master: Ubuntu 14.04 salve1: Ubuntu 14.04
hadoop: hadoop 2.2.0
修改本機(master)和子節點(slaveN)機器名:打開/etc/hostname檔案
sudo gedit /etc/hostname
(修改後需重新開機才能生效)
修改host檔案(映射各個節點IP):
sudo gedit /etc/hosts
在後面添加内容為:
172.22.144.115 master
172.22.144.114 slave1
172.22.144.116 slave2(注意修改為本機IP)
(master、slave1、slave2分别是主節點和子節點的機器名,即hostname裡的内容)
為主節點(master)和子節點(slave)分别建立hadoop使用者和使用者組:
先建立hadoop使用者組:
sudo addgroup hadoop
然後建立hadoop使用者:
sudo adduser -ingroup hadoop hadoop
(第一個hadoop是hadoop使用者組,第二個hadoop指使用者名)
給hadoop使用者賦予root使用者同樣的權限,打開/etc/sudoers檔案(目的:給hadoop使用者sudo權限)
sudo gedit /etc/sudoers
在root
ALL=(ALL:ALL) ALL這一行下添加
hadoop
ALL=(ALL:ALL) ALL
本機(master)和子節點(slave)安裝ssh服務:
sudo apt-get
update
sudo apt-get upgrade
sudo apt-get install ssh openssh-server
建立ssh無密碼登入環境:
進入建立立的hadoop使用者,建議登出目前使用者,然後選擇hadoop使用者
ssh生成密鑰有rsa和dsa兩種生成方式,預設情況下采用rsa方式
建立ssh-key,這裡我們采用rsa方式,在終端/home/hadoop目錄下輸入:
ssh-keygen -t rsa -P ""
(有确認資訊直接回車)
進入~/.ssh/目錄下:
cd /home/hadoop/.ssh
将此目錄下的id_rsa.pub追加到authorized_keys授權檔案中:
cat id_rsa.pub >> authorized_keys
将master節點上的rsa.pub通過ssh傳到子節點上(目的:公用公鑰密鑰)X代表第n個結點
scp ~/.ssh/id_rsa.pub @slaveX:~/.ssh/
進入~/.ssh/目錄下,将id_rsa.pub追加到authorized_keys授權檔案中
cd
/home/hadoop/.ssh
cat id_rsa.pub >>
authorized_keys
測試ssh互信是否建立
ssh hadoop@slave1
(如果不需要輸入密碼就可以登入成功則表示ssh互信已經建立)
假設将jdk1.8.0下載下傳到了/home/hadoop/Downloads檔案夾中,在終端進入該檔案夾
cd /home/hadoop/Downloads
tar -xvf
jdk-8-linux-x64.tar.gz
然後運作如下的指令,在 /usr/lib 目錄中建立一個為儲存Java jdk8 檔案的目錄。
sudo mkdir -p /usr/lib/jvm/jdk1.8.0/
接下來運作如下指令把解壓的 JDK 檔案内容都移動到建立的目錄中。
sudo mv jdk1.8.0/* /usr/lib/jvm/jdk1.8.0/
下一步,運作如下指令來配置 Java
sudo update-alternatives --install "/usr/bin/java" "java" "/usr/lib/jvm/jdk1.8.0/bin/java" 1
接下來,拷貝和粘貼下面這一行到終端執行,以啟用 Javac 子產品。
sudo update-alternatives --install "/usr/bin/javac" "javac" "/usr/lib/jvm/jdk1.8.0/bin/javac" 1
最後,拷貝和粘貼下面一行到終端以完成最終的安裝。
sudo update-alternatives --install "/usr/bin/javaws" "javaws" "/usr/lib/jvm/jdk1.8.0/bin/javaws" 1
要驗證下 Java 是否已經完全安裝的話,可以運作下面的指令來測試。
java –version
(如果出現jdk的版本資訊,則java環境變量配置成功)
1.假設hadoop-2.2.0.tar.gz在/home/hadoop/Downloads目錄,先進入此目錄
2. 解壓hadoop-2.2.0.tar.gz
sudo tar -zxf
hadoop-2.2.0.tar.gz
3. 将解壓出的檔案夾改名為hadoop;
sudo mv hadoop-2.2.0hadoop
4. 将該hadoop檔案夾的屬主使用者設為hadoop
sudo chown -R
hadoop
5. 打開hadoop/etc/hadoop-env.sh檔案;
sudo gedit
hadoop/etc/hadoop/hadoop-env.sh
6. 配置etc/hadoop-env.sh(找到export JAVA_HOME=...,修改為本機jdk的路徑);
export
JAVA_HOME=/usr/lib/jvm/jdk1.8.0
7. 打開etc/core-site.xml檔案;
hadoop/etc/hadoop/core-site.xml
在<configuration>标簽中添加如下内容:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
注意:master為主結點使用者名字,即hosts裡面的master結點名字
8. 打開etc /mapred-site.xml檔案,如果沒有此檔案,則将mapred-site.xml.template重命名即可
hadoop/etc/hadoop/mapred-site.xml
在<configuration>标簽中添加如下内容
<name>mapred.job.tracker</name>
<value></value>
9. 打開etc/hdfs-site.xml檔案;
hadoop/etc/hadoop/hdfs-site.xml
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2</value>
<name>dfs.data.dir</name>
< value>/usr/local/hadoop/data1,/usr/local/hadoop/data2</value>
<name>dfs.replication</name>
<value>2</value>
10. 打開etc/slaves檔案,添加作為slaveX的主機名,一行一個。
hadoop/etc/hadoop/slaves
這裡填成下列的内容 :
slave1
slave2
11、将還在/home/hadoop/Downloads目錄下的hadoop目錄移動到/usr/local/下
sudo mv
/home/hadoop/Downloads/hadoop /usr/local/
将配置資訊複制到子節點上
hosts檔案的複制,先将檔案複制到/home/hadoop下面:
sudo scp /etc/hosts hadoop@
再在datanode機器上将其移到相同的路徑下面/etc/hosts
sudo mv /home/hadoop/hosts /etc/hosts
(這條指令在子節點上執行)
hadoop檔案夾的複制,其中的配置也就一起複制過來了!
scp -r /usr/local/hadoop hadoop@
然後在子節點上執行
sudo mv /home/local/hadoop
/usr/local/
(如果提示是移動檔案夾,則加上-r參數)
并且要将所有節點的hadoop的目錄的權限進行如下的修改:
Hadoop
(在/usr/local/目錄下執行此指令)
子節點datanode機器要把複制過來的hadoop裡面的data1,data2和logs删除掉!
配置完成
首先終端進入/usr/local/hadoop/目錄下
重新開機hadoop
bin/stop-all.sh
bin/hdfs
namenode -format (格式化叢集)
bin/start-all.sh
連接配接時可以在namenode上檢視連接配接情況:
bin/hdfs dfsadmin –report
(注意這裡是在/usr/local/hadoop下)
結果如圖:
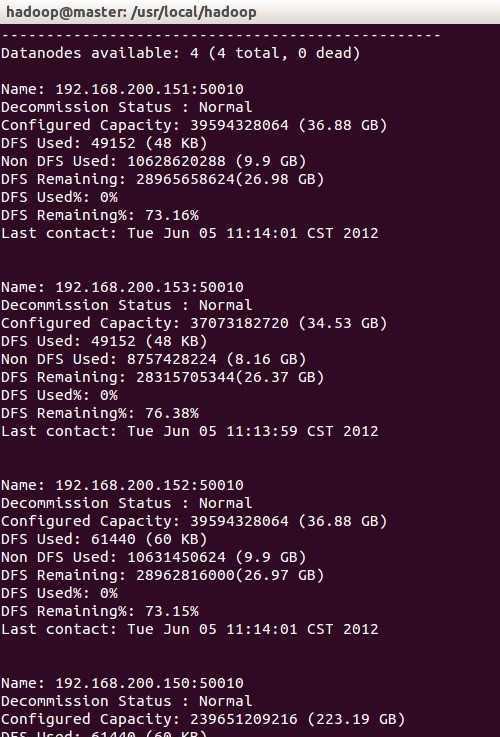
也可以直接進入網址:

建立測試txt檔案
檢視目錄
bin/hdfs dfs -ls /
(這裡的路徑為/usr/local/hadoop注意不要忘了)
建立目錄:
bin/hdfs dfs -mkdir /input
用示例文本檔案做為輸入:
在本地建立兩個測試檔案file01和file02,并填入一些内容
假設file01和file02在/home/hadoop目錄下
将兩個檔案上傳至hdfs檔案系統
bin/hdfs dfs –put /home/Hadoop/file01
/input/
bin/hdfs dfs –put /home/Hadoop/file02
子節點離開安全模式,否則可能會導緻無法讀取input的檔案:
bin/hdfs dfsadmin –safemode
leave
運作wordcount程式:
bin/hadoop jar /xxx/xxx.jar wordcount
/input/ /output
(這裡的/XXX/代表/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar)
檢視結果:
bin/hdfs dfs -cat
/output/part-r-00000
重複運作需要删除output,否則會抛出檔案夾已經存在的異常
bin/hdfs dfs -rmr
/output