在今天的文章裡,我想讨論下SQL Server裡的INTERSECT設定操作。INTERSECT設定操作彼此交叉2個記錄集,傳回2個集裡列值一樣的記錄。下圖示範了這個概念。
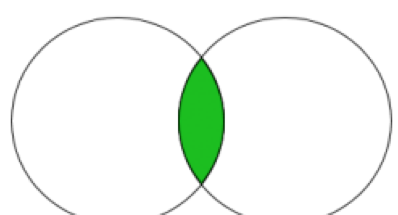
你會發現,它和2個表間的INNER JOIN幾乎一樣。但今天我會介紹它們之間的一些重要差別。讓我們從建立作為輸入的2個簡單表開始。
從T-SQL代碼裡你可以看到,我也在2個表上建立了唯一聚集索引,并插入了一些測試記錄。現在讓我們來彼此交叉這2個表:

SQL Server傳回2條記錄:列值為2和列值為NULL的記錄。這是和INNER JOIN的第1個大差別:如果NULL值出現在2個表裡,這些記錄會被忽略。當你在Col列上進行2個表之間的INNER JOIN操作,含NULL值的記錄不會傳回:
下圖顯示了INTERSECT和INNER JOIN方法結果集的不同:
現在我們來分析下INTERSECT設定操作的執行計劃。因為在Col列上你有支援的索引,查詢優化器可以翻譯INTERSECT操作為傳統的INNER JOIN邏輯操作。
但這裡Nested Loop(Inner Join)并不真正進行INNER JOIN操作。我們來看下為什麼。當你檢視Nested Loop運算符屬性時,你會看到在Clustered Index Seek (Clustered)運算符上有剩餘謂語(residual predicate)。
剩餘謂語在Col2上評估,因為那列不是剛才建立的聚集索引導航結構的一部分。如我剛開始說的,SQL Server需要在2個表所有列找到比對的行。使用Clustered Index Seek (Clustered)運算符和剩餘謂語,SQL Server隻檢查在t1表裡是否有同樣列值的比對記錄。而且Nested Loop運算符本身隻傳回從一個表的列值——這裡是t1表。
是以INNER JOIN隻是個左半連接配接(Left Semi Join):SQL Server檢查在右表裡是否有我們比對的記錄——如果是的話,比對的記錄從左表傳回。Clustered Index Seek (Clustered)上的剩餘謂語可以通過提供在導航結構裡包含所有必須的列來剔除,如下所示:
現在當你再次看INTERSECT運算符的執行計劃,你會看到SQL Server在剛才建立的索引進行Index Seek (NonClustered)操作,剩餘謂語已經不再需要。
現在當我們删除所有支援的索引結構,我們來看執行計劃會變成什麼樣。
當你再次對2個表進行INTERSECT,現在在執行計劃裡你會看到Nested Loop (Left Semi Join)運算符。SQL Server現在需要在執行計劃裡進行左半實體連接配接,通過在内部上進行Table Scan運算符和在Nested Loop裡用剩餘謂語進行逐行比較。
這個執行計劃并不真的高效,因為在内部Table Scan需要反複進行——對來自外表傳回的每一行。如果我們想盡可能高效的進行INTERSECT設定操作,支援的索引非常重要。
INTERSECT設定操作并不可怕,但幾乎沒人很懂它。當你用它時,你要意識到它和INNER JOIN.之間的差別。你也看到,有很好的索引設計對它非常重要,這樣的話查詢優化器可以生成很好的執行計劃。
感謝關注!