Spark之是以在機器學習方面具有得天獨厚的優勢,有以下幾點原因:
(1)機器學習算法一般都有很多個步驟疊代計算的過程,機器學習的計算需要在多次疊代後獲得足夠小的誤差或者足夠收斂才會停止,疊代時如果使用Hadoop的MapReduce計算架構,每次計算都要讀/寫磁盤以及任務的啟動等工作,這回導緻非常大的I/O和CPU消耗。而Spark基于記憶體的計算模型天生就擅長疊代計算,多個步驟計算直接在記憶體中完成,隻有在必要時才會操作磁盤和網絡,是以說Spark正是機器學習的理想的平台。
(2)從通信的角度講,如果使用Hadoop的MapReduce計算架構,JobTracker和TaskTracker之間由于是通過heartbeat的方式來進行的通信和傳遞資料,會導緻非常慢的執行速度,而Spark具有出色而高效的Akka和Netty通信系統,通信效率極高。
MLlib(Machine Learnig lib) 是Spark對常用的機器學習算法的實作庫,同時包括相關的測試和資料生成器。Spark的設計初衷就是為了支援一些疊代的Job, 這正好符合很多機器學習算法的特點。在Spark官方首頁中展示了Logistic Regression算法在Spark和Hadoop中運作的性能比較,如圖下圖所示。

可以看出在Logistic Regression的運算場景下,Spark比Hadoop快了100倍以上!
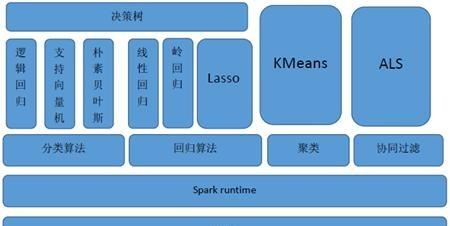
MLlib目前支援4種常見的機器學習問題: 分類、回歸、聚類和協同過濾,MLlib在Spark整個生态系統中的位置如圖下圖所示。
MLlib基于RDD,天生就可以與Spark SQL、GraphX、Spark Streaming無縫內建,以RDD為基石,4個子架構可聯手建構大資料計算中心!
MLlib是MLBase一部分,其中MLBase分為四部分:MLlib、MLI、ML Optimizer和MLRuntime。
l ML Optimizer會選擇它認為最适合的已經在内部實作好了的機器學習算法和相關參數,來處理使用者輸入的資料,并傳回模型或别的幫助分析的結果;
l MLI 是一個進行特征抽取和進階ML程式設計抽象的算法實作的API或平台;
l MLlib是Spark實作一些常見的機器學習算法和實用程式,包括分類、回歸、聚類、協同過濾、降維以及底層優化,該算法可以進行可擴充; MLRuntime 基于Spark計算架構,将Spark的分布式計算應用到機器學習領域。
下圖是MLlib算法庫的核心内容。
本文轉自張昺華-sky部落格園部落格,原文連結:http://www.cnblogs.com/bonelee/p/7125614.html,如需轉載請自行聯系原作者