<a></a>
1.資料框:機器學習接口使用來自Spark SQL的資料框形式資料作為資料集,它可以處理多種資料類型。比如,一個資料框可以有不同的列存儲文本、特征向量、标簽值和預測值。
2.轉換器:轉換器是将一個資料框變為另一個資料框的算法。比如,一個機器學習模型就是一個轉換器,它将帶有特征資料框轉為預測值資料框。
3.估計器:估計器是拟合一個資料框來産生轉換器的算法。比如,一個機器學習算法就是一個估計器,它訓練一個資料框産生一個模型。
4.管道:一個管道串起多個轉換器和估計器,明确一個機器學習工作流。
5.參數:管道中的所有轉換器和估計器使用共同的接口來指定參數。
工作原理
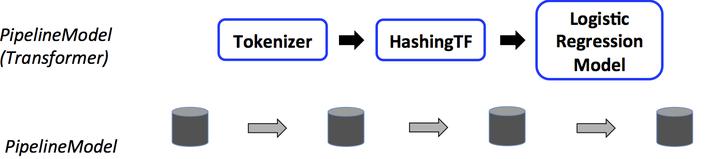
管道由一系列有順序的階段指定,每個狀态時轉換器或估計器。每個狀态的運作是有順序的,輸入的資料框通過每個階段進行改變。在轉換器階段,transform()方法被調用于資料框上。對于估計器階段,fit()方法被調用來産生一個轉換器,然後該轉換器的transform()方法被調用在資料框上。
下面的圖說明簡單的文檔處理工作流的運作。
本文轉自張昺華-sky部落格園部落格,原文連結:http://www.cnblogs.com/bonelee/p/7810266.html,如需轉載請自行聯系原作者
![筆試面試題目:滑動視窗(二)[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)