前言
在實際資料庫項目開發中,由于我們不知道實際查詢時資料庫裡發生了什麼,也不知道資料庫是如何掃描表、如何使用索引的,是以,我們能感覺到的就隻有SQL語句的執行時間。尤其在資料規模比較大的場景下,如何寫查詢、優化查詢、如何使用索引就顯得很重要了。
那麼,問題來了,在查詢前有沒有可能估計下查詢要掃描多少行、使用哪些索引呢?
答案是肯定的。以MySQL為例,MySQL通過explain指令輸出執行計劃,對要執行的查詢進行分析。
什麼是執行計劃呢?
簡單來說,就是SQL在資料庫中執行時的表現情況,通常用于SQL性能分析、優化等場景。
MySQL查詢過程
如果能搞清楚MySQL是如何優化和執行查詢的,對優化查詢一定會有幫助。很多查詢優化實際上就是遵循一些原則讓優化器能夠按期望的合理的方式運作。
下圖是MySQL執行一個查詢的過程。實際上每一步都比想象中的複雜,尤其優化器,更複雜也更難了解。本文隻給予簡單的介紹。
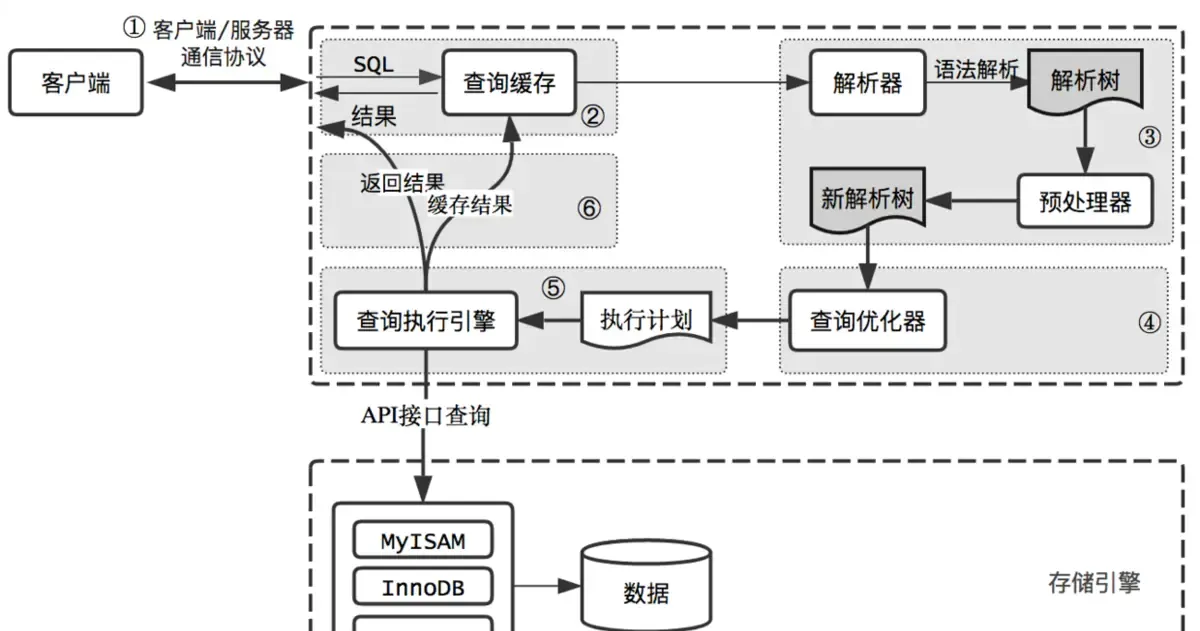
MySQL查詢過程如下:
用戶端将查詢發送到MySQL伺服器;
伺服器先檢查查詢緩存,如果命中,立即傳回緩存中的結果;否則進入下一階段;
伺服器對SQL進行解析、預處理,再由優化器生成對象的執行計劃;
MySQL根據優化器生成的執行計劃,調用存儲引擎API來執行查詢;
伺服器将結果傳回給用戶端,同時緩存查詢結果;
能幹嘛
使用EXPLAIN關鍵字可以模拟優化器執行SQL查詢語句,進而知道MySQL是如何處理你的SQL語句的。分析你的查詢語句或是表結構的性能瓶頸。
MySQL常見瓶頸
CPU:CPU在飽和的時候一般發生在資料裝入記憶體或從磁盤上讀取資料時候
IO:磁盤I/O瓶頸發生在裝入資料遠大于記憶體容量的時候
伺服器硬體的性能瓶頸:top,free,iostat和vmstat來檢視系統的性能狀态
具體可分析
表的讀取順序
資料讀取操作的操作類型
哪些索引可以使用
哪些索引被實際使用
表之間的應用
每張表有多少行被優化器查詢
使用

select查詢的序列号,表示查詢中執行select子句或操作表的順序
id相同,執行順序由上至下
id不同,如果是子查詢,id的序号會遞增,id值越大優先級越高,越先被執行
主要是用于差別普通查詢、聯合查詢、子查詢等的複雜查詢
SIMPLE:簡單的select查詢,查詢中不包含子查詢或者UNION。
PRIMARY:查詢中包含任何複雜的子部分,最外層查詢則被标記為PRIMARY。
SUBQUERY:在FROM清單中包含的子查詢被标記為DERIVED(衍生),MySQL會遞歸執行這些子查詢,把結果放在臨時表裡。
DERIVED:在FROM清單中包含的子查詢被标記為DERIVED(衍生)。MySQL會遞歸執行這些子查詢,把結果放在臨時表裡。
UNION:若第二個SELECT出現在UNION之後,則被标記為UNION;若UNION包含在FROM子句的子查詢中,外層SELECT将被标記為:DERIVED。
UNION RESULT:從UNION表中擷取結果的SELECT
顯示這一行的資料是關于哪些表的
type顯示的是通路類型,是較為重要的一個名額,其值性能從好到壞依次是:
常用的幾種類型:<code>system > const > eq_ref > ref > range > index > All</code>
類型
說明
system
表隻有一行記錄(等于系統表),這是const類型的特例,平時不會出現,這個也可以忽略不計。
const
表示通過索引一次就找到了,const用于比較primary key或則unique索引。因為隻比對一行資料,是以很快。如将主鍵置于where清單中,MySQL就能将該查詢轉換為一個常量。
eq_ref
唯一性索引掃描,對于每個索引鍵,表中隻有一條記錄與之比對。常見于主鍵或唯一索引掃描。
ref
非唯一性索引掃描,傳回比對某個單獨值的所有行。本質上也是一種索引通路,它傳回所有比對某個單獨值的行,然而,它可能會找到多個符合條件的行,是以它應該屬于查找和掃描的混合體。
range
隻檢索給定範圍的行,使用一個索引來選擇行。key列顯示使用了哪個索引。一般就是在你的where語句中出現了between、<、>、in等的查詢。這種範圍掃描索引掃描比全表掃描要好,因為它隻需要開始于索引的某一點,而結束于另一點,不會掃描全部索引。
index
Full Index Scan,index與All差別為index類型隻周遊索引樹。這通常比All快,因為索引檔案通常比資料檔案小。(也就是說雖然all和index都是讀全表,但index是從索引中讀取的,而all是從硬碟中讀的)
all
Full Table Scan,将周遊全表以找到比對的行。
一般來說,得保證查詢至少達到range級别,最好能達到ref。
possible_keys : 顯示可能應用在這張表中的索引,一個或多個。查詢涉及到的字段上若存在索引,則該索引将被列出。但不一定被查詢實際使用。
key : 實際使用的索引。如果為NULL,則沒有使用索引。查詢中若使用了覆寫索引,則該索引僅出現在key清單中,不會出現在possible_keys清單中。(覆寫索引:查詢的字段與建立的複合索引的個數一一吻合)
key_len : 表示索引中使用的位元組數,可通過該列計算查詢中使用的索引的長度。在不損失精确性的情況下,長度越短越好。key_len顯示的值為索引字段的最大可能長度,并非實際使用長度,即key_len是根據表定義計算而得,不是通過表内檢索出的。
顯示該表的索引字段關聯了其餘表的哪個字段
根據表統計資訊及選用情況,大緻估算出要得到最終結果所需讀取的行數,數值越小越好,最理想的值是1
包含十分重要的額外資訊。
屬性
Using filesort
查詢包含ORDER BY ,且無法利用索引完成排序操作的時候,MySQL Query Optimizer 不得不選擇相應的排序算法來實作。看到這個的時候,查詢就需要優化了。mysql需要進行額外的步驟來發現如何對傳回的行排序。它根據連接配接類型以及存儲排序鍵值和比對條件的全部行的行指針來排序全部行
Using temporary
當MySQL 在某些操作中必須使用臨時表的時候,在Extra 資訊中就會出現Using temporary 。主要常見于GROUP BY 和ORDER BY 等操作中。看到這個的時候,查詢需要優化了。
Using index
所需要的資料隻需要在Index 即可全部獲得而不需要再到表中取資料。列資料是從僅僅使用了索引中的資訊而沒有讀取實際的行動的表傳回的,這發生在對表的全部的請求列都是同一個索引的部分的時候。