目前,Spark已經發展成為包含衆多子項目的大資料計算平台。 伯克利将Spark的整個生态系統稱為伯克利資料分析棧(BDAS)。 其核心架構是Spark,同時BDAS涵蓋支援結構化資料SQL查詢與分析的查詢引擎Spark SQL和Shark,提供機器學習功能的系統MLbase及底層的分布式機器學習庫MLlib、 并行圖計算架構GraphX、 流計算架構Spark Streaming、 采樣近似計算查詢引擎BlinkDB、 記憶體分布式檔案系統Tachyon、 資源管理架構Mesos等子項目。 這些子項目在Spark上層提供了更高層、 更豐富的計算範式。
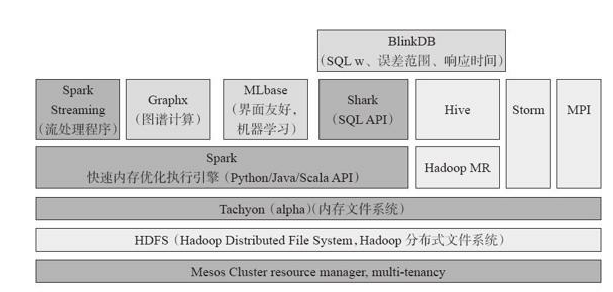
伯克利資料分析棧(BDAS)項目結構圖
下面對BDAS的各個子項目進行更詳細的介紹
(1)Spark
Spark是整個BDAS的核心元件,是一個大資料分布式程式設計架構,不僅實作了MapReduce的算子map函數和reduce函數及計算模型,還提供更為豐富的算子,如filter、 join、groupByKey等。 Spark将分布式資料抽象為彈性分布式資料集(RDD),實作了應用任務排程、 RPC、 序列化和壓縮,并為運作在其上的上層元件提供API。 其底層采用Scala這種函數式語言書寫而成,并且所提供的API深度借鑒Scala函數式的程式設計思想,提供與Scala類似的程式設計接口。
下圖是Spark的處理流程(主要對象為RDD)。

Spark的任務處理流程圖
Spark将資料在分布式環境下分區,然後将作業轉化為有向無環圖(DAG),并分階段進行DAG的排程和任務的分布式并行處理。
(2)Shark
Shark是建構在Spark和Hive基礎之上的資料倉庫。 目前,Shark已經完成學術使命,終止開發,但其架構和原理仍具有借鑒意義。 它提供了能夠查詢Hive中所存儲資料的一套SQL接口,相容現有的Hive QL文法。 這樣,熟悉Hive QL或者SQL的使用者可以基于Shark進行快速的Ad-Hoc、 Reporting等類型的SQL查詢。 Shark底層複用Hive的解析器、 優化器以及中繼資料存儲和序列化接口。 Shark會将Hive QL編譯轉化為一組Spark任務,進行分布式運算。
(3)Spark SQL
Spark SQL提供在大資料上的SQL查詢功能,類似于Shark在整個生态系統的角色,它們可以統稱為SQL on Spark。 之前,Shark的查詢編譯和優化器依賴于Hive,使得Shark不得不維護一套Hive分支,而Spark SQL使用Catalyst做查詢解析和優化器,并在底層使用Spark作為執行引擎實作SQL的Operator。 使用者可以在Spark上直接書寫SQL,相當于為Spark擴充了一套SQL算子,這無疑更加豐富了Spark的算子和功能,同時Spark SQL不斷相容不同的持久化存儲(如HDFS、 Hive等),為其發展奠定廣闊的空間。
(4)Spark Streaming
Spark Streaming通過将流資料按指定時間片累積為RDD,然後将每個RDD進行批處理,進而實作大規模的流資料處理。 其吞吐量能夠超越現有主流流處理架構Storm,并提供豐富的API用于流資料計算。
(5)GraphX
GraphX基于BSP模型,在Spark之上封裝類似Pregel的接口,進行大規模同步全局的圖計算,尤其是當使用者進行多輪疊代時,基于Spark記憶體計算的優勢尤為明顯。
(6)Tachyon
Tachyon是一個分布式記憶體檔案系統,可以了解為記憶體中的HDFS。 為了提供更高的性能,将資料存儲剝離Java Heap。 使用者可以基于Tachyon實作RDD或者檔案的跨應用共享,并提供高容錯機制,保證資料的可靠性。
(7)Mesos
Mesos是一個資源管理架構(注:Spark自帶的資源管理架構是Standalone。),提供類似于YARN的功能。 使用者可以在其中插件式地運作Spark、 MapReduce、 Tez等計算架構的任務。 Mesos會對資源和任務進行隔離,并實作高效的資源任務排程。
請移步,
(8)BlinkDB
BlinkDB是一個用于在海量資料上進行互動式SQL的近似查詢引擎。 它允許使用者通過在查詢準确性和查詢響應時間之間做出權衡,完成近似查詢。 其資料的精度被控制在允許的誤差範圍内。 為了達到這個目标,BlinkDB的核心思想是:通過一個自适應優化架構,随着時間的推移,從原始資料建立并維護一組多元樣本;通過一個動态樣本選擇政策,選擇一個适當大小的示例,然後基于查詢的準确性和響應時間滿足使用者查詢需求。
● Spark Core 實作了Spark 的基本功能,包含任務排程、記憶體管理、錯誤恢複、與存儲系統互動等子產品。
● RDD(resilient distributed dataset,彈性分布式資料集)的API 定義。RDD是一個抽象的資料集,提供對資料并行和容錯的處理。初次使用RDD時,其接口有點類似Scala的Array,提供map,filter,reduce等操作。但是,不支援随機通路。剛開始不太習慣,但是逐漸熟悉函數程式設計和RDD 的原理後,發現随機通路資料的場景并不常見。
● Spark SQL 是Spark 用來操作結構化資料的程式包。
● Spark SQL 直接相容Hive SQL。
● 多資料源(Hive表、Parquet、JSON等);Spark SQL 可以操作Hive表,可以讀取Parquet檔案(列式存儲結構),可以讀取JSON檔案,還可以處理hdfs上面的檔案。
● SQL與RDD程式設計結合使用。
● 從Shark演變到Spark SQL。
● Spark 提供的對實時資料進行流式計算的元件。
● 微批處理(Storm、Flink)-------從批處理到流處理
● Spark 提供的包含常見機器學習(ML)功能的庫。
● 分類、回歸、聚類、協同過濾等
● 模型評估、資料導入等額外的支援功能
● Mahout(Runs on distributed Spark, H2O, and Flink)
● GraphX是Spark 提供的圖計算和圖挖掘的庫。
● 與Spark Streaming 和Spark SQL 類似,GraphX 也擴充了Spark 的RDD API,能用來建立一個頂點和邊都包含任意屬性的有向圖
● GraphX還支援針對圖的各種計算和常見的圖算法。
本文轉自大資料躺過的坑部落格園部落格,原文連結:http://www.cnblogs.com/zlslch/p/5706978.html,如需轉載請自行聯系原作者