Hive支援索引,但是Hive的索引與關系型資料庫中的索引并不相同,比如,Hive不支援主鍵或者外鍵。
Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如減少MapReduce任務中需要讀取的資料塊的數量。
在可以預見到分區資料非常龐大的情況下,索引常常是優于分區的。
部落客我推薦各位博文們通過查閱Hive文檔對Hive表的索引進行更深入的了解。
需要時刻記住的是,Hive并不像事物資料庫那樣針對個别的行來執行查詢、更新、删除等操作。這些操作依賴高效的索引來實作高性能。
Hive是一種批處理工具,通常用在多任務節點的場景下,快速地掃描大規模資料。關系型資料庫則适用于典型的單機運作、I/O密集型的場景。
Hive通過并行化來實作性能,是以Hive更适用于全表掃描這樣的操作,而不是像使用關系型資料庫一樣操作。
為什麼要建立索引?
Hive的索引目的是提高Hive表指定列的查詢速度。
沒有索引時,類似'WHERE tab1.col1 = 10' 的查詢,Hive會加載整張表或分區,然後處理所有的rows,
但是如果在字段col1上面存在索引時,那麼隻會加載和處理檔案的一部分。
與其他傳統資料庫一樣,增加索引在提升查詢速度時,會消耗額外資源去建立索引和需要更多的磁盤空間存儲索引。
Hive 0.7.0版本中,加入了索引。Hive 0.8.0版本中增加了bitmap索引。
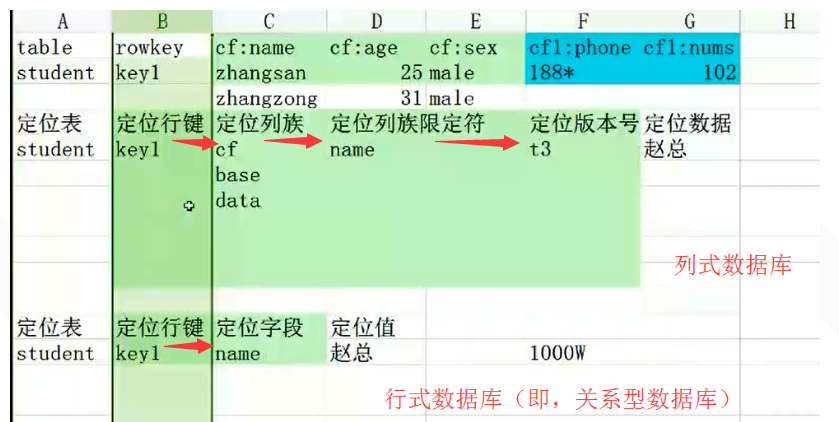
Hive裡的2維坐标系統(第一步定位行鍵 -> 第二步定位列修飾符)
HBase裡的4維坐标系統(第一步定位行鍵 -> 第二步定位列簇 -> 第三步定位列修飾符 -> 第四步定位時間戳)
行鍵,相當于第一步級索引。
列簇,相當于第二步級索引。
列修飾符,相當于第三步級索引。
時間戳,相當于第四步級索引。
預習案例
說明:
原表是user
建立索引後的表是user_index_table
索引是user_index
先建立原表
create table user(
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
往原表裡導入資料
LOAD DATA LOCAL INPATH '/export1/tmp/wyp/row.txt' OVERWRITE INTO TABLE user;
給原表做個測試
SELECT * FROM user where id =500000;
Total MapReduce CPU Time Spent: 5 seconds 630 msec
OK
500000 wyp.
Time taken: 14.107 seconds, Fetched: 1 row(s)
可以看出,一共用了14.107s。
在原表user上建立索引user_index,得到建立索引後的表user_index_table
CREATE INDEX user_index ON TABLE user(id) AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' WITH deferred REBUILD IN TABLE user_index_table;
或者如下寫都是一樣的,建議如下寫
hive > create index user_index on table user(id)
> as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
> with deferred rebuild
> IN TABLE user_index_table;
給原表user更新資料
ALTER INDEX user_index on user REBUILD;
删除索引
DROP INDEX user_index on user;
檢視索引
SHOW INDEX on user;
建立表和索引案例
步驟一:建立索引測試表
CREATE TABLE index_test(
id INT,
name STRING
)
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED FILEDS TERMINATED BY ',';
說明:
建立一個索引測試表 index_test,dt作為分區屬性,
“ROW FORMAT DELIMITED FILEDS TERMINATED BY ','” 表示用逗号分割字元串,預設為‘\001’。
步驟二:建立臨時索引表
create table index_tmp(
name STRING,
dt STRING
說明:臨時索引表是table index_tmp
步驟三:加載資料到臨時索引表中
load data local inpath '/home/hadoop/djt/test.txt' into table index_tmp;
步驟四:設定 Hive 的索引屬性來優化索引查詢
set hive.exec.dynamic.partition.mode=nonstrict;----設定所有列為 dynamic partition
set hive.exec.dynamic.partition=true;----使用動态分區
步驟五:查詢臨時索引表中的資料,插入到索引測試表中。
insert overwrite table index_test partition(dt) select id,name,dt from index_tmp;
步驟六:使用 索引測試表,在屬性 id 上建立一個索引
create index index1_index_test on table index_test(id) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' WITH DEFERERD REBUILD;
建議如下寫
create index index1_index_test on table index_test(id)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
WITH DEFERERD REBUILD;
索引是index1_index_test
索引測試表是 index_test
在索引測試表的屬性id上建立的索引
步驟七:填充索引測試表的索引資料
alter index index1_index_test on index_test rebuild;
步驟八:檢視索引測試表的建立的索引
show index on index_test
步驟九:檢視索引測試表的分區資訊
show partitions index_test;
步驟十:檢視索引測試表的索引資料
$ hadoop fs -ls /usr/hive/warehouse/default_index_test_index1_index_test_
步驟十一:删除索引測試表的索引
drop index index1_index_test on index_test;
show index on index_test;
步驟十二:索引測試表的索引資料也被删除
no such file or directory
步驟十三:修改配置檔案資訊
hive.optimize.index.filter 和 hive.optimize.index.groupby 參數預設是 false。
使用索引的時候必須把這兩個參數開啟,才能起到作用。
hive.optimize.index.filter.compact.minsize 參數
為輸入一個緊湊的索引将被自動采用最小尺寸、預設5368709120(以位元組為機關)。
本文轉自大資料躺過的坑部落格園部落格,原文連結:http://www.cnblogs.com/zlslch/p/6105294.html,如需轉載請自行聯系原作者
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)