Perceptual Losses for Real-Time Style Transfer and Super-Resolution and Super-Resolution 論文筆記
ECCV 2016
摘要: 許多經典問題可以看做是 圖像轉換問題(image transformation tasks)。本文所提出的方法來解決的圖像轉換問題,是以監督訓練的方式,訓練一個前向傳播的網絡,利用的就是圖像像素級之間的誤差。這種方法在測試的時候非常有效,因為僅僅需要一次前向傳播即可。但是,像素級的誤差 沒有捕獲 輸出和 gt 圖像之間的 感覺差別(perceptual differences)。
與此同時,最近的工作表明,高品質的圖像可以通過 perceptual loss function 來生成,不依賴于像素之間的差别,而是 高層圖像特征之間的差别。圖像正是基于這種特征之間的 loss 進行訓練的。這種方法可以産生高品質的圖像,但是速度卻很慢,因為需要解決一個優化問題。
本文中,我們将兩者的優勢進行結合,訓練一個前向傳播的網絡進行圖像轉換的任務,但是不用 pixel-level loss function,而采用 perceptual loss function。在訓練的過程中,感覺誤差 衡量了圖像之間的相似性,在測試的時候可以實時的進行轉換。
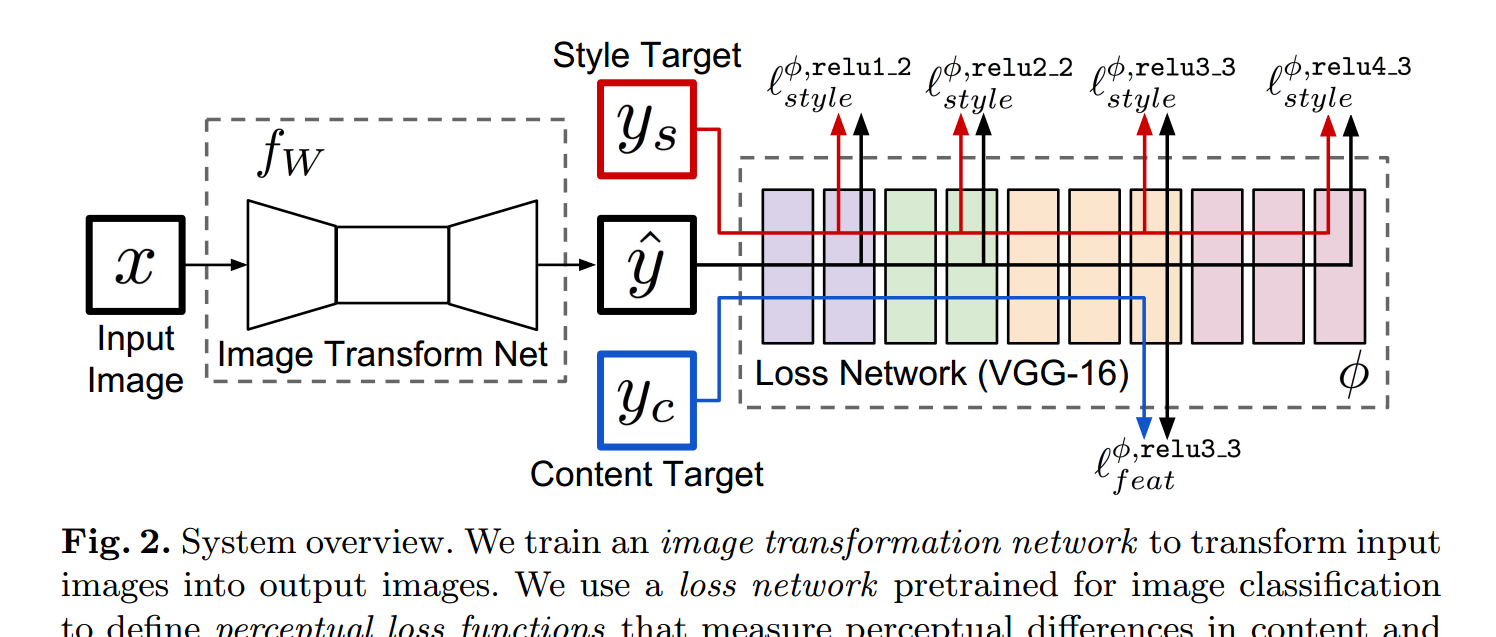
網絡的訓練:
網絡主要由兩個部分構成:一個是 image transformation network 一個是 loss network 用來定義 loss function。圖像轉換網絡 是一個殘差網絡,它将輸入圖像轉換為輸出圖像 y^。每個損失函數計算一個 scalar value 衡量輸出圖像和目标圖像之間的不同。圖像轉換網絡 是通過 SGD 進行訓練的,利用權重的損失函數,如下所示:

為了解決 per-pixel losses 的缺陷,并且允許我們的 loss function 可以更好的衡量 感覺和語義的差別,我們從最近的通過優化來産生圖像得到了啟發。關鍵點在于:這些方法用到的網絡已經是學習到編碼感覺和語義資訊,這些網絡都是在分類的資料集上進行訓練後的。我們是以就用這些網絡來固定的作為 loss network 來定義我們的損失函數。
剛開始看那個流程圖的時候,比較糊塗的是兩個 target,$y_c$ 和 $y_s$ 。其實是這樣子的:
對于每一個圖像 x ,我們有一個 content target $y_c$ 和 一個 style target $y_s$。
對于 style transfer 來說,the content target $y_c$ 是輸入圖像 x,the output image y^ 應該 結合 the content x = $y_c$ 和 $y_s$ 的 style 。
對于 超分辨來說,輸入圖像 x 是一個低分辨率的圖像,the content target $y_c$ 是一個 gt 高分辨率的圖像,style reconstruction loss 沒有用到。對于一種超分辨的因子,我們就訓練一種網絡。
實驗結果: