處理缺失值--完整執行個體分析(行删除)
在完整執行個體分析中,隻有每個變量都包含了有效資料值的觀測才會保留下來做進一步的分析。實際上,這樣會導緻包含一個或多個缺失值的任意一行都會被删除,是以常稱作行删除法(listwise)、個案删除(case-wise)或剔除。
函數complete.cases()可以用來存儲沒有缺失值的資料框或者矩陣形式的執行個體(行):
newdata <- mydata[complete.cases(mydata),]
同樣的結果可以用na.omit函數獲得:
newdata <- na.omit(mydata)
兩行代碼表示的意思都是:mydata中所有包含缺失資料的行都被删除,然後結果才存儲到
newdata中。
現假設你對睡眠研究中變量間的關系很感興趣。計算相關系數前,使用行删除法可删除所有
含有缺失值的動物:
options(digits=1)
cor(na.omit(sleep))
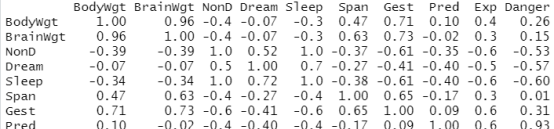
結果分析:表中的相關系數僅通過所有變量均為完整資料的42種動物計算得來。(注意代碼cor(sleep, use="complete.obs")可生成同樣的結果。)
若想研究壽命和妊娠期對睡眠中做夢時長的影響,可應用行删除法的線性回歸:
fit <- lm(Dream ~ Span + Gest, data=na.omit(sleep))
summary(fit)

結果分析:此處可以看到,動物妊娠期越短,做夢時長越長(控制壽命不變);而控制妊娠期不變時,壽命與做夢時長不相關。整個分析基于有完整資料的42個執行個體。
作者:zhang-X,轉載請注明原文連結