對于我們開發的網站,如果網站的通路量非常大的話,那麼我們就需要考慮相關的并發通路問題了。而并發問題是絕大部分的程式員頭疼的問題,但話又說回來了,既然逃避不掉,那我們就坦然面對吧~今天就讓我們一起來研究一下常見的并發和同步吧。
為了更好的了解并發和同步,我們需要先明白兩個重要的概念:同步和異步
1、同步和異步的差別和聯系
同步,可以了解為在執行完一個函數或方法之後,一直等待系統傳回值或消息,這時程式是處于阻塞的,隻有接收到傳回的值或消息後才往下執行其它的指令。
異步,執行完函數或方法後,不必阻塞性地等待傳回值或消息,隻需要向系統委托一個異步過程,那麼當系統接收到傳回值或消息時,系統會自動觸發委托的異步過程,進而完成一個完整的流程。
同步在一定程度上可以看做是單線程,這個線程請求一個方法後就待這個方法給他回複,否則他不往下執行(死心眼)。
異步在一定程度上可以看做是多線程的(廢話,一個線程怎麼叫異步),請求一個方法後,就不管了,繼續執行其他的方法。
同步就是一件事一件事的做。
異步就是,做一件事情,不做其他事情。
例如:吃飯和說話,隻能一件事一件事的來,因為隻有一張嘴。但吃飯和聽音樂是異步的,因為,聽音樂并不影響我們吃飯。
對于Java程式員而言,我們會經常聽到同步關鍵字synchronized,假如這個同步的監視對象是類的話,那麼如果當一個對象通路類裡面的同步方法時,其它的對象如果想要繼續通路類裡面的這個同步方法的話,就會進入阻塞,隻有等前一個對象執行完該同步方法後,目前對象才能夠繼續執行該方法。這就是同步。
相反,如果方法前沒有同步關鍵字修飾的話,那麼不同的對象可以在同一時間通路同一個方法,這就是異步。
補充一下髒資料和不可重複讀的相關概念:
髒資料
髒讀就是指當一個事務正在通路資料,并且對資料進行了修改,而這種修改還沒有送出到資料庫中,這時,另外一個事務也通路這個資料,然後使用了這個資料。因為這個資料是還沒有送出的資料,那麼另外一個事務讀到的這個資料是髒資料(Dirty Data),依據髒資料所做的操作可能是不正确的。
不可重複讀
在一個事務内,多次讀同一資料。在這個事務還沒有結束時,另外一個事務也通路該資料。那麼,在第一個事務中的兩次讀資料之間,由于第二個事務的修改,那麼第一個事務兩次讀到的資料可能是不一樣的。這樣就發生了在一個事務内兩次讀到的資料是不一樣的,是以稱為是不可重複讀
2、如何處理并發和同步
今天講的如何處理并發和同步問題主要是通過鎖機制。
我們需要明白,鎖機制有兩個層面。
一種是代碼層次上的,如java中的同步鎖,典型的就是同步關鍵字synchronized,這裡我不再做過多的講解
另外一種是資料庫層次上的,比較典型的就是悲觀鎖和樂觀鎖。這裡我們重點講解的就是悲觀鎖(傳統的實體鎖)和樂觀鎖。
悲觀鎖(Pessimistic Locking)
悲觀鎖,正如其名,它指的是對資料被外界(包括本系統目前的其他事務,以及來自外部系統的事務處理)修改持保守态度。是以,在整個資料處理過程中,将資料處于鎖定狀态。
悲觀鎖的實作,往往依靠資料庫提供的鎖機制(也隻有資料庫層提供的鎖機制才能真正保證資料通路的排他性。否則,即使在本系統中實作了加鎖機制,也無法保證外部系統不會修改資料)。
一個典型的依賴資料庫的悲觀鎖調用:
這條 sql 語句鎖定了 account 表中所有符合檢索條件( name=”Erica” )的記錄。
本次事務送出之前(事務送出時會釋放事務過程中的鎖),外界無法修改這些記錄。
Hibernate 的悲觀鎖,也是基于資料庫的鎖機制實作。
下面的代碼實作了對查詢記錄的加鎖:
query.setLockMode 對查詢語句中,特定别名所對應的記錄進行加鎖(我們為 TUser 類指定了一個别名 “user” ),這裡也就是對傳回的所有 user 記錄進行加鎖。
觀察運作期 Hibernate 生成的 SQL 語句:
這裡 Hibernate 通過使用資料庫的 for update 子句實作了悲觀鎖機制。
Hibernate 的加鎖模式有:
Ø LockMode.NONE : 無鎖機制。
Ø LockMode.WRITE : Hibernate 在 Insert 和 Update 記錄的時候會自動擷取
Ø LockMode.READ : Hibernate 在讀取記錄的時候會自動擷取。
以上這三種鎖機制一般由 Hibernate 内部使用,如 Hibernate 為了保證 Update過程中對象不會被外界修改,會在 save 方法實作中自動為目标對象加上 WRITE 鎖。
Ø LockMode.UPGRADE :利用資料庫的 for update 子句加鎖。
Ø LockMode. UPGRADE_NOWAIT : Oracle 的特定實作,利用 Oracle 的 for update nowait 子句實作加鎖。
上面這兩種鎖機制是我們在應用層較為常用的,加鎖一般通過以下方法實作:
注意,隻有在查詢開始之前(也就是 Hiberate 生成 SQL 之前)設定加鎖,才會真正通過資料庫的鎖機制進行加鎖處理。否則,資料已經通過不包含 for update子句的 Select SQL 加載進來,所謂資料庫加鎖也就無從談起。
為了更好的了解select... for update的鎖表的過程,本人将要以mysql為例,進行相應的講解。
1、要測試鎖定的狀況,可以利用MySQL的Command Mode ,開二個視窗來做測試。
表的基本結構如下:
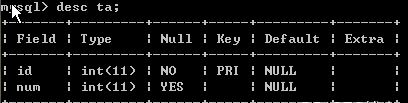
表中内容如下:
開啟兩個測試視窗,在其中一個視窗執行select * from ta for update0。然後在另外一個視窗執行update操作如下圖:

等到一個視窗commit後的圖檔如下:
到這裡,悲觀鎖機制你應該了解一些了吧~
需要注意的是for update要放到mysql的事務中,即begin和commit中,否則不起作用。
至于是鎖住整個表還是鎖住選中的行
至于hibernate中的悲觀鎖,使用起來比較簡單,這裡就不寫demo了~感興趣的自己查一下就ok了~、
樂觀鎖(Optimistic Locking)
相對悲觀鎖而言,樂觀鎖機制采取了更加寬松的加鎖機制。悲觀鎖大多數情況下依靠資料庫的鎖機制實作,以保證操作最大程度的獨占性。但随之而來的就是資料庫性能的大量開銷,特别是對長事務而言,這樣的開銷往往無法承受。
如一個金融系統,當某個操作員讀取使用者的資料,并在讀出的使用者資料的基礎上進行修改時(如更改使用者帳戶餘額),如果采用悲觀鎖機制,也就意味着整個操作過程中(從操作員讀出資料、開始修改直至送出修改結果的全過程,甚至還包括操作員中途去煮咖啡的時間),資料庫記錄始終處于加鎖狀态,可以想見,如果面對幾百上千個并發,這樣的情況将導緻怎樣的後果。 樂觀鎖機制在一定程度上解決了這個問題。
樂觀鎖,大多是基于資料版本 (Version )記錄機制實作。何謂資料版本?
即為資料增加一個版本辨別,在基于資料庫表的版本解決方案中,一般是通過為資料庫表增加一個 “version” 字段來實作。 讀取出資料時,将此版本号一同讀出,之後更時,對此版本号加一。此時,将送出資料的版本資料與資料庫表對應記錄的目前版本資訊進行比對,如果送出的資料版本号大于資料庫表目前版本号,則予以更新,否則認為是過期資料。
對于上面修改使用者帳戶資訊的例子而言,假設資料庫中帳戶資訊表中有一個 version 字段,目前值為 1 ;而目前帳戶餘額字段( balance )為 $100 。
1,操作員 A 此時将其讀出( version=1 ),并從其帳戶餘額中扣除 $50( $100-$50 )。
2, 在操作員 A 操作的過程中,操作員 B 也讀入此使用者資訊( version=1 ),并 從其帳戶餘額中扣除 $20 ( $100-$20 )。
3 ,操作員 A 完成了修改工作,将資料版本号加一( version=2 ),連同帳戶扣除後餘額( balance=$50 ),送出至資料庫更新,此時由于送出資料版本大于資料庫記錄目前版本,資料被更新,資料庫記錄 version 更新為 2 。
4 ,操作員 B 完成了操作,也将版本号加一( version=2 )試圖向資料庫送出資料( balance=$80 ),但此時比對資料庫記錄版本時發現,操作員B送出的資料版本号為 2 ,資料庫記錄目前版本也為 2 ,不滿足 “ 送出版本必須大于記錄目前版本才能執行更新 “ 的樂觀鎖政策。是以,操作員 B 的送出被駁回。 這樣,就避免了操作員 B 用基于version=1 的舊資料修改的結果覆寫操作員 A 的操作結果的可能。
從上面的例子可以看出,樂觀鎖機制避免了長事務中的資料庫加鎖開銷(操作員 A和操作員 B 操作過程中,都沒有對資料庫資料加鎖),大大提升了大并發量下的系統整體性能表現。 需要注意的是,樂觀鎖機制往往基于系統中的資料存儲邏輯,是以也具備一定的局限性。
如在上面例子中,由于樂觀鎖機制是在我們的系統中實作,來自外部系統的使用者餘額更新操作不受我們系統的控制,是以可能會造成髒資料被更新到資料庫中。在系統設計階段,我們應該充分考慮到這些情況出現的可能性,并進行相應調整(如将樂觀鎖政策在資料庫存儲過程中實作,對外隻開放基于此存儲過程的資料更新途徑,而不是将資料庫表直接對外公開)。 Hibernate 在其資料通路引擎中内置了樂觀鎖實作。如果不用考慮外部系統對數 據庫的更新操作,利用 Hibernate 提供的透明化樂觀鎖實作,将大大提升我們的生産力。
User.hbm.xml
注意 version 節點必須出現在 ID 節點之後。
這裡我們聲明了一個 version 屬性,用于存放使用者的版本資訊,儲存在 User 表的version中 。
optimistic-lock 屬性有如下可選取值:
Ø none
無樂觀鎖
Ø version
通過版本機制實作樂觀鎖
Ø dirty
通過檢查發生變動過的屬性實作樂觀鎖
Ø all
通過檢查所有屬性實作樂觀鎖
其中通過 version 實作的樂觀鎖機制是 Hibernate 官方推薦的樂觀鎖實作,同時也
是 Hibernate 中,目前唯一在資料對象脫離 Session 發生修改的情況下依然有效的鎖機
制。是以,一般情況下,我們都選擇 version 方式作為 Hibernate 樂觀鎖實作機制。
2 . 配置檔案hibernate.cfg.xml和UserTest測試類
hibernate.cfg.xml
UserTest.java
每次對 TUser 進行更新的時候,我們可以發現,資料庫中的 version 都在遞增。
下面我們将要通過樂觀鎖來實作一下并發和同步的測試用例:
這裡需要使用兩個測試類,分别運作在不同的虛拟機上面,以此來模拟多個使用者同時操作一張表,同時其中一個測試類需要模拟長事務。
UserTest2.java
操作流程及簡單講解:
首先啟動UserTest2.java測試類,在執行到Thread.sleep(10000);這條語句的時候,目前線程會進入睡眠狀态。在10秒鐘之内啟動UserTest這個類,在到達10秒的時候,我們将會在UserTest.java中抛出下面的異常:
UserTest2代碼将在 tx.commit() 處抛出 StaleObjectStateException 異常,并指出版本檢查失敗,目前事務正在試圖送出一個過期資料。通過捕捉這個異常,我 們就可以在樂觀鎖校驗失敗時進行相應處理。
3、常見并發同步案例分析
案例一:訂票系統案例,某航班隻有一張機票,假定有1w個人打開你的網站來訂票,問你如何解決并發問題(可擴充到任何高并發網站要考慮的并發讀寫問題)
問題:1w個人來通路,票沒出去前要保證大家都能看到有票,不可能一個人在看到票的時候别人就不能看了。到底誰能搶到,那得看這個人的“運氣”(網絡快慢等)
其次考慮的問題,并發,1w個人同時點選購買,到底誰能成交?總共隻有一張票。
首先我們容易想到和并發相關的幾個方案 :
鎖同步更多指的是應用程式的層面,多個線程進來,隻能一個一個的通路,java中指的是syncrinized關鍵字。鎖也有2個層面,一個層面是java中談到的對象鎖,用于線程同步;另外一個層面是資料庫的鎖;如果是分布式的系統,顯然隻能利用資料庫端的鎖來實作。
假定我們采用了同步機制或者資料庫實體鎖機制,如何保證1w個人還能同時看到有票,顯然會犧牲性能,在高并發網站中是不可取的。使用hibernate後我們提出了另外一個概念:樂觀鎖、悲觀鎖(即傳統的實體鎖);
采用樂觀鎖即可解決此問題。樂觀鎖意思是不鎖定表的情況下,利用業務的控制來決并發問題,這樣即保證資料的并發可讀性又保證儲存資料的排他性,保證性能的同時解決了并發帶來的髒資料問題。
hibernate中如何實作樂觀鎖?
前提:在現有表當中增加一個備援字段,version版本号, long類型
原理:
1)隻有目前版本号》=資料庫表版本号,才能送出
2)送出成功後,版本号version ++
實作很簡單:在ormapping增加一屬性optimistic-lock="version"即可,以下是樣例片段
案例二、股票交易系統、銀行系統,大資料量你是如何考慮的
首先,股票交易系統的行情表,每幾秒鐘就有一個行情記錄産生,一天下來就有(假定行情3秒一個) 股票數量×20×60*6 條記錄,一月下來這個表記錄數量多大? oracle中一張表的記錄數超過100w後 查詢性能就很差了,如何保證系統性能?
再比如,中國移動有上億的使用者量,表如何設計?把所有用于存在于一個表麼?
是以,大數量的系統,必須考慮表拆分-(表名字不一樣,但是結構完全一樣),通用的幾種方式:(視情況而定)
1)按業務分,比如 手機号的表,我們可以考慮 130開頭的作為一個表,131開頭的另外一張表 以此類推
2)利用oracle的表拆分機制做分表
3)如果是交易系統,我們可以考慮按時間軸拆分,當日資料一個表,曆史資料弄到其它表。這裡曆史資料的報表和查詢不會影響當日交易。
當然,表拆分後我們的應用得做相應的适配。單純的or-mapping也許就得改動了。比如部分業務得通過存儲過程等。
此外,我們還得考慮緩存。
這裡的緩存,指的不僅僅是hibernate,hibernate本身提供了一級二級緩存。這裡的緩存獨立于應用,依然是記憶體的讀取,假如我們能減少資料庫頻繁的通路,那對系統肯定大大有利的。
比如一個電子商務系統的商品搜尋,如果某個關鍵字的商品經常被搜,那就可以考慮這部分商品清單存放到緩存(記憶體中去),這樣不用每次通路資料庫,性能大大增加。
簡單的緩存大家可以了解為自己做一個hashmap,把常通路的資料做一個key,value是第一次從資料庫搜尋出來的值,下次通路就可以從map裡讀取,而不讀資料庫;專業些的目前有獨立的緩存架構比如memcached 等,可獨立部署成一個緩存伺服器。
4、常見的提高高并發下通路的效率的手段
首先要了解高并發的的瓶頸在哪裡?
1、可能是伺服器網絡帶寬不夠
2、可能web線程連接配接數不夠
3、可能資料庫連接配接查詢上不去。
根據不同的情況,解決思路也不同。
增加網絡帶寬,DNS域名解析分發多台伺服器。
負載均衡,前置代理伺服器nginx、apache等等
資料庫查詢優化,讀寫分離,分表等等
最後複制一些在高并發下需要常常需要處理的内容
1、盡量使用緩存,包括使用者緩存,資訊緩存等,多花點記憶體來做緩存,可以大量減少與資料庫的互動,提高性能。
2、用jprofiler等工具找出性能瓶頸,減少額外的開銷。
3、優化資料庫查詢語句,減少直接使用hibernate等工具的直接生成語句(僅耗時較長的查詢做優化)。
4、優化資料庫結構,多做索引,提高查詢效率。
5、統計的功能盡量做緩存,或按每天一統計或定時統計相關報表,避免需要時進行統計的功能。
6、能使用靜态頁面的地方盡量使用,減少容器的解析(盡量将動态内容生成靜态html來顯示)。
7、解決以上問題後,使用伺服器叢集來解決單台的瓶頸問題。
java高并發,如何解決,什麼方式解決
之前我将高并發的解決方法誤認為是線程或者是隊列可以解決,因為高并發的時候是有很多使用者在通路,導緻出現系統資料不正确、丢失資料現象,是以想到 的是用隊列解決,其實隊列解決的方式也可以處理。
比如我們在競拍商品、轉發評論微網誌或者是秒殺商品等,同一時間通路量特别大,隊列在此起到特别的作用,将 所有請求放入隊列,以毫秒計時機關,有序的進行,進而不會出現資料丢失系統資料不正确的情況。
今天我經過查資料,高并發的解決方法有兩種
一種是使用緩存、另一種是使用生成靜态頁面;
還有就是從最基礎的地方優化我們寫代碼減少不必要的資源浪費:
1.不要頻繁的new對象,對于在整個應用中隻需要存在一個執行個體的類使用單例模式.對于String的連接配接操作,使用StringBuffer或者StringBuilder.對于utility類型的類通過靜态方法來通路。
2. 避免使用錯誤的方式,如Exception可以控制方法推出,但是Exception要保留stacktrace消耗性能,除非必要不去使用 instanceof做條件判斷,盡量使用比的條件判斷方式.使用JAVA中效率高的類,比如ArrayList比Vector性能好。
首先緩存技術我一直沒有使用過,我覺得應該是在使用者請求時将資料儲存在緩存中,下次請求時會檢測緩存中是否有資料存在,防止多次請求伺服器,導緻伺服器性能降低,嚴重導緻伺服器崩潰,這隻是我自己的了解,詳細的資料還是需要在網上收集;
使用生成靜态頁面我想大家應該不陌生,我們見過很多網站在請求的時候頁面的字尾已經變了,如“http://developer.51cto.com/art/201207/348766.htm”該頁面其實是一個伺服器請求位址,在轉換成htm後,通路速度将提升,因為靜态頁面不帶有伺服器元件。
在這裡我就多多介紹一下:
一、什麼是頁面靜态化:
簡單的說,我們如果通路一個連結 ,伺服器對應的子產品會處理這個請求,轉到對應的jsp界面,最後生成我們想要看到的資料。
這其中的缺點是顯而易見的:因為每次請求伺服器都會進行處理,如果有太多的高并發請求,那麼就會加重應用伺服器的壓力,弄不好就把伺服器搞down 掉了。
那麼如何去避免呢?
如果我們把對 test.do 請求後的結果儲存成一個 html 檔案,然後每次使用者都去通路 ,這樣應用伺服器的壓力不就減少了?
那麼靜态頁面從哪裡來呢?總不能讓我們每個頁面都手動處理吧?這裡就牽涉到我們要講解的内容了,靜态頁面生成方案… 我們需要的是自動的生成靜态頁面,當使用者通路 ,會自動生成 test.html ,然後顯示給使用者。
二、下面我們在簡單介紹一下要想掌握頁面靜态化方案應該掌握的知識點:
1、 基礎- URL Rewrite
什麼是 URL Rewrite 呢 ? URL 重寫。用一個簡單的例子來說明問題:輸入網址 ,但是實際上通路的卻是 abc.com/test.action,那我們就可以說 URL 被重寫了。這項技術應用廣泛,有許多開源的工具可以實作這個功能。
2、 基礎- Servlet web.xml
如果你還不知道 web.xml 中一個請求和一個 servlet 是如何比對到一起的,那麼請搜尋一下 servlet 的文檔。這可不是亂說呀,有很多人就認為 /xyz/*.do 這樣的比對方式能有效。
如果你還不知道怎麼編寫一個 servlet ,那麼請搜尋一下如何編寫 servlet.這可不是說笑呀,在各種內建工具漫天飛舞的今天,很多人都不會去從零編寫一個 servlet了。
三、基本的方案介紹
其中,對于 URL Rewriter的部分,可以使用收費或者開源的工具來實作,如果 url不是特别的複雜,可以考慮在 servlet 中實作,那麼就是下面這個樣子:
總 結
其實我們在開發中都很少考慮這種問題,直接都是先将功能實作,當一個程式員在幹到1到2年,就會感覺光實作功能不是最主要的,安全性能、品質等等才是一個開發人員最該關心的。今天我所說的是高并發。
我的解決思路是:
1、采用分布式應用設計
2、分布式緩存資料庫
3、代碼優化
Java高并發的例子
具體情況是這樣: 通過java和資料庫,自己實作序列自動增長。(代碼如下)
id_table表結構, 主要字段:
具體使用者,都是通過類似這種方式:IdHelpTool.getNextStringValue("PAY_LOG");來調用。
問題:
(1) 當出現并發時, 有時會擷取重複的ID;
(2) 由于伺服器做了相關一些設定,有時調用這個方法,好像還會導緻逾時。
為了解決問題(1), 考慮過在方法getNextStringValue上,也加上synchronized , 同步關鍵字過多,會不會更導緻逾時?
跪求大俠提供個解決問題的大概思路!!!
解決思路一:
1、推薦 https://github.com/adyliu/idcenter
2、可以通過第三方redis來實作。
解決思路二:
1、出現重複ID,是因為髒讀了,并發的時候不加 synchronized 比如會出現問題
2、但是加了 synchronized ,性能急劇下降了,本身 java 就是多線程的,你把它單線程使用,不是明智的選擇。同時,如果分布式部署的時候,加了 synchronized 也無法控制并發
3、調用這個方法,出現逾時的情況,說明你的并發已經超過了資料庫所能處理的極限,資料庫無限等待導緻逾時
基于上面的分析,建議采用線程池的方案,支付寶的單号就是用的線程池的方案進行的。
資料庫 update 不是一次加1,而是一次加幾百甚至上千,然後取到的這 1000個序号,放線上程池裡慢慢配置設定即可,能應付任意大的并發,同時保證資料庫沒任何壓力。