這幾天,一直在為Java的“記憶體洩露”問題糾結。Java應用程式占用的記憶體在不斷的、有規律的上漲,最終超過了監控門檻值。福爾摩 斯不得不出手了!
如果發現Java應用程式占用的記憶體出現了洩露的迹象,那麼我們一般采用下面的步驟分析:
把Java應用程式使用的heap dump下來
使用Java heap分析工具,找出記憶體占用超出預期(一般是因為數量太多)的嫌疑對象
必要時,需要分析嫌疑對象和其他對象的引用關系。
檢視程式的源代碼,找出嫌疑對象數量過多的原因。
如果Java應用程式出現了記憶體洩露,千萬别着急着把應用殺掉,而是要儲存現場。如果是網際網路應用,可以把流量切到其他伺服器。儲存現場的目的就是為了把 運作中JVM的heap dump下來。
JDK自帶的jmap工具,可以做這件事情。它的執行方法是:
format=b的含義是,dump出來的檔案時二進制格式。 file-heap.bin的含義是,dump出來的檔案名是heap.bin。
将二進制的heap dump檔案解析成human-readable的資訊,自然是需要專業工具的幫助,這裡推薦Memory Analyzer 。
Memory Analyzer,簡稱MAT,是Eclipse基金會的開源項目,由SAP和IBM捐助。巨頭公司出品的軟體還是很中用的,MAT可以分析包含數億級對 象的heap、快速計算每個對象占用的記憶體大小、對象之間的引用關系、自動檢測記憶體洩露的嫌疑對象,功能強大,而且界面友好易用。
MAT的界面基于Eclipse開發,以兩種形式釋出:Eclipse插件和Eclipe RCP。MAT的分析結果以圖檔和報表的形式提供,一目了然。總之個人還是非常喜歡這個工具的。下面先貼兩張官方的screenshots:
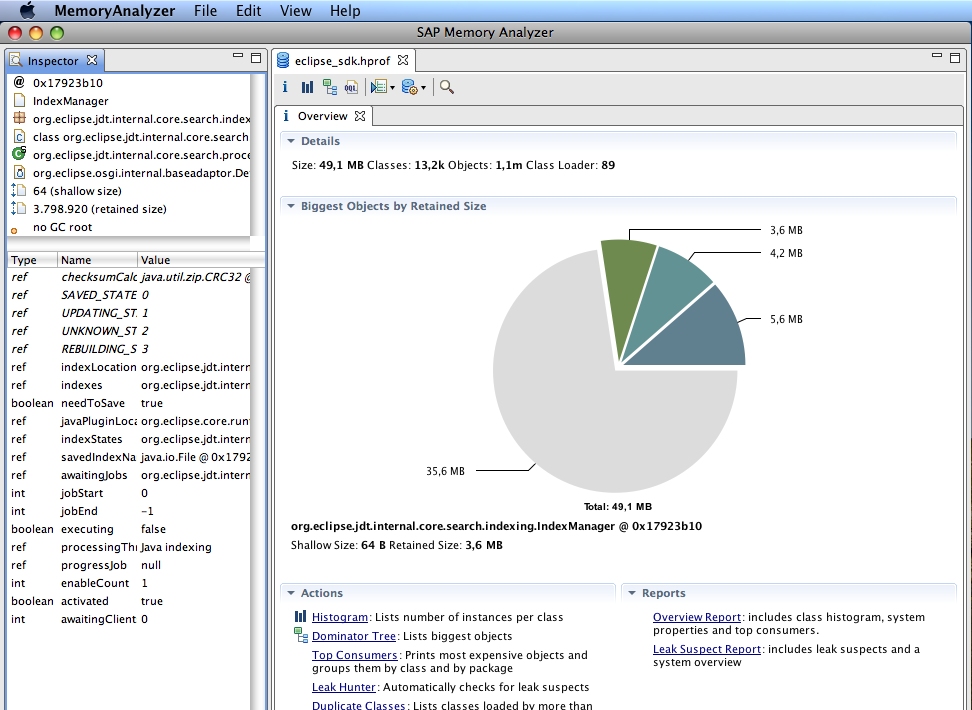

言歸正傳,我用MAT打開了heap.bin,很容易看出,char[]的數量出其意料的多,占用90%以上的記憶體 。一般來說,char[]在JVM确實會占用很多記憶體,數量也非常多,因為String對象以char[]作為内部存儲。但是這次的char[]太貪婪 了,仔細一觀察,發現有數萬計的char[],每個都占用數百K的記憶體 。這個現象說明,Java程式儲存了數以萬計的大String對象 。結合程式的邏輯,這個是不應該的,肯定在某個地方出了問題。
在可疑的char[]中,任意挑了一個,使用Path To GC Root功能,找到該char[]的引用路徑,發現String對象是被一個HashMap中引用的 。這個也是意料中的事情,Java的記憶體洩露多半是因為對象被遺留在全局的HashMap中得不到釋放。不過,該HashMap被用作一個緩存,設定了緩 存條目的門檻值,導達到門檻值後會自動淘汰。從這個邏輯分析,應該不會出現記憶體洩露的。雖然緩存中的String對象已經達到數萬計,但仍然沒有達到預先設定 的門檻值(門檻值設定地比較大,因為當時預估String對象都比較小)。
但是,另一個問題引起了我的注意:為什麼緩存的String對象如此巨大?内部char[]的長度達數百K。雖然緩存中的 String對象數量還沒有達到門檻值,但是String對象大小遠遠超出了我們的預期,最終導緻記憶體被大量消耗,形成記憶體洩露的迹象(準确說應該是記憶體消 耗過多) 。
就這個問題進一步順藤摸瓜,看看String大對象是如何被放到HashMap中的。通過檢視程式的源代碼,我發現,确實有String大對象,不 過并沒有把String大對象放到HashMap中,而是把String大對象進行split(調用String.split方法),然後将split出 來的String小對象放到HashMap中 了。
這就奇怪了,放到HashMap中明明是split之後的String小對象,怎麼會占用那麼大空間呢?難道是String類的split方法有問題?
帶着上述疑問,我查閱了Sun JDK6中String類的代碼,主要是是split方法的實作:
可以看出,Stirng.split方法調用了Pattern.split方法。繼續看Pattern.split方法的代碼:
這裡的match就是split出來的String小對象,它其實是String大對象subSequence的結果。繼續看 String.subSequence的代碼:
看第11、12行,我們終于看出眉目,如果subString的内容就是完整的原字元串,那麼傳回原String對象;否則,就會建立一個新的 String對象,但是這個String對象貌似使用了原String對象的char[]。我們通過String的構造函數确認這一點:
為了避免記憶體拷貝、加快速度,Sun JDK直接複用了原String對象的char[],偏移量和長度來辨別不同的字元串内容。也就是說,subString出的來String小對象 仍然會指向原String大對象的char[],split也是同樣的情況 。這就解釋了,為什麼HashMap中String對象的char[]都那麼大。
其實上一節已經分析出了原因,這一節再整理一下:
程式從每個請求中得到一個String大對象,該對象内部char[]的長度達數百K。
程式對String大對象做split,将split得到的String小對象放到HashMap中,用作緩存。
Sun JDK6對String.split方法做了優化,split出來的Stirng對象直接使用原String對象的char[]
HashMap中的每個String對象其實都指向了一個巨大的char[]
HashMap的上限是萬級的,是以被緩存的Sting對象的總大小=萬*百K=G級。
G級的記憶體被緩存占用了,大量的記憶體被浪費,造成記憶體洩露的迹象。
原因找到了,解決方案也就有了。split是要用的,但是我們不要把split出來的String對象直接放到HashMap中,而是調用一下 String的拷貝構造函數String(String original),這個構造函數是安全的,具體可以看代碼:
隻是,new String(string)的代碼很怪異,囧。或許,subString和split應該提供一個選項,讓程式員控制是否複用String對象的 char[]。
雖然,subString和split的實作造成了現在的問題,但是這能否算String類的bug呢?個人覺得不好說。因為這樣的優化是比較合理 的,subString和spit的結果肯定是原字元串的連續子序列。隻能說,String不僅僅是一個核心類,它對于JVM來說是與原始類型同等重要的 類型。
JDK實作對String做各種可能的優化都是可以了解的。但是優化帶來了憂患,我們程式員足夠了解他們,才能用好他們。
有個地方我沒有說清楚。
我的程式是一個Web程式,每次接受請求,就會建立一個大的String對象,然後對該String對象進行split,最後split之後的String對象放到全局緩存中。如果接收了5W個請求,那麼就會有5W個大String對象。這5W個大String對象都被存儲在全局緩存中,是以會造成記憶體洩漏。我原以為緩存的是5W個小String,結果都是大String。
有同學後續建議用"java.io.StreamTokenizer"來解決本文的問題。确實是終極解決方案,比我上面提到的“new String()”,要好很多很多。