============================================================================================
《機器學習實戰》系列部落格是部落客閱讀《機器學習實戰》這本書的筆記,包含對其中算法的了解和算法的Python代碼實作
另外部落客這裡有機器學習實戰這本書的所有算法源代碼和算法所用到的源檔案,有需要的留言
一、什麼是看KNN算法?
二、KNN算法的一般流程
三、KNN算法的Python代碼實作
一:什麼是看KNN算法?
kNN算法全稱是k-最近鄰算法(K-Nearest Neighbor)
kNN算法的核心思想是如果一個樣本在特征空間中的k個最相鄰的樣本中的大多數屬于某一個類别,則該樣本也屬于這個類别,并具有這個類别上樣本的特性。該方法在确定分類決策上隻依據最鄰近的一個或者幾個樣本的類别來決定待分樣本所屬的類别。
下邊舉例說明:
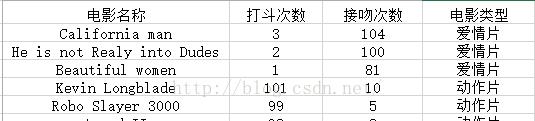
即使不知道未知電影屬于哪種類型,我們也可以通過某種方法計算出來,如下圖

現在我們得到了樣本集中與未知電影的距離,按照距離的遞增順序,可以找到k個距離最近的電影,假定k=3,則三個最靠近的電影是和he is not realy into Dudes,Beautiful women, California man kNN算法按照距離最近的三部電影類型決定未知電影類型,這三部都是愛情片,是以未知電影的類型也為愛情片
二:KNN算法的一般流程
step.1---初始化距離為最大值
step.2---計算未知樣本和每個訓練樣本的距離dist
step.3---得到目前K個最臨近樣本中的最大距離maxdist
step.4---如果dist小于maxdist,則将該訓練樣本作為K-最近鄰樣本
step.5---重複步驟2、3、4,直到未知樣本和所有訓練樣本的距離都算完
step.6---統計K-最近鄰樣本中每個類标号出現的次數
step.7---選擇出現頻率最大的類标号作為未知樣本的類标号
調用方式:打開CMD,進入kNN.py檔案所在的目錄,輸入Python,依次輸入import kNN group,labels = kNN.createDataSet() kNN.classify0([0,0],group,lables,3)