閱讀目錄
緩存穿透
緩存雪崩
緩存擊穿
緩存熱點
緩存穿透是指緩存沒有起到作用,應用程式的請求大量到達了後端資料庫的情況。因為查詢時如果所需資料在緩存中不存在,便會到資料庫中進行再次查詢,當這樣的資料量太大時,說明我們的緩存系統根本沒有其他應有的作用。造成這樣情況的有兩個原因:
資料本身就不存在,我們通常用命中率用來衡量緩存系統設計的好壞,一般來說命中率能夠達到80%以上說明就不錯了。當對一些系統中不存在的資料進行查詢時,這部分請求就會直接轉發到資料庫中,如競争對手可能使用爬蟲進行惡意周遊查詢,導緻資料庫的壓力增大。
資料的生産需要經過大量的計算,耗時較長,這種情況常見于電商系統,如在商品列的分頁時,商品資料很龐大,且篩選的規則很多,要根據不同條件生成結果需要一定的時間,如果在大并發的情況下,瞬間的流量可能回拖垮資料庫。
解決方案
1.采用布隆過濾器,将所有可能存在的資料哈希到一個足夠大的bitmap中,一個一定不存在的資料會被 這個bitmap攔截掉,進而避免了對底層存儲系統的查詢壓力。
2.簡單粗暴的方法,如果一個查詢傳回的資料為空(不管是資料不存在,還是系統故障),我們仍然把這個空結果進行緩存,但它的過期時間會很短,最長不超過五分鐘。
緩存雪崩是指我們設定緩存時采用了相同的過期時間,導緻緩存失效後系統性能急劇下降的情況。緩存失效後,要重新生成緩存可能需要一定量的計算,這個過程無疑要耗費時間,對于高并發的系統來說,同一時間内大量的線程都查詢到緩存失效了,是以都在重新計算生成緩存,這時大量的計算可能會給伺服器帶來很大的壓力,導緻系統性能下降。
緩存失效時的雪崩效應對底層系統的沖擊非常可怕。
要解決這種情況通常有三種方式:
1.更新鎖
更新緩存時使用鎖機制,保證同一時間内隻能有一個線程進行更新,其餘線程要麼等待要麼傳回空值或者預設值等;
2.背景更新
對于緩存資料統一使用一個背景線程進行更新,這個線程對于一些設定過期時間的資料,定時查詢,發現如果接近過期時,便将其更新;
3.随機更新
簡單方案就是讓緩存失效時間分散開,比如我們可以在原有的失效時間基礎上增加一個随機值,比如1-5分鐘随機,這樣每一個緩存的過期時間的重複率就會降低,就很難引發集體失效的事件。
對于一些設定了過期時間的key,如果這些key可能會在某些時間點被超高并發地通路,是一種非常“熱點”的資料。這個時候,需要考慮一個問題:緩存被“擊穿”的問題,這個和緩存雪崩的差別在于這裡針對某一key緩存,前者則是很多key。緩存在某個時間點過期的時候,恰好在這個時間點對這個Key有大量的并發請求過來,這些請求發現緩存過期一般都會從後端DB加載資料并回設到緩存,這個時候大并發的請求可能會瞬間把後端DB壓垮。
造成問題的原因:
(1) 這個key是一個熱點key(例如一個重要的新聞,一個熱門的八卦新聞等等),是以這種key通路量可能非常大。
(2) 緩存的建構是需要一定時間的。(可能是一個複雜計算,例如複雜的sql、多次IO、多個依賴(各種接口)等等)
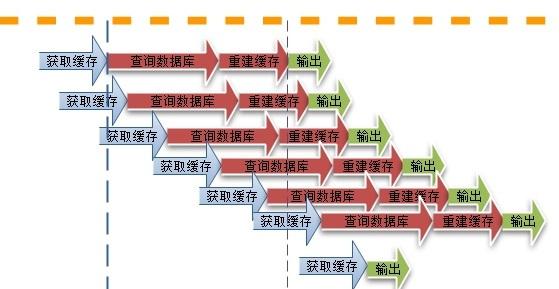
于是就會出現一個緻命問題:在緩存失效的瞬間,有大量線程來建構緩存(見下圖),造成後端負載加大,甚至可能會讓系統崩潰 。
解決方案
雖然緩存系統本身性能較高,但是針對一些高熱點的資料,同一時間内并發通路的請求太多時,也會出現瓶頸,此時可以将這些熱點資料庫儲存多個副本,以減輕對同一伺服器的讀取壓力。如熱點微網誌,可能存多分副本,存放在不同的緩存伺服器中,使用者通路時根據不同的地理位置或使用者特征通路不同的伺服器,以減輕單點壓力。再就是對于緩存系統,一般都會有個預熱環節,就是在正式上線前,使用預釋出的模式,先讓其生成一些常用的緩存資料,然後再切換到全站,這樣可以避免剛上線時瞬間的高流量對緩存系統進行沖擊。
![Apache配置SSLApache配置SSL[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)