Conditional Variational Autoencoders --- 條件式變換自編碼機
Goal of a Variational Autoencoder:
一個 VAE(variational autoencoder)是一個産生式模型,意味着我們可以産生看起來像我們的訓練資料的 samples。以 mnist 資料集為例,這些僞造的樣本可以看做是手寫字型的合成圖像。我們的 VAE 将會提供我們一個空間,我們稱之為 latent space (潛在空間),我們可以從這裡采樣出 points。任何這些點都可以 decoded into 一個合理的手寫字型的圖像。
Structure of a VAE :
任何自編碼機的目标都是重建其輸入。通常,自編碼機首先講 input 壓縮為一個小的 form,然後将其轉換成 input的一個估計。這個被用于壓縮圖像的函數,稱為 "encoder",解壓該資料的函數稱為 “decoder”。這些函數都可以是神經網絡,我們這個文檔中考慮的都是這種情況。
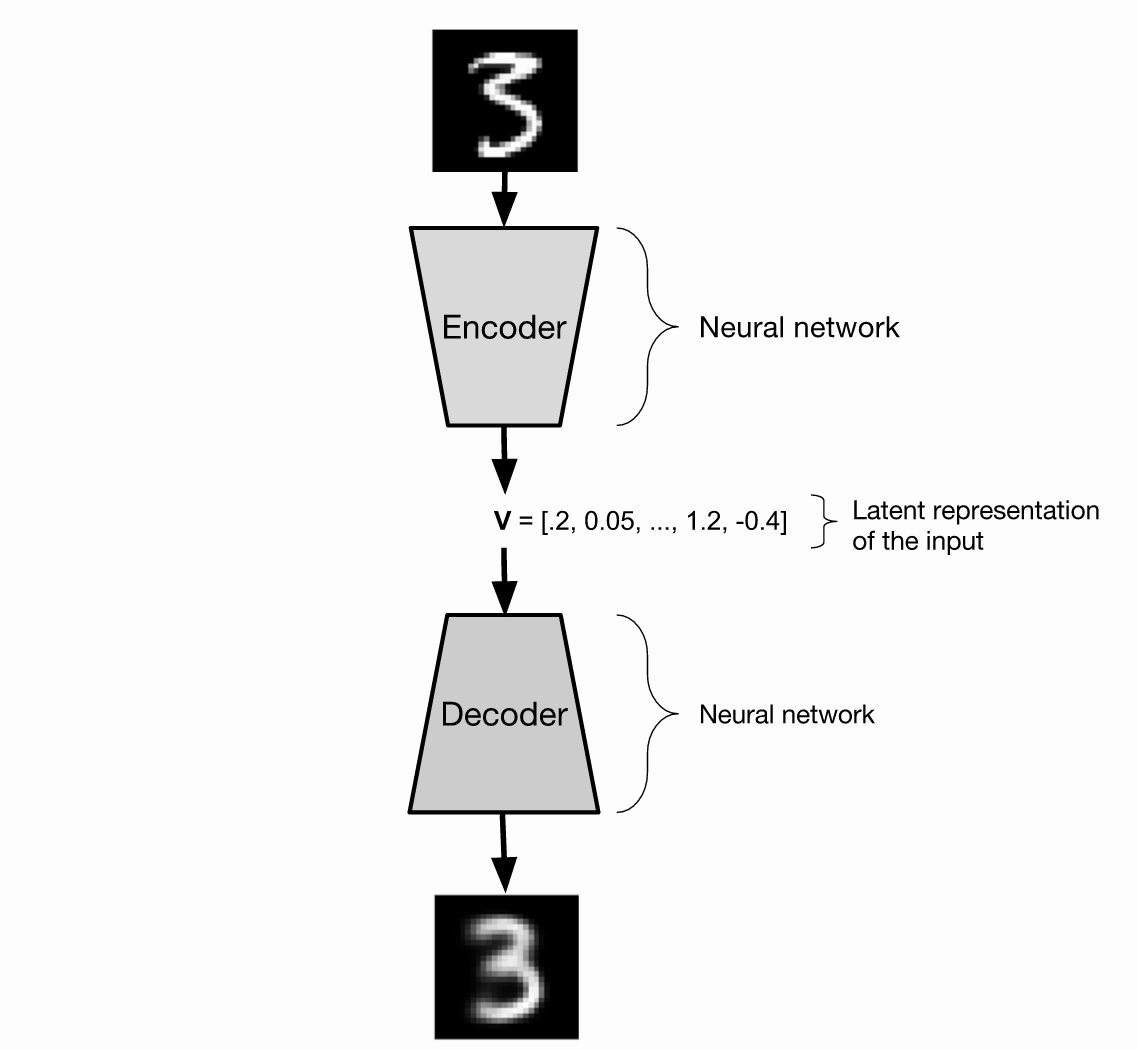
标準的自編碼機可以工作的很好,如果你的目标是簡單的重建你的輸入,但是作為産生式模型,其效果并不是很好,因為随機的采樣一個輸入 V 給 decoder,并不能使得 decoder 産生合理的圖像。 V 可能距離任何輸入都很遠,是以 decoder 可能永遠都不會訓練得到合理的數字圖像,當給定的輸入像 V 的時候。
我們需要一些方法來确認 the decoder 已經準備好了可以去 decode 出任何我們給定的合理的數字圖像。為了達到這個目的,我們将會需要預先定義 decoder 希望看到的 輸入的分布 (the distribution of inputs)。我們将會使用一種标準的 正态分布 來定義 decoder 将會接收到的 輸入的分布。

我們想要訓練 the decoder 從這個分布中随機的采樣一個點,并且可以恢複出合理的 數字圖像。
我們現在需要一個 encoder。在傳統的自編碼機當中,the encoder 從資料中采樣出一個樣本,并且在 latent space 中傳回給一個點,然後将其傳給 decoder。在一個 Variational autoencoder 中,編碼機在 latent space 中産生一個機率分布。
The latent distributions 其輸出是和 latent space 相同緯度的高斯 (gaussians of the same dimensionality as the latent space)。The encoder 産生這些高斯的參數。
是以我們有一個 encoder 從圖像中采樣,産生 latent space 的機率分布,the decoder 在 latent space 中采樣該點,然後傳回一個僞造的圖像。是以對于一張給定的圖像來說,the encoder 産生一個分布,在 latent space 中該分布中采樣出一個點出來,然後将該點輸入到 decoder 當中,産生一個人造圖像。
The Structure of the Latent Space.
我們看到了之前 the decoder 應該期望看到從标準正态分布中采樣的點。但是,現在我們已經表明,decoder 接收到的 samples 并非是标準的正态分布。這兩個東西都不是非常的奇怪,即使,當從 encoder 中采樣出的 points 仍然近似的拟合一個标注的正态分布的情況。我們想要這樣的情況:
其中,不同分布的平均值 對應了 不同訓練訓練樣本估計的标準正态 (a standard normal)。現在的假設是 the decoder 看到的 points, drawn from a standard normal distribution holds.
很明顯,我們需要一些方法來衡量是否 the encoder 産生的分布的和 (sum)可以估計 (approximat)标準的正太分布。我們可以利用KL-散度(Kullback-Leibler divergence)衡量該估計的品質。KL-散度 衡量了兩個分布的差異程度 (measures how different two probability distributions are)。
Training a VAE with The Representrization Trick.
在上述讨論的 VAE 當中,網絡的輸入和輸出之間,有一個随機的變量。通過一個随機變量是無法後向傳播的,其代表了一個很明顯的問題是:你現在無法訓練 the encoder。為了解決這個問題,the VAE 被表達成不同的方式,使得 the latent distribution 的參數可以分解為随機變量的參數,使得後向傳播可以沿着latent distribution 的參數繼續傳播。
具體來說,就是
。但是,一個很重要的啟發是:一個 VAE 可以利用 BP 算法進行 end-to-end 的訓練。但是,由于仍然存在一些随機的元素,是以不被稱為随機梯度下降,該訓練過程被稱為:随機梯度變化的貝葉斯(stochastic gradient variational Bayes (SGVB))。
Conditional Variational Autoencoder :
到目前為止,我們已經創造了一個 autoencoder 可以重建起輸入,并且 decoder 也可以産生一個合理的手寫字型識别的圖像。該産生器,但是,仍然無法産生一個需要的特定數字的圖像。進入 the conditional variational auroencoder (CVAE)。該條件式變換自編碼機 有一個額外的輸入給 encoder 和 decoder。
在訓練的時候,輸入給 encoder and decoder 的圖像對應的數字是給定的。在這種情況下,将會被表示成 one-hot vector.
為了産生一個特定數字的圖像,将該數字輸入給 the decoder 以及服從标準正态分布采樣出的 latent space 中的一個随機點。盡管 同樣的點 被輸入進來來産生呢兩個不同的數字,這個過程将會正确的工作,因為系統不在依賴于 the latent space 來編碼你要處理的數字。相反的,the latent space 編碼了其他的資訊,像 stroke width 或者說 the angle。
下面的這些數字圖像就是通過固定所需要的數字輸入給 the decoder,然後從 the latent space 中取一些随機的樣本來産生一些有用的,不同版本的那個數字。像您所看到的那樣,這些數字在類型上有所不同,但是同一行的數字,很明顯是同一個數字。
Conclusion
VAEs 是非常有效的無監督學習工具。标準 VAE 的 latent space 應該捕獲到你的資料中有用的模式。例如,我們可以看到,一個 VAE 在沒有任何 label 的情況下訓練,可以成功的分類出 mnist 圖像,分為 latent space 中 10個具有區分度的區域,每個區域包含幾乎某個數字所有的圖像。 CVAEs 對于産生比對 某些 labels 的僞造樣本來說,是非常有用的。對于處理 時序資料,VAEs 也非常有用,隻需将 the encoder and the decoder 替換為 RNNs 即可。
(完畢)
----------------------------------------------------------------------------
原文連結: http://ijdykeman.github.io/ml/2016/12/21/cvae.html