結構
Hive 是建立在hadoop上的資料倉庫架構,它提供了一系列的工具,可以進行資料提取轉換加載(這個過程叫做ETL),這是一種可以存儲,查詢和分析存儲在hadoop中的大規模資料的機制.Hive定義了簡單的類SQL查詢語句 成為hql,他允許資料SQL的使用者查詢資料.同時 這個語言也允許資料mapreduce開發者的開發自定義mapper和reducer來處理内建的複雜的分析工作.
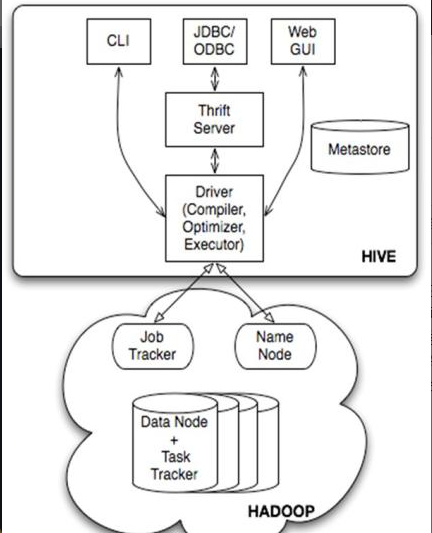
Hive的核心
hive的核心是Driver驅動引擎,驅動驅動有四部分組成:
1>解釋器:解釋器的作用是将HiveSQL語句轉換為文法樹(AST)
2>編譯器:編譯器是講文法樹編譯為邏輯執行計劃
3>優化器:優化是對邏輯執行計劃進行優化
4>執行器:執行器是調用底層的運作康佳執行邏輯執行計劃.
Hive的底層存儲
Hive的資料是存儲在HDFS上的 Hive中的庫和表可以看做是HDFS上資料做的一個映射,是以Hive必須是運作在Hadoop叢集上的.
Hive程式的執行過程
hive中的執行器,試講最終要執行的MapReduce程式放在YARN上以一系列的Job的方式執行.
Hive的中繼資料的存儲
HIve的中繼資料是一般是存儲在MYSQL這種關系型資料庫上的,Hive和MYSQL之間通過MetaStore服務互動.

Hive用戶端
1>cli指令行用戶端:采用互動視窗.用hive指令行和Hive進行通信
2>HiveSever2用戶端:yongThrift寫進行通信,Thrift是不同語言之間的轉化器,是連接配接不同語言程式間的協定,通過JDBC或者ODBC去通路Hive
3>HWI用戶端:hive自帶的一個用戶端,一般不用
4>HUE用戶端:通過Web頁面來和Hive進行互動,使用的比較多.
Hive與HADHOOP的關系
Hive建構在Hadoop之上
1>HQL中對查詢語句的解析,優化,生成查詢計劃是由Hive完成的
2>所有的資料都是存儲在Hadoop中
3>查詢計劃被轉換為MapReduce任務,在Hadoop中執行(有些查詢沒MR任務,入select * from table)
4>Hadoop和Hive都是使用UTF-8編碼的
Hive和普通關系資料庫的異同
(1)查詢語言.有SQL被廣泛的應用在資料倉庫中.是以,專門針對Hive的特性設計了類SQL的查詢語言HQL 資料SQL開發者可以很友善的使用Hive進行開發的
(2)資料存儲位置,Hive是建立在HAdoop之上的.是以HIve的資料都是存儲在HDFS中的,而資料庫則可以将資料儲存在這塊裝置或者本地檔案系統中
(3)資料格式.Hive中沒有定義專門的資料格式,資料格式可以有使用者指定,使用者定義資料格式需要指定三個屬性:列分隔符(通常為空格,'t','x001'),行分隔符以及讀取檔案資料的方法(Hive中預設有三個檔案格式TextFile,SequenceFile以及RCFile),由于加載資料的過程中,不需要從使用者資料格式到Hive定義的資料格式轉換,是以Hive在加載的過程中不會對資料本身進行任何的修改,而隻是将資料内容複制或者移動到相應的HDFS目錄中.而在資料庫中,不同的資料庫有不同的存儲引擎,定義了自己的資料格式,所有的資料都會按照一定的住址存儲,是以資料庫加載資料的過程會比較耗時.
(4)資料更新.由于Hive是針對資料倉庫應用設計的.而資料倉庫的内容都铎寫少的,是以Hive中不支援資料的改寫和添加,所有的資料都是在加載的時候中确定好的.而資料庫中的資料通常是需要經常進行修改的,是以可以使用insert into ...values 添加資料,使用update ....set修改資料.
(5)索引,之前已經說過Hive在加載資料的過程中不會對資料進行任何處理,甚至不會對資料進行掃描,是以也沒有對資料中的某些Key建立索引,Hive要通路資料中滿足條件的特定值時,需要暴力掃描整個資料,是以通路延遲較高,資料庫中,通常會針對一個或者幾個列建立索引,是以對于少量的特定條件的資料的通路,資料庫中有很高的效率,較低的延遲,由于資料的通路延遲較高沒界定了Hive不适合線上資料查詢.
(6)執行,Hive中的大多數查詢的執行師通過Hadoop提供的MapReduce來實作的,而資料庫通常有自己的執行引擎.
(7)執行延遲:之前提到,Hive在查詢資料的時候,由于沒有索引,需要掃描整個表,是以延遲較高,另外一個導緻Hive執行延遲較高的因素是MapReduce架構,由于MapReduce本身具有較高的延遲,是以在利用MapReduce執行Hive查詢時,也會有較高的延遲,相對的,資料庫的執行延遲較低,當然,這個是有條件的,即資料量小,如果資料量很大,則延遲會遠超過Hive
(8)可擴充性,由于Hive是建立在Hadoop之上的.是以Hive的可擴充性适合Hadoop的可擴充性是一緻的,而資料庫由于ACID語句的嚴格限制,擴充性非常有限,目前先進的并行資料庫Oracle在理論上的擴充能力也隻有100台左右
(8)資料規模:由于Hive建立在叢集上并行利用MapReduce進行并行計算,是以可以支援很大規模的資料,對飲的,資料庫可以支援的資料庫規模較小.