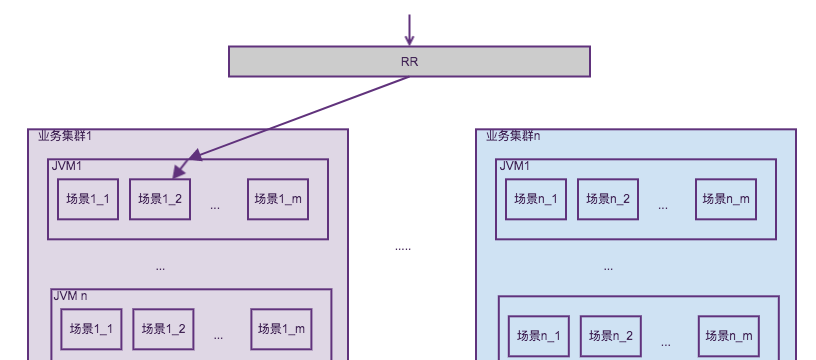
TPP有3600+個場景,每個場景是一些AB(算法方案代碼+業務配置+流量配置設定政策)的集合,場景按業務團隊劃分實體叢集,同一個實體叢集内的容器是對等的,JVM内部署着算法容器,算法容器内混布相同的場景集合,算法容器是平台編碼,場景方案代碼則是算法編碼并進行熱部署。前端請求以場景為粒度請求RR,RR擷取場景所在叢集按叢集進行路由。如下圖所示。
如前文所述,容器是平台開發編碼,代碼品質可控,而算法場景代碼則是全集團各個算法owner編寫,編碼品質參差不齊。這種情況下JVM内場景混布就會出現互相影響的問題,如cpu配置設定不均,記憶體配置設定不均等問題,最讨厭的是出現死循環。針對這些問題TPP已經将重要的核心場景和非重要的小場景進行實體隔離,即調配到不同的實體叢集,這樣一定程度上減少了非重要場景代碼問題導緻核心場景大量異常的情況,如逾時。但非核心叢集死循環,甚至核心叢集互相影響的情況還是時有發生。那為什麼不直接每個場景單獨一個容器部署呢,通過docker層面cgroup直接隔離場景是否可行?當然可行,但是機器成本将大幅上升。因為每個容器裡要加載各種二方服務,如pandora,forest,igraph,sumamry,各種hsf服務等,而且每個場景要保證至少兩台的可用度,這樣機器記憶體規模至少要擴大好多倍,機器數自然答複上漲。很多場景qps非常低的,峰值也是錯開的,混布能極大提高資源使用率。我們對隔離做了一些改進工作,包括線程池隔離,多租戶隔離。
首先系統進行了線程池隔離改造,算法方案代碼從HSF業務線程直接執行改為HSF業務線程送出給場景線程池執行。每個場景都管理一個自己的線程池,平台根據流量需求可動态調配不同的線程池參數。如下圖所示:

這樣做的好處是:
保護了hsf入口工作線程,改造之前算法方案逾時嚴重會造成容器hsf服務pool full。場景線程池隔離後根據場景逾時上限(一般是200ms)做逾時interrupt,保證不會大量并發堆積。同時場景線程池設定拒絕政策,在并發堆積超過wait_queue+max_pool的情況下立即拒絕服務。這樣一定程度提升了hsf的可用性。
減少無用的逾時後計算,hsf業務線程并不會被中斷,如果算法中途逾時了,并沒必要做後面的複雜計算工作,浪費的cpu資源也被節約下來。
場景間公平性得到一定保障,代碼有問題的場景不占滿hsf線程的情況下,其他場景仍能有流量得到服務。
線程池隔離在雙11前也發揮了作用,如rtp第一次成功更新arpc後出現過死鎖,發生調用的業務線程都會一直阻塞,如果發生在hsf線程,這台機器就game over了,而通過重置場景業務線程池就能免啟動瞬間修複。
線程池隔離帶來的問題是增加一定的上下文切換開銷,設定合理的core size和alive time,通過壓測和實際運作發現并沒有性能下降,也沒有明顯增加jvm的線程數。這裡從同步改造成線程池方式,需要解決一些問題,典型的就是ThreadLocal問題,包括eagleeye和業務threadlocal。下面是支援eagleeye和業務threadlocal透傳的線程池實作:
線程池隔離并沒有根本解決死循環和cpu配置設定不均問題,因為cpu密集型計算是無法interrupt的,同時TPP的一個平台價值之一是算法可以随時變更算法方案熱部署(包括雙11當天),如果方案記憶體回收不徹底也會造成記憶體洩漏。是以我們利用多租戶進一步解決cpu隔離和記憶體回收兩個問題,改造後的隔離模式如下圖所示, 将算法方案之間以及算法與系統之間進行隔離:
首先結合AJDK的多租戶,利用cgroup進行徹底的cpu隔離。但這不是容易的事,對于TPP這樣複雜的容器更不容易,下文将介紹TPP多租戶改造的艱辛之路。
cgroup的cpu隔離主要有這麼幾種方式:cpuset,cpushares,cpu quota.
cpuset是cpu核為粒度的實體隔離,我們搜尋hippo排程docker容器的時候就是cpuset隔離,保證每個容器不互相影響。
cpushares設定使用者的cpu使用權重,權重越大則配置設定的cpu資源越多,它是個相對值。如3個程序的cpu shares分别為512,1024,1024,則他們滿負載時候配置設定到的cpu資源是1:2:2即20%:40%:40%。如果後兩個線程沒有滿負載,第一個share為512的可以使用超過20%。如果後兩個空閑,則第一個可以用到100%,一旦share為1024的程序要使用cpu,則512的程序會讓出cpu。
最後cpu quota設定了程序能使用的cpu最大比例絕對值,如cfs_period=100000,cfs_quota=50000,則程序能用到一個cpu core的50%,cfs=50000n則可以用到n個core的50%,總cpu可以使用到50%n/cores。
再來分析下AJDK的多租戶實作原理,首先看一個線程怎麼被cgroup限制cpu:
使用者建立了個租戶容器,這裡指定了租戶的cpu shares,記憶體上限,cpu使用率上限。然後使用者調用租戶容器去執行運算。
AJDK底層對多租戶的改造有這樣一個非常重要的原則:
線程1由租戶容器1建立,則線程1建立的其他線程都屬于容器1,這些線程整體cpu使用率受容器1的cgroup限制
這個原則會帶來什麼麻煩事呢,先看看租戶執行的代碼:
這裡首先檢查目前線程所屬租戶容器(下文以容器1代替)和目前執行租戶容器(下文以容器2代替)是否同一個,如果同一個執行執行runnable,這裡沒有性能開銷。如果不是麻煩來了,調用attach通過jni調用綁定目前線程到容器2的cgroup組,然後執行runnable,這時候線程的cpu就得到了租戶容器2的cgroup限制,runnable執行結束後再通過jni恢複線程和容器1的綁定。這裡有嚴重的性能開銷,即jni調用cgroup非常慢(實測50ms以上)。是以每個場景都要有一個線程池和一個租戶容器,線程池必須有一定的coresize和alive,防止頻繁new線程調用cgroup産生大耗時,場景線程必須由租戶容器建立。這樣線程池submit一個task就打到和普通線程池一樣的性能,我們為場景線程池定制了ThreadFactory,線上程池隔離的基礎上能輕松實作:
對于簡單應用到此為止就完成了多租戶改造,而對TPP來說則隻是完成了一小步。因為TPP接入了大量的二方服務,如IGraph, RTP, SUMMARY,很多HSF服務,Forest等,前文已經介紹過混布場景是為了複用二方服務,為每個場景克隆二方服務client會産生很大的記憶體開銷。這些複用的二方服務也管理了自己的線程池,結合前文所述租戶線程建立的其他線程也屬于這個租戶,一旦二方服務的線程由某個租戶建立然後被其他租戶複用則産生了cgroup切換的開銷,同時cpu配置設定也會錯亂。是以TPP還要對場景租戶線程和二方服務線進行隔離,這就涉及對一些核心高并發二方服務(雙11 IGraph峰值530w qps,SUMMARY 69w qps, RTP 75w qps)client的改造。原理很簡單,為二方服務的線程池增加定制的ThreadFactory:
對于大部分異步httpclient類的擴充client隻需要在構造時候增加設定threadFactory即可:
友情提示:多租戶的隔離方式不當使用會導緻主控端cgroup下目錄太多而負載過高,這個之前在sigma上有回報,容器銷毀時需要删除ajdk的程序cgroup目錄,需要應用自己操作,幸運的是hippo排程自動完成了這個工作。
最後看一下多租戶隔離的效果:
8核虛拟機下進行測試,非租戶隔離的情況下叢集内其他場景發生死循環,且源源不斷的有死循環請求進來,目前場景會因為并發數過大全部被限流
cpu基本被打滿(這裡對root租戶作了10%cpu保護,并不會800%,這裡實際略高于720%)
使用多租且限定租戶最大cpu使用50%,仍然建構一個場景死循環,可以看到目前場景隻是少量逾時,因為cgroup的排程也會造成場景rt上升,符合業務95%以上正确率的要求。
觀察容器cpu,正常場景800qps時容器cpu仍有餘量
接下去我們還會做多租戶的動态調控,對于問題場景自動降級,避免cpu的浪費。