1.概述
在《HBase查詢優化》一文中,介紹了基于HBase層面的讀取優化。由于HBase的實際資料是以HFile的形式,存儲在HDFS上。那麼,HDFS層面也有它自己的優化點,即:Short-Circuit Local Reads。本篇部落格筆者将從HDFS層面來進行優化,進而間接的提升HBase的查詢性能。
2.内容
Hadoop系統在設計之初,遵循一個原則,那就是移動計算的代價比移動資料要小。故Hadoop在做計算的時候,通常是在本地節點上的資料中進行計算。即計算和資料本地化。流程如下圖所示:
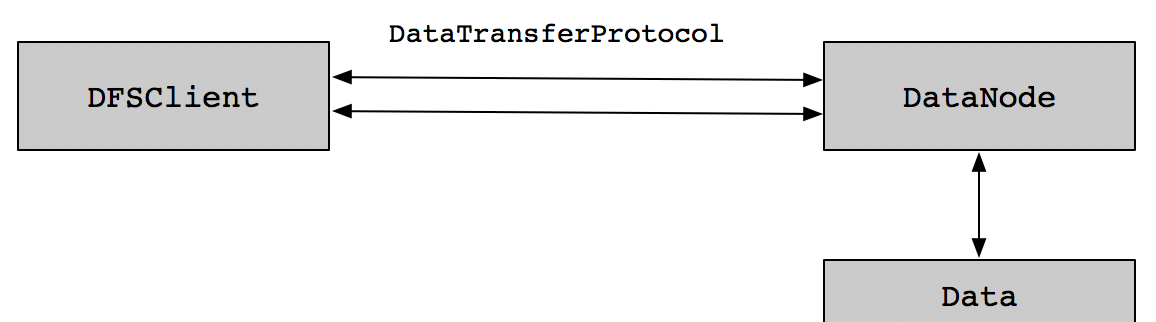
在最開始的時候,短回路本地化讀取和跨節點的讀取的處理方式是一樣的,流程都是先從DataNode讀取資料,然後通過RPC服務把資料傳輸給DFSClient,這樣處理雖然流程比較簡單,但是讀取性能會受到影響,因為跨節點讀取資料,需要經過網絡将一個DataNode的資料傳輸到另外一個DataNode節點(一般來說,HDFS有3個副本,是以,本地取不到資料,會到其他DataNode節點去取資料)。
2.1 方案一:用戶端直接讀取DataNode檔案
短回路本地化讀取的核心思想是,由于用戶端和資料在同一個節點上,是以DataNode不需要在資料路徑中。相反,用戶端本身可以簡單地讀取來自本地磁盤的資料。這種性能優化內建在CDH的Hadoop相關項目中,實作如下圖所示:

這種短回路本地化讀取的思路雖然很好,但是配置問題比較麻煩。系統管理者必須更改DataNode資料目錄的權限,以便用戶端有權限能夠打開相關檔案。這樣就不得不專門為那些能夠使用短回路本地化讀取的使用者提供白名單,不允許其他使用者使用。通常,這些用也必須被放置在一個特殊的UNIX組中。
另外,這種本地化短回路讀取的思路還存在另外一個安全問題,用戶端在讀取DataNode資料目錄時打開了一些權限,這樣意味着,擁有這個目錄的權限,那麼其目錄下的子目錄中的資料也可以被通路,比如HBase使用者。由于存在這種安全風險,是以這個實作思路已經不建議使用了。
2.2 方案二:短回路本地化安全讀取
為了解決上述問題,在實際讀取中需要非常小心的選擇檔案。在UNIX中有這樣一種機制,叫做“檔案描述符傳遞”。使用這種機制來實作安全的短回路本地讀取,而不是通過目錄名稱的用戶端,DataNode打開Block檔案和中繼資料檔案,将它們直接給用戶端。因為檔案描述符是隻讀的,使用者不能修改檔案。由于它沒有進入Block目錄本身,它無法讀取任何不應該通路的目錄。
舉個例子:
現有兩個使用者hbase1和hbase2,hbase1擁有通路HDFS目錄上/appdata/hbase1檔案的權限,而hbase2使用者沒有改權限,但是hbase2使用者又需要通路這個檔案,那麼可以借助這種“檔案描述符傳遞”的機制,可以讓hbase1使用者打開檔案得到一個檔案描述符,然後把檔案描述符傳遞給hbase2使用者,那麼hbase2使用者就可以讀取檔案裡面的内容了,即使hbase2使用者沒有權限。這種關系映射到HDFS中,可以把DataNode看作hbase1使用者,用戶端DFSClient看作hbase2使用者,需要讀取的檔案就是DataNode目錄中的/appdata/hbase1檔案。實作如下圖所示:
2.3 緩存檔案描述
HDFS用戶端可能會有經常讀取相同Block檔案的場景,為了提升這種讀取性能,舊的短回路本地讀取實作具有Block路徑的高速緩存。該緩存允許用戶端重新打開其最近已讀取的Block檔案,而不需要再去通路DataNode路徑讀取。
新的短回路本地讀取實作不是一個路徑緩存,而是一個名為FileInputStreamCache的檔案描述符緩存。這樣比路徑緩存要更好一些,因為它不需要用戶端重新打開檔案來重新讀取Block,這種讀取方式比就的短回路本地讀取方式在讀性能上有更好的表現。
緩存的大小可以通過dfs.client.read.shortcircuit.streams.cache.size屬性來進行調整,預設是256,緩存逾時可以通過dfs.client.read.shortcircuit.streams.cache.expiry.ms屬性來進行控制,預設是300000,也可以将其設定為0來将其進行關閉,這兩個屬性均在hdfs-site.xml檔案中可以配置。
2.4 如何配置
為了配置短回路本地化讀取,需要啟用libhadoop.so,一般來說所使用Hadoop通常都是包含這些包的,可以通過以下指令來檢測是否有安裝:
$ hadoop checknative -a
Native library checking:
hadoop: true /home/ozawa/hadoop/lib/native/libhadoop.so.1.0.0
zlib: true /lib/x86_64-linux-gnu/libz.so.1
snappy: true /usr/lib/libsnappy.so.1
lz4: true revision:99
bzip2: false 短回路本地化讀取利用UNIX的域套接字(UNIX domain socket),它在檔案系統中有一個特定的路徑,允許用戶端和DataNode進行通信。在使用的時候需要設定這個路徑到Socket中,同時DataNode需要能夠建立這個路徑。另外,這個路徑應該不可能被除了hdfs使用者或root使用者之外的任何使用者建立。是以,在實際建立時,通常會使用/var/run或者/var/lib路徑。
短回路本地化讀取在DataNode和用戶端都需要配置,配置如下:
<configuration>
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/lib/hadoop-hdfs/dn_socket</value>
</property>
</configuration> 其中,配置dfs.client.read.shortcircuit屬性是打開這個功能的開關,dfs.domain.socket.path屬性是DataNode和用戶端之間進行通信的Socket路徑位址,核心名額配置參數如下:
| 屬性 | 描述 |
| dfs.client.read.shortcircuit | 打開短回路本地化讀取,預設false |
| dfs.client.read.shortcircuit.skip.checksum | 如果配置這個參數,短回路本地化讀取将會跳過checksum,預設false |
| dfs.client.read.shortcircuit.streams.cache.size | 用戶端維護一個最近打開檔案的描述符緩存,預設256 |
| dfs.domain.socket.path | DataNode和用戶端DFSClient通信的Socket位址 |
| dfs.client.read.shortcircuit.streams.cache.expiry.ms | 設定逾時時間,用來設定檔案描述符可以被放進FileInputStreamCache的最小時間 |
| dfs.client.domain.socket.data.traffic | 通過UNIX域套接字傳輸正常的資料流量,預設false |
3.總結
短回路本地化讀取能夠從HDFS層面來提升讀取性能,如果HBase場景中,有涉及到讀多寫少的場景,在除了從HBase服務端和用戶端層面優化外,還可以嘗試從HDFS層面來進行優化。
4.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行讨論或發送郵件給我,我會盡我所能為您解答,與君共勉!
另外,部落客出書了《Hadoop大資料挖掘從入門到進階實戰》,喜歡的朋友或同學, 可以在公告欄那裡點選購買連結購買部落客的書進行學習,在此感謝大家的支援。
聯系方式:
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社群1):424769183
QQ群(Kafka并不難學): 825943084
溫馨提示:請大家加群的時候寫上加群理由(姓名+公司/學校),友善管理者稽核,謝謝!
熱愛生活,享受程式設計,與君共勉!
公衆号:
HBase查詢優化之Short-Circuit Local Reads