摘要:講師通過介紹MongoDB的日志審計和慢查詢、解析即将商業化的MongoDB索引推薦功能,利用MapReduce&Flink做審計日志分析、以及通過建立索引的最佳實踐的例子讓大家了解阿裡雲是如何利用大資料對MongoDB裡面的資料和資訊做分析的。
以下内容根據演講嘉賓視訊分享以及PPT整理而成。
本次的分享主要分為以下四個部分:
一、MongoDB日志審計和慢查詢介紹
二、MongoDB索引推薦解析
三、利用mapreduce&flink做sql分析
四、建立索引的最佳實踐
<b>MongoDB的特性</b>
MongoDB是一個介于關系資料庫和非關系資料庫之間的産品,是非關系資料庫當中功能最豐富,最像關系資料庫的。MongoDb具有如下主要特性:
1. 支援單文檔事務;
2. 靈活的json格式存儲,最接近真實對象模型;
3. 高可用,運維簡單,故障自動切換(自帶讀寫功能,和指讀功能);
4. 可擴充分片叢集海量資料存儲;
5. 支援多種引擎wiretiger rocksdb;
6. 适用場景:遊戲,物流,電商,社交等。
<b>MongoDB的日志審計和慢查詢介紹</b>
在使用MongoDB的使用過程當中,經常會遇到如下問題:
1. 查詢逾時報錯;
2. 資料庫響應慢;
3. CPU達到100%;
以上是使用者經常回報的性能問題,出現問題的原因一般是因為使用者的某一個查詢進行全表掃描導緻性能差,或者使用的索引不夠好。
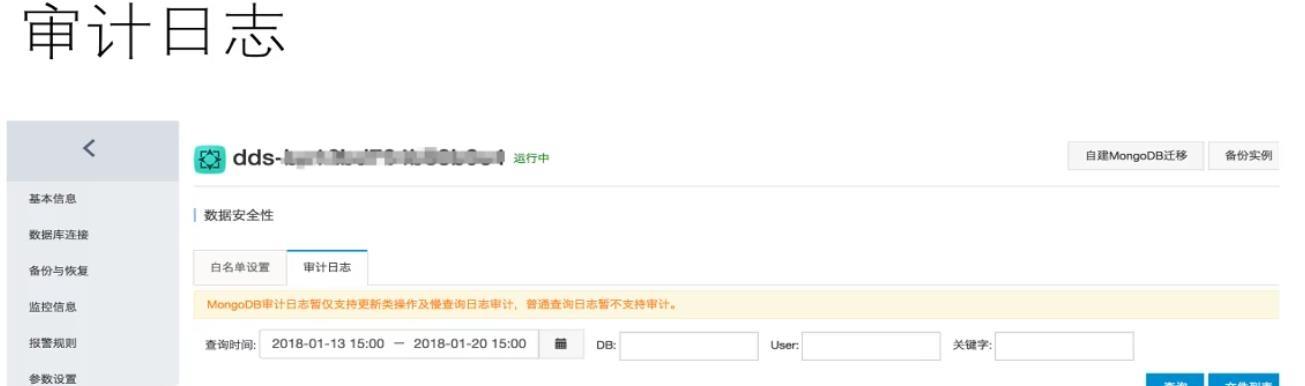
使用者如何知道哪些SQL導緻進行全表掃描?這些都可以在審計日志中檢視。當選擇MongoDB服務時,在資料安全性中,審計日志的标簽下就可看到某一個時間段内這個資料庫所有的更新,删除包括慢查詢的SQL。使用者可通過更新和删除操作來判斷資料庫有沒有惡意操作以及非預期操作。審計日志圖如下所示:

在審計日志中,有多種更新的方式(例如update、find and modify),第二列是操作的執行時間,第三列是通路的DB以及使用的賬号,從這使用者即可通過審計日志發現資料庫内容的變更情況,并且對這些更新操作來做一個審計,來發現是否有誤操作和非預期操作。
atype等于slowOp的一些查詢日志就是慢查詢,一般超過100毫秒的SQL會被記為慢查詢并出現在審計日志裡,使用者再通過slowOp這個關鍵字去查找就能找出所有的慢查詢。這個效果和使用者通過直連資料庫的查詢效果是一樣的。并且通過審計日志查詢,對使用者資料庫的使用沒有任何性能影響。
<b>MongoDB索引推薦解析</b>
當發現MongoDB存在慢查詢的時候,傳統優化慢查詢的方法一般是人工優化慢查詢、建立複合索引等方法。然而使用直連資料庫去查的話,會對使用者的資料庫産生性能開銷,并且複合索引列的順序不同,産生的優化效果差異也大。除此之外,傳統優化還有以下不足:
1. MongoDB的DBA極少;
2. 慢查詢缺少統計;
3. 成本高。
正因如此,阿裡雲推出了MongoDB索引推薦服務:
1. 對慢查詢進行統計和索引推薦;
2. 對不支援索引推薦的指令進行改寫或者提示;
3. 對索引推薦的效果進行定量分析;
4. 索引推薦服務在四月份左右商業化。
索引推薦服務經曆了兩代架構的調整:
第一代架構調整是基于批量的計算引擎來得到的一些計算結果,架構圖如上所示。
之是以要有第二代架構是因為第一代架構隻支援批量的運算,運作的時間也較長,比較适用于每天做一次的離線分析,并且使用者對實施性的要求變高了。第二代是基于流式的引擎,主要是利用flink做的索引推薦的分析服務,它同樣是在MongoDB上面做一些采集。
<b>利用MapReduce&Flink做審計日志分析</b>
MapReduce是一個并行程式設計模型與方法(Programming Model & Methodology)。它借助于函數式程式設計語言Lisp的設計思想,提供了一種簡便的并行程式設計方法,用Map和Reduce兩個函數程式設計實作基本的并行計算任務,提供了抽象的操作和并行程式設計接口,以簡單友善地完成大規模資料的程式設計和計算處理。
Flink流式引擎的核心是一個流式的資料流執行引擎,其針對資料流的分布式計算提供了資料分布、資料通信以及容錯機制等功能,Flink流式引擎的主要特點如下:
1、連續流操作符——在資料到達時進行處理,沒有任何資料收集或處理延遲;
2、支援SQL;
3、提供恰好一次的保證,及每條記錄都僅處理一次;
4、提供一個非常高的吞吐量;
5、容錯和開銷都非常低;
索引推薦服務會從中分類出如下四種模型:
1、CURD模型;
2、索引模型;
3、表模型;
4、資料模型。
這些模型期望達到的監控使用者有沒有做一些非預期的更新和删除操作、根據提供的索引或者是删除一些冷索引達到提升性能的目标、通過對冷表更高效的壓縮來達到減少空間的目标。
索引推薦的實作主要是通過每天離線推薦服務,具體的實作包括以下四個部分:
1、擷取審計日志;
2、對審計日志進行查詢模闆化的處理;
3、選出核心慢查詢(基于統計分析選出最值得優化的慢查詢);
4、推薦索引和查詢的改寫。
<b>建立索引的最佳實踐</b>
接下來通過一個執行個體來實踐操作:
例如查詢樣例如下:
db.staff.find(
{
“birth_city:{
“$in”:[“beijing”,”shenzhen”]
},
”work_city”:”hangzhou”,
”age”:{
“$gte”:20
}
}).sort({“birthday”:1})
通過模闆化,去掉業務資料:
集合名:staff
操作符:query
查詢指令:
{“birth_city”:{“$in”,”<val>”},”work_city”:<val>,”age”:{“$gte”:”<val>”}}
排序指令:{“birthday”:1}
通過這樣的方法,使用者類似的查詢都會統一為這樣的模版,通過這些模版,對于執行時間超過100ms的模闆化的查詢,統計以下資料:
1、平均執行時長;
2、平均文檔掃描次數;
3、平均索引掃描次數;
4、平均傳回行數;
5、是否使用記憶體排序;
6、最後執行時間;
7、執行計劃。
得到這些統計的資料以後,選擇最值得優化的慢查詢,這裡有個最簡單的規則:等号操作的列要放在in操作列的前面,in操作列要放在sort操作列的前面,sort操作列又要放在範圍操作列的前面,當使用者建立索引的時候,希望遵循這個規則去建立。例如如上所說的例子:
最終建立索引:{“work_city”:1,”birth_city”:1,”birthday”:1,”age”:1}
因為work_city列是等号操作,是以放在第一個位置,根據規則,以此類推birth_city放在第二個位置等等。
目前的索引推薦功能,是以pdf的方式發送給使用者,效果如上圖所示。
推薦的索引會自動克隆出一個使用者不可見的MongoDB資料庫,系統會在該資料庫建立索引,來比對索引建立前後的計劃、執行時間有無降低、慢查詢有無消除等。該查詢結果資訊會回報給使用者,讓使用者決策該索引是否需要建立。目前定量分析是免費提供給使用者使用。
截至到目前,索引推薦服務試用内測了三個月,經曆了兩代架構調整,按照推薦去建索引的使用者,慢查詢量明顯下降。有使用者按照推薦建索引,每天減少90多萬條慢查詢,占其慢查詢總量99.5%以上。