目錄
計算機的基本構成
Windows/Linux等作業系統的基本概念及其常見操作
作業系統的運作環境
運作機制
作業系統核心
核心體系結構
計算機網絡和Internet基本概念
計算機的曆史
NOI以及相關活動的曆史
進制
進制轉換
儲存空間大小
程式編譯運作基本概念
計算機的基本構成
根據大綱可以猜測計算機由CPU、記憶體、IO裝置等構成
參考資料
計算機由軟體和硬體構成
硬體裡面有中央處理器,也就是我們常說的CPU,這裡面有算術邏輯運算器ALU和控制器CU
硬體還有其他三部分,分别是存儲器,輸入裝置和輸出裝置
其中存儲器分為記憶體儲器和外存儲器,外存儲器就是磁盤啊CD光牒啊之類的可以拆掉的。記憶體儲器應該是刻在主機闆上的,是以我們電腦的記憶體是4G(對我的配置低),就是記憶體儲器的最大容量隻有4G,你使勁給他裝硬碟隻是增加外存儲器而已,還不如清理一下緩存/擦汗
記憶體儲器也分為随機存取存儲器RAM和隻讀存儲器ROM
RAM也叫主存,是直接和CPU交換資料的内部存儲器,速度極快,通常作為臨時存儲資料的地方,很快很快,但是斷電就資料全沒了
ROM,顧名思義,Read-Only Memory,隻能讀出無法寫入,就算斷電資料也還在(根本不用修改怎麼不在)通常是裝入整機之前寫入資料,用來存儲各種固定的程式和資料
還有一個小小的(真的很小)寄存器register就在CPU旁邊,運算速度極高,是以很多程式猿在for的時候喜歡用register來定義,那麼register究竟有多小呢?我不知道我隻知道我曾經for全用register 直接WA,去掉就好了
至于輸入輸出裝置,很多啦,像什麼鍵盤滑鼠掃描器列印機都是
PS:列印機是輸出裝置,至于你能用列印機掃描之類的,是因為你的列印機上裝了掃描器
軟體方面,首先就是系統軟體,就要有作業系統,比如DOS,windoes,Linux之類的
然後就要語言處理程式,系統之用程式,資料庫管理系統。。。反正進C槽什麼都能看見了
最後軟體還有你自己安裝的軟體,電腦原配程式庫。
在計算機中資料是用二進制存儲的,首先程式的資料通過輸入裝置到達儲存器,然後控制器控制運算器從存儲器中擷取資料并運算,然後把運算結果放回存儲器,随後通過輸出裝置輸出。
Windows/Linux等作業系統的基本概念及其常見操作
我怎麼知道什麼基本概念随便水一下算了
operating system,os,就是作業系統,是以Python裡面可以看見
(别問我為什麼突然将程序)
程序是一個具有一定獨立功能的程式關于某個資料集合的一次運作活動。
程序的概念主要有兩點:(from百度百科)
第一,程序是一個實體。每一個程序都有它自己的位址空間,一般情況下,包括文本區域(text region)、資料區域(data region)和堆棧(stack region)。文本區域存儲處理器執行的代碼;資料區域存儲變量和程序執行期間使用的動态配置設定的記憶體;堆棧區域存儲着活動過程調用的指令和本地變量。
第二,程序是一個“執行中的程式”。程式是一個沒有生命的實體,隻有處理器賦予程式生命時(作業系統執行之),它才能成為一個活動的實體,我們稱其為程序。
動态性:程序的實質是程式在多道程式系統中的一次執行過程,程序是動态産生,動态消亡的。
并發性:任何程序都可以同其他程序一起并發執行
獨立性:程序是一個能獨立運作的基本機關,同時也是系統配置設定資源和排程的獨立機關;
異步性:由于程序間的互相制約,使程序具有執行的間斷性,即程序按各自獨立的、不可預知的速度向前推進
結構特征:程序由程式、資料和程序控制塊三部分組成。
多個不同的程序可以包含相同的程式:一個程式在不同的資料集裡就構成不同的程序,能得到不同的結果;但是執行過程中,程式不能發生改變。
而線程呢,是作業系統能夠進行運算排程的最小機關。它被包含在程序之中,是程序中的實際運作機關。一條線程指的是程序中一個單一順序的控制流,一個程序中可以并發多個線程,每條線程并行執行不同的任務。
我們需要區分“并發”和“并行”兩個概念,并行是指兩件事在同一時刻同時發生,并發是指兩件事在時間内間隔發生,(當然也可以不隻兩件事)
比如事件A:清空螢幕并在螢幕第一行第一列輸出1
事件B:清空螢幕并在螢幕第一行第二列輸出2
不斷執行事件A,B
如果是并行,那麼就
多線程就是采用并行的方法運作的,你看着它同時處理很爽哦,其實他是分開處理的,先做一下這個,然後做一下那個,再回來做一下這個……至于這一下……就短到你認為他是在一起做的
比如上面那個并行的例子圖像在視網膜上殘留(?)的時間約為100~400ms(百度說的),那麼我隻要10ms來執行A,10ms執行B,那麼在前100ms内我是交錯分别執行了5次A和5次B,這樣你的眼睛看上去就是同時輸出了12
但是如果我加上Sleep(1000)指令,也就是我需要1010ms來執行A,1010ms來執行B,那麼停留時間内就會有全部都是1或者全部都是2的時候,你才會覺得他是分開執行的
是以計算機這一下是極短的,才能讓我一邊聽歌一邊水文章
然後共享,系統中的資源可以供多個并發的程序共同使用
分為互斥共享和同時共享,互斥就是一個時刻隻能一個程序通路即程序們是輪流通路資源的,共享是多個程序同時通路資源(跟并發和并行的關系差不多)
虛拟:把一個實體上的實體變為若幹個邏輯上的對應物。實體實體是實際存在的,而邏輯上對應物是使用者感受到的。
虛拟技術中的時分複用技術。微觀上處理機在各個微小的時間段内交替着為各個程序服務。
異步:在多道環境程式下,允許多個程式并發執行,但由于資源有限,程序的執行不是一貫到底的,而是走走停停的,以不可預知的速度向前推進,這就是程序的異步性。
(然而好像沒什麼用)
系統調用,是作業系統提供給應用程式使用的接口。
比如你的列印機是作業系統的話,程序要通過系統調用才能使用列印機,你通過系統調用向列印機傳入你的論文,然後列印機再列印出你的論文。
如果你列印到一半,同學也通過系統調用向列印機傳入他的照片,那麼列印機知道要列印照片,但是一定要等列印完論文先再列印照片。這就是系統調用,相當于在使用者态給系統一個指令,實際處理指令的是核心态(就是你的列印機)
作業系統的運作機制有兩種指令、兩種處理器狀态和兩種程式
兩種處理器狀态就是使用者态(目态)和核心态(管态),上面說過使用者态是給使用者調用的,核心态才是處理器真正處理指令的狀态。通過程式狀态字寄存器(PSW)的某個位來表示目前處理器的狀态。比如0是目态,1是管态
那麼肯定了,使用者是不可以執行某些指令,比如說把所有記憶體清零。如果你正在列印你的論文,突然同學來把記憶體清零了,那麼你的論文……節哀。但是在核心态是肯定會執行記憶體清零這樣的指令的,你敲題目的時候也難免會用到memset,雖然memset也是使用者态,但是底層他調用核心态的“清空記憶體”,這些就是核心态才能用的特權指令。相對的,使用者态和核心态都能調用的指令就是非特權指令。
是以,可以推得,兩種程式就是指核心程式和應用程式。核心程式是系統的管理者,在核心态運作,可以執行所有指令。
而應用程式,就是windows上面的.exe檔案(看檔案類型就知道了)。就是使用者隻能調用的程式,隻能執行費特權指令,運作在使用者态。
時鐘管理:實作計時功能
中斷處理:用來實作中斷目前線程去執行其他并發線程的中斷機制
原語:一種特殊的程式,作業系統最底層,不能中斷的程式(原子性),運作時間極短,調用頻繁
原語其實就是最底層的程式,原語經過不斷包裝才能變成我們使用的程式。
比如我們看cout,就是一個ofstream類型的變量,指向了stdout(其實stdout應該是FILE類型的但我不管反正就是表示stdout),然後我們使用cout輸出的時候是調用經過包裝後的左移運算符。即
的時候我們其實是調用
而這裡重載的左移運算符的函數定義應該是:
至于實作……不知道
是以我們以後就可以
就可以直接用cout來輸出一個pair類型的變量
這裡我就用系統提供的oftream* operator << (ofstream, int)包裝成了ofstream operator << (ofstream, pair)函數。
同理oftream operator << (ofstream*, int)也是通過底層函數包裝來實作的
底層函數又是通過更底層函數包裝來時限的……
……
一直到最底層,就是原語,到了原語級别程式極度精簡,因為原語不允許中斷。
我的輸出函數可以先輸出了first,中斷一下,執行其他,再回來輸出second(隻要其他不會幹擾我的輸出結果),這樣是可以的。因為我的函數很清晰是分成兩個底層函數來執行,這兩個函數是并發的,是可以斷開執行的。但是這樣分下去總要有個遞歸邊界,就是原語
然後核心還有對系統資源進行管理的功能,包括程序管理、存儲器管理、裝置管理等
大核心
把作業系統的大部分功能都寫進核心裡面,在核心态運作(就是核心管大部分的事)
優點:封裝函數的層數較少,疊代比較少次就能達到原語級别,性能較高。
缺點:核心代碼龐大,結構混亂,難以維護
微核心
隻把基本必要的程式留在核心
優點:核心功能少,結構清晰,友善維護。
缺點:疊代次數多,需要頻繁在核心态和使用者态之間切換,性能低。
舉個栗子,如果我要寫一個隻用來輸出的系統,那麼基本的必要的程式就是putchar(int),這是我這個系統裡面最低級的程式。
如果是微核心,我隻需要在核心裡實作putchar函數就可以了。到時候維護隻需要維護putchar函數就可以了。至于其他的
之類的函數都是使用者态的,使用者可以直接調用。但是這樣的話如果我們要實作cout就會是
雖然我不知道怎麼可以寫入到ofile裡面,這樣你調用了一次左移運算符,然後再帶調用write,通過使用者态調用的核心程式就必定會更多次(emmm好吧這個栗子展現不出來),是很慢的
如果是大核心,我們就可以把上述出現的所有函數都放入核心裡面,這樣可以直接在核心态執行程式,不需要判斷使用者态是否有非法操作(執行特權指令),這樣就會快很多,但與此同時整個源程式也會龐大很多,就像你的碼量上去之後維護會很艱難/苦笑
計算機網絡和Internet基本概念
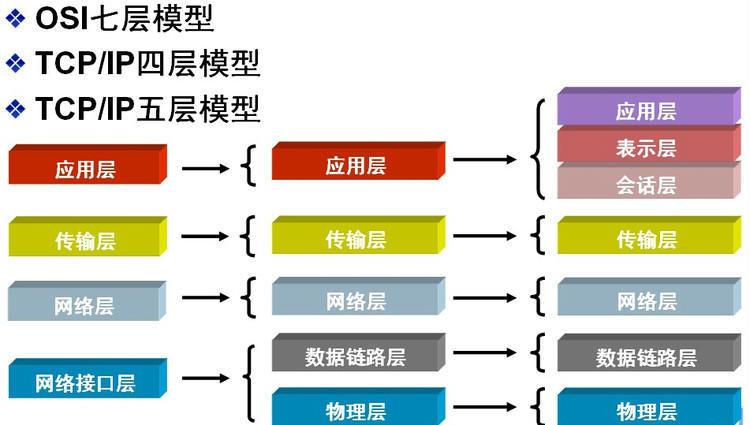
為了使不同計算機廠家生産的計算機能夠互相通信,以便在更大的範圍内建立計算機網絡,國際标準化組織(ISO)在1978年提出了"開放系統互聯參考模型",即著名的OSI/RM模型(Open System Interconnection/Reference Model)。它将計算機網絡體系結構的通信協定劃分為七層,自下而上依次為:實體層(Physics Layer)、資料鍊路層(Data Link Layer)、網絡層(Network Layer)、傳輸層(Transport Layer)、會話層(Session Layer)、表示層(Presentation Layer)、應用層(Application Layer)。其中第四層(傳輸層)完成資料傳送服務,上面三層面向使用者。
但是即使是這樣,全球的計算機可以互相通信了,但是由于各計算機使用的字元集不同,是以有些計算機可能不能很好通信。
這個字元集,可以簡單了解為編碼。你有沒有試過程式輸出中文的時候亂碼,然後加一句setlocale(LC_ALL,"");就搞定的時候?這就是因為你的中文使用的是utf-8編碼,但是控制台預設的chcp 是936,也就是gbk字元集,但是你的utf-8是屬于Unicode字元集的,是以就會出現亂碼,也就是無法通信。
再舉個栗子,我們平時在寫代碼的時候采用的ASCII碼也是一種字元集,但是沒有中文是以中文是不能用ASCII來表示的。如果強制用ASCII來顯示中文字元的話:
首先我們百度搜尋“犇”字
得到網址https://www.baidu.com/s?wd=%E7%8A%87 (已經去掉好多沒用的參數)
從中截取“犇”的編碼:0xE78A87的六位hex,每位hex是4位bin,8位bin就是1byte,是以每兩位hex就是1byte,也就是一個正常的char,是以0xE78A87這個中文字元就可以用三個char 來表示:0xE7, 0x8A, 0x87
然後這些如果轉成int就變成了-25,-118, -121,然後如果你再用ascii輸出……幸運的話會輸出不可見字元,不幸運的話就是亂碼
附上測試代碼:
那麼怎麼解決計算機采用不同字元集的問題呢?網絡協定就出來了。
百度:網絡協定為計算機網絡中進行資料交換而建立的規則、标準或約定的集合。
在資料鍊路層主要使用的協定就是以太網協定。從某種意義上講,以太網就是區域網路。
網絡層的協定主要有
IP協定(Internet Protocol,網際網路互聯協定);
ICMP協定(Internet Control Message Protocol,網際網路控制封包協定);
ARP協定(Address Resolution Protocol,位址解析協定);
RARP協定(Reverse Address Resolution Protocol,逆位址解析協定)。
在應用層上,又會有FTP(檔案傳送協定)、Telnet(遠端登入協定)、DNS(域名解析協定)、SMTP(郵件傳送協定),POP3協定(郵局協定),HTTP協定(Hyper Text Transfer Protocol 超文本傳輸協定)
IP位址:
IPv4是32位IP位址,就是在cmd裡面一個ipconfig就能知道的那個。因為32位位址好像不太夠用,是以就有IPv6,也就是128位IP位址(肯定夠用了)
IP位址分為5類:
D類:位址的32位bin以1110開頭,位址範圍是224.0.0.0~239.255.255.255,D類位址作為多點傳播位址/多點傳播位址(一對多的通信);
E類:位址以1111開頭,位址範圍是240.0.0.0~255.255.255.255,E類位址為保留位址,供以後使用。
接下來三類是私有位址:
私有位址屬于非注冊位址,專門為組織機構内部使用。
私有位址由網絡号和主機号組成
前面一些連續位稱為網絡号,用于表示該裝置位于哪個網絡,後面的其餘位稱為主機位址,用于在該網絡中唯一辨別一台主機。
A類位址以0開頭,第一個位元組(也就是前八位)作為網絡号,位址範圍為:0.0.0.0~127.255.255.255
B類位址以10開頭,前兩個位元組作為網絡号,位址範圍是:128.0.0.0~191.255.255.255;
C類位址以110開頭,前三個位元組作為網絡号,位址範圍是:192.0.0.0~223.255.255.255。
但是這樣分就會發現,A類位址按網絡号分類隻有128個網絡,但是每個網絡可以擁有……好多好多個……\(2^24\)個主機
而C類位址恰好反過來,他的網絡數遠遠大于主機數(我才不算呢哼唧)這樣就會造成資源效率低下。
是以後來就有人把主機号劃分成了子網+主機号
這種方式被稱為子網尋址。
子網是從每類的網絡位址的主機部分拿出一定數量的位數,用該位數辨別子網号,進而将每類的IP網絡進一步分成更小的網絡。
這樣之後A類位址的(子)網絡數就會大大提升,然後每個網絡對應的主機數就少了。
但是增加了子網之後,我怎麼知道從哪裡開始是主機号!!!
是以就出來了子網路遮罩
子網路遮罩是由一段連續的1和一段連續的0組成的32位bin,把它和IP位址按位與就可以得到網絡号
比如子網路遮罩由30個1和2個0組成,那麼對IP位址按位與之後前30位不變,那麼這個IP位址的前30位就是網絡号(網絡位址+子網位址),剩下的兩位就是主機号
計算機的曆史
???
參考資料(自行觀看)
以下是摘抄重點:
第一台真正計算機的出現
帕斯卡發明了人類有史以來第一台機械計算機——帕斯卡加法器。它是一種系列齒輪組成的裝置,外形像一個長方盒子,用兒童玩具那種鑰匙旋緊發條後才能轉動,隻能夠做加法和減法。然而,即使隻做加法,也有個“逢十進一”的進位問題。聰明的帕斯卡采用了一種小爪子式的棘輪裝置。當定位齒輪朝9轉動時,棘爪便逐漸升高;一旦齒輪轉到0,棘爪就“咔嚓”一聲跌落下來,推動十位數的齒輪前進一檔。
1662年帕斯卡去世,不久後,在德國的大數學家萊布尼茨看到了帕斯卡關于加法計算機的論文,勾引起了他的發明欲。萊布尼茨早年經曆坎坷,後來獲得了一次去法國的機會,在巴黎的時候,他聘請了一些著名的機械專家和能工巧匠,終于在1674年制造出了一台更完美的機械計算機。
萊布尼茨發明的新型計算機約有1米長,内部安裝了一系列齒輪機構,除了體積較大之外,基本原理繼承于帕斯卡。不過,萊布尼茨技高一籌,他為計算機增添了一種名叫“步進輪”的裝置。步進輪是一個有9個齒的長圓柱體,9個齒依次分布于圓柱表面;旁邊另有個小齒輪可以沿着軸向移動,以便逐次與步進輪齧合。每當小齒輪轉動一圈,步進輪可根據它與小齒輪齧合的齒數,分别轉動1/10、2/10圈……,直到9/10圈,這樣一來,它就能夠連續重複地做加法。
連續重複的計算加法是現代計算機做乘除法采用的辦法,萊布尼茨的計算機加減乘除四則運算一應俱全。
在介紹萊布尼茨的時候還有一個小插曲。(傳說大約在1700年左右的某天,萊布尼茨的朋友送給他一副中國的”易圖“,其實就是八卦圖,在看八卦圖的時候,發現八卦的每一種卦象都有陰陽兩種符号組成,這不就是有規律的二進制數字麼,于是他就由此,率先系統提出了二進制的運算法則,直到今天,我們用到的計算機還是使用的二進制。)

第一台電子計算機:阿塔納索夫-貝瑞計算機(Atanasoff–Berry Computer,通常簡稱ABC計算機)在1937年設計,不可程式設計,僅僅設計用于求解線性方程組,并在1942年成功進行了測試。
第一代電子管計算機(1946~1958):
特點: 操作指令是為特定任務而編制的,每種機器有各自不同的機器語言,功能受到限制,速度也慢。另一個明顯特征是使用真空電子管和磁鼓儲存資料。
第二代半導體計算機 (1956-1963):
特點: 半導體代替了體積龐大電子管,使用磁芯存儲器。體積小、速度快、功耗低、性能更穩定。還有現代計算機的一些部件:列印機、錄音帶、磁盤、記憶體、作業系統等。在這一時期出現了更進階的COBOL和FORTRAN等程式設計語言,使計算機程式設計更容易。新的職業(程式員、分析員和計算機系統專家)和整個軟體産業由此誕生。
第三代內建電路計算機 (1964-1971):
以中小規模內建電路,來構成計算機的主要功能部件。主存儲器采用半導體存儲器。運算速度可達每秒幾十萬次至幾百萬次基本運算。在軟體方面,作業系統日趨完善。
第四代大規模內建電路計算機 (1971-至今):
從1970年以後采用大規模內建電路(LSI)和超大規模內建電路(VLSI)為主要電子器件制成的計算機,重要分支是以大規模、超大規模內建電路為基礎發展起來的微處理器和微型計算機。
敲黑闆劃重點:
馮·諾依曼:現代計算機之父,發表了著名的“101頁報告”。明确規定出計算機的五大部件(輸入系統、輸出系統、存儲器、運算器、控制器),并用二進制替代十進制運算,大大友善了機器的電路設計。
克勞德·艾爾伍德·香農:資訊論之父。提出了資訊熵的概念,為資訊論和數字通信奠定了基礎。
艾倫·麥席森·圖靈:計算機科學之父,二戰破解德軍密碼。
計算機在現代社會的常見應用……用常識吧幫不了你了
NOI以及相關活動的曆史
看官網去
接下來開啟……快速模式?
進制
就是逢幾進1啦……最低就是二進制。可以類比成算盤,如果是n進制,那麼從右向左數第i位是j就表示有j個\(n^{i-1}\)
比如\((10010)_2\) 就表示\(0\times 2^0 + 1 \times 2^1 + 0 \times 2^2 + 0 \times 2^3 + 1 \times 2^4=(18)_{10}\)
一般用b表示二進制binary,o代表八進制octonary,x代表十六進制hexadecimal,d表示十進制decimal,計算機中0b開頭的就是二進制,0x開頭的就是16進制。
可以用十進制作為跳闆先把i進制轉換為10進制,然後再用短除法通過餘數得到j進制
\((10010)_2=(18)_{10}=(200)_3\)
如果是負數二進制,好有道理的資料,就用補碼存儲。
反碼:就是源碼取反,c++裡面有個位運算符~(小波浪)就是取反,\(~2=-3\)
\[2=(0000000010)_2~2=(1111111101)_2
\]
那麼計算機儲存的是~2的補碼(因為是負數)\((1111111110)_2\)
補碼轉回十進制,首先就要求得反碼,就是\((1111111101)_2\)
反碼知道是個負數,那麼負數二進制轉十進制,取反再加一,再加個負号
是以~2,取反再加一就是3,加負号,就是-3
儲存空間大小
bit:位(比特),最基本的儲存機關,隻能表示0/1
byte:位元組,一位元組有八位
Kb:千位元組,這裡千是約數,确切數是1024,1Kb=1024byte
Mb:兆位元組,1024Kb
Gb:千兆位元組,1024Mb
Tb:太位元組,1024Gb
Pb:拍位元組,1024Tb
Eb:艾位元組,1024Pb
程式編譯運作基本概念
C和C++差不多的吧……
1.預處理
此階段主要完成#符号後面的各項内容到源檔案的替換,往往一些莫名其妙的錯誤都是出現在頭檔案中的,要在工程中注意積累一些錯誤知識。
(1)、#ifdef等内容,完成條件編譯内容的替換
(2)、#include中内容,在目前目錄或者指定目錄,或者預設目錄搜尋頭檔案,并将頭檔案拷貝到源檔案中。
(3)、#define的内容,替換define的内容(包括上一步的頭檔案中的define内容)
此階段産生[.i]檔案。
而你自己寫的代碼就在檔案的最後
2.編譯
此階段完成文法和語義分析,然後生成中間代碼,此中間代碼是彙編代碼,但是還不可執行,gcc編譯的中間檔案是[.s]檔案。
在此階段會出現各種文法和語義錯誤,特别要小心未定義的行為,這往往是緻命的錯誤。
第一個階段和第二個階段由編譯器完成。
3.彙編
此階段主要完成将彙編代碼翻譯成機器碼指令,并将這些指令打包形成可重定位的目标檔案,[.O]檔案,是二進制檔案。
此階段由彙編器完成。
4.連結
此階段完成檔案中叼用的各種函數跟靜态庫和動态庫的連接配接,并将它們一起打包合并形成目标檔案,即可執行檔案。
此階段由連結器完成。
gcc編譯C語言主要用到以下幾個程式:C編譯器gcc、彙編器as、連結器ld和二進制轉換工具objcopy。
g++ [選項] 要編譯的檔案 [選項] [目标檔案]
其中,目标檔案可預設,gcc預設生成可執行的檔案名為:a.out
g++ main.cpp 直接生成可執行檔案a.exe
g++ main.cpp -o main.exe 生成main.exe可執行檔案
g++ -E main.cpp -o main.i 生成預處理後的代碼(還是文本檔案)
g++ –S main.i -o main.s 生成彙編代碼(已經看不懂了)
g++ main.s -o main.exe 生成目标代碼(exe檔案)