本節書摘來自華章計算機《PostgreSQL伺服器程式設計》一書中的第2章,第2.6節,作者:(美)Hannu Krosing, Jim Mlodgenski, Kirk Roybal 著
,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
SQL Server允許你使用任何産生CLR的語言來建立DLL。這些DLL必須在啟動的時候被加載到伺服器裡面。為了在運作時間建立一個程式,并且使它立即可用,唯一的選擇就是内建的SQL方言——Transact SQL(TSQL)。
MySQL有一個叫做插件的功能。其中一種合法的插件類型是過程化語言。幾種語言完成加工後,借由插件系統可以和MySQL一起工作。這些語言包括了最流行的幾種語言,比如PHP、Python等。這些函數不能被用在存儲過程與觸發器中,但是它們可以被普通SQL語言喚醒。接下來,你就會被内建的SQL沒完沒了地糾纏。
PostgreSQL完全支援額外的過程化語言,這種語言可以被用來在資料庫中建立任何合法的實體,而這些實體可以使用PL/pgSQL來建立。這些語言可以從一個正在運作的PostgreSQL版本中進行添加(或删除),而且任何的使用這種語言的函數定義也可以在PostgreSQL運作的時候被建立或者抛棄。這些語言對PostgreSQL内部函數和所有資料實體具備所有的通路權限,這樣調用者是被允許的。
對于PostgreSQL,事實上有許多類似的插件語言擴充程式可供使用。我自己已經使用過的包括:PHP、Python、bash和PL/pgSQL。這意味着PostgreSQL的标準語言也需要使用其他語言所使用的相同擴充系統,來進行安裝和管理。
這個讓我們意識到,相比于最初所料想的,實際上有更多的開發者可以使用PostgreSQL。軟體開發者不必去學習一個新的開發語言來實作存儲過程。他們可以選擇合适的語言來擴充PostgreSQL,并且繼續按照之前的工作風格和流程進行代碼
編寫。
經驗總結:在PostgreSQL開發社群裡沒有二等公民。任何人幾乎可以使用任何語言進行編碼。
第三方工具:對于不同的資料庫平台,我們經常會比較平台上可以使用的第三方應用的數量。我不确定第三方工具的總數和你實際所需要的第三方應用數量是否同樣
重要。
最後,以下是一張産品清單,我經常會将這些産品和PostgreSQL一起使用:
Pentaho Data Integration (kettle):一個優秀的抽取、轉換、加載(Extract Transform and Load,ETL)工具
Pentaho Report Server:一個強大的報告引擎
PgAdmin3:一個極好的資料庫管理工具
php5-postgesql:一個供PHP進行本地通路PostgreSQL的包
Qcubed:一個支援PostgreSQL的PHP開發架構
Yii:一個很好的PHP開發架構
Talend:一個有用的ETL工具,但是并不是我所喜歡的
BIRT:一個很好的Java報告工具,這個工具帶有簡單的報告建立環境
psycopg2:Python針對PostgreSQL的套件
以上幾乎是一張完美的産品清單,這些工具已經讓PostgreSQL開發變成了一件輕而易舉的事情。我們可以用這樣一張支援PostgreSQL的應用程式清單來充實本書内容。也非常感謝他們的合法授權,PostgreSQL可以被内嵌到很多商業應用中,但是你可能從來沒有真正認識它。
經驗總結:你不用過多考慮到底現有多少工具可以支援PostgreSQL這個産品。所有重要的工具都是可用的。
2.6.1 平台相容性
SQL Server是微軟的産品。這樣說來,它曾經是,而且将來也會是一款微軟平台的工具。通過ODBC,我們可以進行一定的限定級别的通路,但是對于跨平台的開發來說,它不是一個嚴謹的選擇。目前來看,MySQL和PostgreSQL支援目前可用的每一個作業系統。這種能力(或者說限制的缺失)對于長期的穩定性來說是一個非常有力的因素。如果某種特定的作業系統不再可用,或者不再支援開源軟體,那麼把資料庫伺服器遷移到另外一個平台将是一件非常麻煩的事情。
2.6.2 應用程式設計
“已有的事,後必再有。已行的事,後必再行。日光之下并無新事。”
——傳道書 1:8-10 KJV
“舊的事情都已經過去,看呀,所有新的事情都已經發生。”
——2哥林多後書5:16-18 KJV
在軟體開發過程中,我們經常會遇到這樣的情況,當過時的技術再次興起時,這些開發者就如同信奉宗教一樣擁抱這種觀點。我們曾經在瘦服務端與瘦用戶端之間擺動,在扁平存儲與分級存儲之間選擇,也經曆了從桌面應用到網絡應用的轉變,但在本章中,我們最适宜讨論的話題是用戶端與服務端程式設計。
程式設計實作之間之是以會出現這種搖擺,與用戶端或服務端所能提供的功能無任何關系,反而很大程度上是開發者的經驗會産生更大的影響,且這種影響可以導向任何一種選擇,這種選擇取決于開發者首先碰見的是何種程式設計實作方式。
我鼓勵服務端開發者與用戶端開發者都先撇下他們所使用的工具,之後再閱讀本章剩餘部分。
在接下來有限的時間内,我們将讨論“伺服器程式設計”的絕大多數新功能。如果那時候你仍然沒有被說服,那我們會看一下,在你沒有抛棄應用為中心的觀點的情況下,你如何利用這些功能所帶來的諸多好處。
1.資料庫被認為是不利的
看待伺服器程式設計的最簡單、最省事的方法是把資料庫看做一個資料桶。你隻需要使用最基礎的SQL語句,比如INSERT、SELECT、UPDATE和DELETE,就可以每次操作一個單一的資料行,而且你還可以輕松地為多資料庫建立應用程式庫。
這個方法有一些明顯的缺陷。以每次一行的方式在資料庫伺服器之間移動資料,這種方式的效率極低,并且你也會發現這種方法在網絡架構的應用程式中完全不可行。
這個觀點經常和“資料抽象層”聯系在一起,這是一種用戶端庫檔案,它允許開發者花費較少的力氣将資料庫從應用程式下面分離出來。這個抽象層在開源開發社群中是非常有用的,它可以被使用在多種資料庫上,并且不需要财務上的扶持就可以獲得最佳的性能。
在27年的職業生涯中,在沒有抛棄應用程式的情況下,我從來沒有改變過任何一個應用所使用的資料庫。靈活軟體開發的原則之一是YAGNI(你并不需要它)。這就是其中的一個例子。
經驗總結:資料抽象對項目來說是有價值的,尤其是對于那些在安裝的時候需要選擇資料庫平台的項目。對于任何其他人,隻需要說no。
2.封裝
另一個偏向于用戶端開發體系的技巧是嘗試将資料庫中具體的調用分離到一個程式庫中。這個設計的目标通常是讓應用程式對所有業務邏輯進行控制。在這種情況下,應用程式仍然扮演着國王的角色,而資料庫僅僅是受國王控制的一個必要的禍害。
這個資料庫架構的觀點揭露了應用程式開發者的短處,就比如他們忽略了一個裝滿了工具的工具箱而僅僅選擇了那把錘子。應用程式中的所有東西到時候都被繪制得像一枚枚釘子,然後開發者可以使用錘子敲打它們。
經驗總結:千萬不要僅僅因為對資料庫不熟悉,就放棄資料庫所能帶來的強大力量。使用過程化語言,檢查一下擴充應用的工具包。那裡有一些很棒的産品。
3.PostgreSQL可以提供什麼
到目前為止,我們已經提到了過程化語言、函數、觸發器、定制的資料類型和運算符。這些東西可以在資料庫裡面通過CREATE指令直接建立,或者使用擴充應用被添加為庫
檔案。
現在我将向你展示一些事情,這些事情是你在PostgreSQL的伺服器上進行程式設計的時候所需要記住的。
4.資料位置
如果可以的話,盡量将資料儲存在伺服器上。請相信我,資料在伺服器上會更加順暢,當修改資料的時候性能會更好。如果所有的事情都在應用層完成的話,首先資料需要從資料庫端傳回給程式,然後進行修改操作,最後把資料發送回資料庫去執行這個事務。如果你正在開發一個網絡架構的應用程式,你最不該考慮的就是上述方法。
讓我們來看一小段程式,來看看如何使用兩種方法實作對一個記錄的更新:
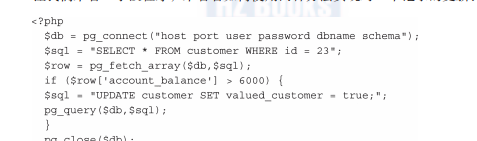
這一小段代碼将一行記錄從資料庫伺服器拉出來并推送到用戶端、進行資料評估,然後基于評估結果修改客戶的賬戶資訊。修改的結果最後會被發送回資料庫進行處理。
在這個應用場景中,有幾個錯誤的地方。首先,這個架構是可怕的。想象一下如果這個操作需要被上千甚至百萬級的客戶執行後果會是怎麼樣的呢?
第二個問題是事務的完整性。如果在查詢與更新語句執行之間,一些其他的事務更新了這個使用者的賬戶,出現這種情況該怎麼辦?這個客戶是否仍然是價值客戶?這取決于評估的業務邏輯。
嘗試以下的示例:

這個示例變得更加簡單了,它考慮了事務的完整性,并且可以應對相當大數量的客戶操作。為什麼我們在這裡展示這麼一個簡單且明顯的例子呢?因為許多開發架構都預設地按照錯誤的方式。可以預見的是,為了實作跨平台以及快捷地将形式內建到簡單的設計模型裡面,代碼生成器會産生和這個例子相等的形式。
這個方法催生了一些可怕的事實。對于一個擁有少數并發事務的系統,你可能可以看到你期待的内容,但是随着并發量的增長,意外情況的也會頻發。
第二個例子展示了一個更好的想法:對列進行操作,而不是行,将資料留在伺服器上,并且讓資料庫為你完成事務操作。這就是資料庫存在的理由。
2.6.3 更多基礎
在開始伺服器程式設計之前,這裡旨在提供一些基礎的背景資訊。在接下來的幾部分中,我們會研究你即将用到的通用的技術環境。我們會提到許多資訊,不要着急,你不需要馬上記住所有内容,抓住它們的大概意思即可。
1.事務
PostgreSQL裡面預設的事務隔離級别叫做Read Committed。這意味着如果多個事務嘗試修改相同的資料,它們必須等待其他事務完成,之後才可以對結果資料進行操作。它們在一個先進先出的隊列中等待。資料的最終結果是大多數人所能預料到的,反映的是最後的一個時序性的更改。
PostgreSQL并沒有提供任何會導緻錯誤讀取的方法。錯讀是在其他人的事務期間檢視資料的能力,并且假設它已經被執行完畢,進而使用了它。由于多版本并發控制産生了作用,是以PostgreSQL并不支援這種能力。
我們需要特别注意的是,當非事務性的代碼塊(BEGIN..END)被定義的時候,PostgreSQL會像一個私人事務一樣對待每一個獨立的語句,并且在語句完成的時候立即執行它們。這樣的操作就可以讓其他事務有機會插入到你的語句中。一些程式設計語言在你的語句塊周圍會提供一個事務代碼塊,當然也并不是所有的語言都會提供。請檢視你的語言文檔,求證一下你是否在一個事務會話中運作程式。
當我們使用這兩種主要的用戶端與PostgreSQL進行互動時,事務行為是不同的。psql指令行用戶端并沒有為你提供事務塊。你需要自己決定什麼時候啟動/停止一個事務。而pgAdmin3查詢視窗将你送出的所有語句封裝到了一個事務塊中。這就是它提供的一個“取消”選項。如果事務被中止了,一個“復原”操作将被執行,然後資料将回到它的前一個狀态。
一些操作是不被認定為事務的。比如即使事務失敗了且已經被復原,但是一個“序列”對象将會繼續執行。“CREATE INDEX CONCURRENTLY”需要它自己的事務管理,并且不應該在事務塊内部被調用。VACUUM和CLUSTER也是同樣的原理。
2.通用的錯誤報告和錯誤處理
如果你想在你的執行期間把狀态提供給使用者,你應該對這些指令比較熟悉:RAISE、NOTICE和NOTIFY。從事務性的角度看,它們之間的差別是即使它們被打包在一個事務中,RAISE和NOTICE會立即發送資訊,然而NOTIFY需要等事務被處置之後才會發送一條消息。是以如果事務失敗或復原了,NOTIFY則不會立即向你通知任何消息。
3.使用者定義函數(UDF)
編寫使用者定義函數是PostgreSQL的強大功能之一。函數可以使用許多不同的程式設計語言來編寫,也可以使用這個語言所提供的任何控制結構,并且即使是采用“不受信”的語言,函數也可以執行PostgreSQL中可用的任何操作。
函數可以提供一些甚至非SQL直接相關的功能。接下來我們引用的一些示例将會展示如何擷取網絡位址資訊、查詢目前系統、移動檔案,以及任何你心中所期望的事情。
那麼,我們該如何利用PostgreSQL的這個優點呢?我們從聲明一個函數開始:
但是,如果我們想把三個整數加在一起,該如何操作呢?
我們在前面提到過一個概念叫做函數重載。這個功能允許我們聲明一個同名函數,但是使用的是不同的參數,如此可能會産生不同的行為。這個差別的巧妙之處在于它僅僅改變了函數中一個參數的資料類型。PostgreSQL開發的函數取決于函數參數與期望的傳回類型的比對程度。
但是,假設我們的打算是把任意數量的數字加起來,那該如何完成呢? PostgreSQL也有方法來完成。
這個函數允許我們傳入任意數量的整數,并且傳回一個正确的結果。這些函數當然不會處理real或者numeric類型的資料。為了處理其他的資料類型,借助這些類型,我們僅僅需要再次聲明這個函數,并且使用相應的參數來調用它。
4.其他參數
目前,将資料傳入函數與從函數輸出有多種方法。我們也可以聲明IN/OUT參數、傳回表,傳回記錄集合,也可以使用遊标進行輸入與輸出。
這裡有一個特殊的資料類型叫做ANY。這種類型允許不限定參數類型,同時也允許任何基礎資料類型被傳遞到函數,然後由函數決定如何處理這個資料。
5.更多控制
一旦你按照需求編寫了你的函數,PostgreSQL便會在函數執行上給你提供額外的控制。你可以控制這個函數能通路什麼資料,也可以控制PostgreSQL如何解釋執行函數的開銷。
這裡有兩個聲明可以為你的函數提供安全環境。第一個是Security Invoker,這是預設的安全環境。在預設環境裡,調用者的權限通過函數來限制。
另一個環境是Security Definer。在這個環境下,函數建立者的使用者權限是在函數執行期間生效的。一般情況下,為了特殊目标,這種方法可臨時被用于提高使用者的權限。
同時,PostgreSQL也可以定義函數的開銷。這個可以幫助查詢規劃器評估調用這個函數會産生多大的消耗。更高次序的開銷會迫使查詢規劃器修改這個通路路徑,以降低函數被調用的頻率。PostgreSQL文檔将這些數字顯示為一個cpu_operator_cost因子。這裡有一些誤導。這些數字和CPU運作周期并沒有直接關系。它們僅僅和同其他函數進行結果比較時是相關的,這更像是一些國家的貨币與歐盟其他國家的貨币相比。一些國家的歐元比其他的更為有優勢。
為了估計自己所定義的函數的複雜性,讓我們從你所使用的語言開始。對于C,預設值是1 * number of records returned。對于Python,預設值是1.5。對于腳本語言,如PHP,更合适的預設值可能是100。對于plsh,你可能要使用150或更多,這取決于所涉及的外部工具的數量。而對于PL / pgSQL,預設值是100,這樣運作起來似乎效率挺不錯的。