<a href="http://www.cnblogs.com/jasonfreak/p/5448462.html">這裡是原文</a>
使用<code>sklearn</code>進行資料挖掘
1.1 資料挖掘的步驟
1.2 資料初貌
1.3 關鍵技術并行處理
并行處理
2.1 整體并行處理
2.2 部分并行處理流水線處理自動化調參持久化回顧總結參考資料使用<code>sklearn</code>進行資料挖掘
資料挖掘通常包括資料采集,資料分析,特征工程,訓練模型,模型評估等步驟。使用<code>sklearn</code>工具可以友善地進行特征工程和模型訓練工作,在《使用<code>sklearn</code>做單機特征工程》中,我們最後留下了一些疑問:特征處理類都有三個方法<code>fit</code>、<code>transform</code>和<code>fit_transform</code>,<code>fit</code>方法居然和模型訓練方法<code>fit</code>同名(不光同名,參數清單都一樣),這難道都是巧合?
顯然,這不是巧合,這正是<code>sklearn</code>的設計風格。我們能夠更加優雅地使用<code>sklearn</code>進行特征工程和模型訓練工作。此時,不妨從一個基本的資料挖掘場景入手:
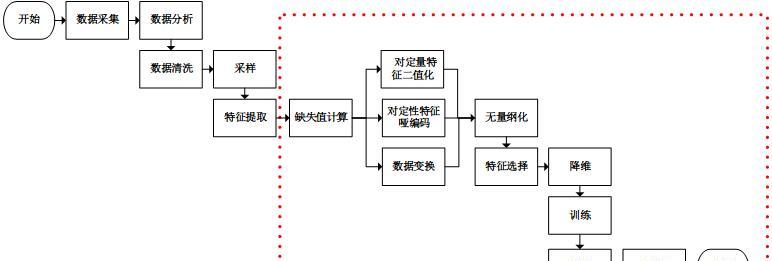
我們使用<code>sklearn</code>進行虛線框内的工作(<code>sklearn</code>也可以進行文本特征提取)。通過分析<code>sklearn</code>源碼,我們可以看到除訓練,預測和評估以外,處理其他工作的類都實作了3個方法:<code>fit</code>、<code>transform</code>和<code>fit_transform</code>。從命名中可以看到,<code>fit_transform</code>方法是先調用<code>fit</code>然後調用<code>transform</code>,我們隻需要關注<code>fit</code>方法和<code>transform</code>方法即可。
transform方法主要用來對特征進行轉換。從可利用資訊的角度來說,轉換分為無資訊轉換和有資訊轉換。無資訊轉換是指不利用任何其他資訊進行轉換,比如指數、對數函數轉換等。有資訊轉換從是否利用目标值向量又可分為無監督轉換和有監督轉換。無監督轉換指隻利用特征的統計資訊的轉換,統計資訊包括均值、标準差、邊界等等,比如标準化、<code>PCA</code>法降維等。有監督轉換指既利用了特征資訊又利用了目标值資訊的轉換,比如通過模型選擇特征、<code>LDA</code>法降維等。通過總結常用的轉換類,我們得到下表:
包
類
參數清單
類别
fit方法有用
說明
sklearn.preprocessing
StandardScaler
特征
無監督
Y
标準化
MinMaxScaler
區間縮放
Normalizer
無資訊
N
正則化
Binarizer
定量特征二值化
OneHotEncoder
定性特征編碼
Imputer
缺失值計算
PolynomialFeatures
多項式變換(fit方法僅僅生成了多項式的表達式)
FunctionTransformer
自定義函數變換(自定義函數在transform方法中調用)
sklearn.feature_selection
VarianceThreshold
方差選擇法
SelectKBest
自定義特征評分選擇法
chi2 特征
卡方檢驗選擇法
RFE
特征+目标值
有監督
遞歸特征消除法
SelectFromModel
自定義模型訓練選擇法
sklearn.decomposition
PCA
PCA降維
sklearn.lda
LDA
LDA降維
不難看到,隻有有資訊的轉換類的<code>fit</code>方法才實際有用,顯然<code>fit</code>方法的主要工作是擷取特征資訊和目标值資訊,在這點上,<code>fit</code>方法和模型訓練時的<code>fit</code>方法就能夠聯系在一起了:都是通過分析特征和目标值,提取有價值的資訊,對于轉換類來說是某些統計量,對于模型來說可能是特征的權值系數等。另外,隻有有監督的轉換類的<code>fit</code>和<code>transform</code>方法才需要特征和目标值兩個參數。<code>fit</code>方法無用不代表其沒實作,而是除合法性校驗以外,其并沒有對特征和目标值進行任何處理,<code>Normalizer</code>的<code>fit</code>方法實作如下:
基于這些特征處理工作都有共同的方法,那麼試想可不可以将他們組合在一起?在本文假設的場景中,我們可以看到這些工作的組合形式有兩種:流水線式和并行式。基于流水線組合的工作需要依次進行,前一個工作的輸出是後一個工作的輸入;基于并行式的工作可以同時進行,其使用同樣的輸入,所有工作完成後将各自的輸出合并之後輸出。<code>sklearn</code>提供了包<code>pipeline</code>來完成流水線式和并行式的工作。
在此,我們仍然使用IRIS資料集來進行說明。為了适應提出的場景,對原資料集需要稍微加工:
并行處理,流水線處理,自動化調參,持久化是使用<code>sklearn</code>優雅地進行資料挖掘的核心。并行處理和流水線處理将多個特征處理工作,甚至包括模型訓練工作組合成一個工作(從代碼的角度來說,即将多個對象組合成了一個對象)。在組合的前提下,自動化調參技術幫我們省去了人工調參的反鎖。訓練好的模型是貯存在記憶體中的資料,持久化能夠将這些資料儲存在檔案系統中,之後使用時無需再進行訓練,直接從檔案系統中加載即可。
并行處理使得多個特征處理工作能夠并行地進行。根據對特征矩陣的讀取方式不同,可分為整體并行處理和部分并行處理。整體并行處理,即并行處理的每個工作的輸入都是特征矩陣的整體;部分并行處理,即可定義每個工作需要輸入的特征矩陣的列。
<code>pipeline</code>包提供了<code>FeatureUnion</code>類來進行整體并行處理:
整體并行處理有其缺陷,在一些場景下,我們隻需要對特征矩陣的某些列進行轉換,而不是所有列。<code>pipeline</code>并沒有提供相應的類(僅<code>OneHotEncoder</code>類實作了該功能),需要我們在<code>FeatureUnion</code>的基礎上進行優化:
在本文提出的場景中,我們對特征矩陣的第1列(花的顔色)進行定性特征編碼,對第2、3、4列進行對數函數轉換,對第5列進行定量特征二值化處理。使用<code>FeatureUnionExt</code>類進行部分并行處理的代碼如下:
<code>pipeline</code>包提供了<code>Pipeline</code>類來進行流水線處理。流水線上除最後一個工作以外,其他都要執行<code>fit_transform</code>方法,且上一個工作輸出作為下一個工作的輸入。最後一個工作必須實作<code>fit</code>方法,輸入為上一個工作的輸出;但是不限定一定有<code>transform</code>方法,因為流水線的最後一個工作可能是訓練!
根據本文提出的場景,結合并行處理,建構完整的流水線的代碼如下:
網格搜尋為自動化調參的常見技術之一,<code>grid_search</code>包提供了自動化調參的工具,包括<code>GridSearchCV</code>類。對組合好的對象進行訓練以及調參的代碼如下:
<code>externals.joblib</code>包提供了<code>dump</code>和<code>load</code>方法來持久化和加載記憶體資料:
類或方法
sklearn.pipeline
Pipeline
流水線處理
FeatureUnion
sklearn.grid_search
GridSearchCV
網格搜尋調參
externals.joblib
dump
資料持久化
load
從檔案系統中加載資料至記憶體
注意:組合和持久化都會涉及<code>pickle</code>技術,在<code>sklearn</code>的技術文檔中有說明,将<code>lambda</code>定義的函數作為<code>FunctionTransformer</code>的自定義轉換函數将不能`pickle化。
2015年我設計了一個基于<code>sklearn</code>的自動化特征工程的工具,其以<code>Mysql</code>資料庫作為原始資料源,提供了“靈活的”特征提取、特征處理的配置方法,同時重新封裝了資料、特征和模型,以友善排程系統識别。說靈活,其實也隻是通過配置檔案的方式定義每個特征的提取和處理的sql語句。但是純粹使用sql語句來進行特征處理是很勉強的,除去特征提取以外,我又造了一回輪子,原來sklearn提供了這麼優秀的特征處理、工作組合等功能。是以,我在這個部落格中先不提任何算法和模型,先從資料挖掘工作的第一步開始,使用基于Python的各個工具把大部分步驟都走了一遍(抱歉,我暫時忽略了特征提取),希望這樣的梳理能夠少讓初學者走彎路吧。
本文轉自羅兵部落格園部落格,原文連結:http://www.cnblogs.com/hhh5460/p/5615729.html,如需轉載請自行聯系原作者
![GitHub連夜封殺!這份阿裡 10W 字内部 Java 字面試手冊到底有多強?[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)