞 這樣的形式,
它裡面有指針執行這個詞來源的文檔
索引庫: 放索引的檔案夾(這個檔案夾可以自己随意建立,在裡面放索引就是索引庫)
Term詞元: 就是一個詞, 是lucene中詞的最小機關
文檔:
Document對象,一個Document中可以有多個Field域對象,Field域對象中是key value鍵值對的形式:有域名和域值,
一個document就是資料庫表中的一條記錄, 一個Filed域對象就是資料庫表中的一行一列
這是一個通用的存儲結構.
建立索引和所有時所用的分詞器必須一緻
05.操作_建立索引

/**
* 采集檔案系統中的文檔資料,放入Lucene中
* @throws Exception
*/
@Test
public void testIndexCreate()throws Exception{
List<Document> docList = new ArrayList<Document>();
//指定檔案目錄
File dir = new File("D:\\searchsource");
//循環檔案夾,取出檔案
for(File file:dir.listFiles()) {
String fileName = file.getName();
String fileContext = FileUtils.readFileToString(file);
Long fileSize = FileUtils.sizeOf(file);
//檔案系統中的一個檔案就是一個document對象
Document doc = new Document();
//第一個參數叫做域名,第二個參數叫做域值,第三個參數是否存儲,yes/no
TextField nameField = new TextField("fileName", fileName,Store.YES);
TextField contextField = new TextField("fileContext", fileContext,Store.YES);
TextField sizeField = new TextField("fileSize", fileSize.toString(),Store.YES);
//将所有的域都存入文檔中
doc.add(nameField);
doc.add(sizeField);
doc.add(contextField);
docList.add(doc);
}
//建立分詞器,StandardAnalyzer是一個标準分詞器,對英文效果好,對中文單字分詞
Analyzer analyzer = new StandardAnalyzer();
//指定索引和文檔的目錄
//RAMDirectory:記憶體,FSDirectory:磁盤
Directory directory = FSDirectory.open(new File("D:\\luceneTest"));
//建立寫對象的初始化對象
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3,analyzer);
//建立索引寫對象
IndexWriter indexWriter = new IndexWriter(directory, config);
for(Document doc:docList) {
indexWriter.addDocument(doc);
}
//送出
indexWriter.commit();
indexWriter.close();
}
} 06.使用Luke檢視建立的索引
Lucene
Lucene
Lucene
07.操作_搜尋
public class IndexSearchTest {
@Test
public void testIndexSearch()throws Exception{
//建立分詞器:建立索引和搜尋時用的分詞器一緻
Analyzer analyzer = new StandardAnalyzer();
//建立查詢對象,第一個參數是預設搜尋域,第二個參數是分詞器
//預設搜尋域的作用:如果搜尋文法中指定域名從指定域中搜尋,如果搜尋時隻寫了查詢關鍵字,則從預設搜尋域中搜尋
QueryParser queryParser = new QueryParser("fileContext", analyzer);
//查詢文法=域名:搜素的關鍵字
Query query = queryParser.parse("fileName:apache");
//指定索引和文檔的目錄
Directory dir = FSDirectory.open(new File("D:\\luceneTest"));
//建立索引和文檔讀取對象
IndexReader indexReader = IndexReader.open(dir);
//建立索引搜尋對象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//第一個參數為查詢語句對象,第二為顯示的條數
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("==count==" + topDocs.totalHits);
//從搜尋結果對象中擷取結果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for(ScoreDoc scoreDoc:scoreDocs) {
//擷取docID
int docID = scoreDoc.doc;
//通過文檔ID從硬碟讀取出相應的文檔
Document document = indexReader.document(docID);
//get域名可以取出值列印
System.out.println("fileName" + document.get("fileName"));
System.out.println("fileSize" + document.get("fileSize"));
System.out.println("===============================");
}
}
} 注意:Query query = queryParser.parse("fileName:apache");這個文法自己寫
08.域的詳細介紹
是否分詞:
分詞的作用是為了索引
需要分詞: 檔案名稱, 檔案内容
不需要分詞: 不需要索引的域不需要分詞,還有就是分詞後無意義的域不需要分詞
比如: id, ×××号
是否索引:
索引的的目的是為了搜尋.
需要搜尋的域就一定要建立索引,隻有建立了索引才能被搜尋出來
不需要搜尋的域可以不建立索引
需要索引: 檔案名稱, 檔案内容, id, ×××号等
不需要索引: 比如圖檔位址不需要建立索引, e:\\xxx.jpg
因為根據圖檔位址搜尋無意義
是否存儲:
存儲的目的是為了顯示.
是否存儲看個人需要,存儲就是将内容放入Document文檔對象中儲存出來,會額外占用磁盤空間, 如果搜尋的時候需要馬上顯示出來可以放入document中也就是要存儲,這樣查詢顯示速度快, 如果不是馬上立刻需要顯示出來,則不需要存儲,因為額外占用磁盤空間不劃算.
域的各種類型
| Field類 | 資料類型 | Analyzed 是否分析 | Indexed 是否索引 | Stored 是否存儲 | 說明 |
| StringField(FieldName, FieldValue,Store.YES)) | 字元串 | N | Y | Y或N | 這個Field用來建構一個字元串Field,但是不會進行分析,會将整個串存儲在索引中,比如(訂單号,姓名等) 是否存儲在文檔中用Store.YES或Store.NO決定 |
| LongField(FieldName, FieldValue,Store.YES) | Long型 | 這個Field用來建構一個Long數字型Field,進行分析和索引,比如(價格) | |||
| StoredField(FieldName, FieldValue) | 重載方法,支援多種類型 | 這個Field用來建構不同類型Field 不分析,不索引,但要Field存儲在文檔中 | |||
| TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader) | 流 | 如果是一個Reader, lucene猜測内容比較多,會采用Unstored的政策. |
注意:lucene底層的算法,錢數是要分詞的,因為要根據價錢進行對比
例如: 大于12.5元的小于100元的商品搜尋出來
09.中文索引
建立分詞器Analyzer analyzer = new IKAnalyzer();
010.操作_索引維護(删除)
| @Test public void testIndexDel() throws Exception{ //建立分詞器,StandardAnalyzer标準分詞器,标準分詞器對英文分詞效果很好,對中文是單字分詞 Analyzer analyzer = new IKAnalyzer(); //指定索引和文檔存儲的目錄 Directory directory = FSDirectory.open(new File("E:\\dic")); //建立寫對象的初始化對象 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); //建立索引和文檔寫對象 IndexWriter indexWriter = new IndexWriter(directory, config); //删除所有 //indexWriter.deleteAll(); //根據名稱進行删除 //Term詞元,就是一個詞, 第一個參數:域名, 第二個參數:要删除含有此關鍵詞的資料 indexWriter.deleteDocuments(new Term("fileName", "apache")); //送出 indexWriter.commit(); //關閉 indexWriter.close(); |
011.操作_索引維護(更新)
| /** * 更新就是按照傳入的Term進行搜尋,如果找到結果那麼删除,将更新的内容重新生成一個Document對象 * 如果沒有搜尋到結果,那麼将更新的内容直接添加一個新的Document對象 * @throws Exception */ public void testIndexUpdate() throws Exception{ //根據檔案名稱進行更新 Term term = new Term("fileName", "web"); //更新的對象 Document doc = new Document(); doc.add(new TextField("fileName", "xxxxxx", Store.YES)); doc.add(new TextField("fileContext", "think in java xxxxxxx", Store.NO)); doc.add(new LongField("fileSize", 100L, Store.YES)); //更新 indexWriter.updateDocument(term, doc); |