iDST: 塵恩,芝泉,磐君
最近,iDST視訊分析組參加了ACM MM下舉辦的Large-Scale Video Classification比賽,參與比賽的還有七牛雲,商湯,華師大,以及一些其他院校。我們很榮幸的獲得了第一的成績。在本次競賽中,我們聚焦于各種模态對視訊分類的影響,總結出了一些對于umtrimmed video classification行之有效的模态提取,聚合方法。
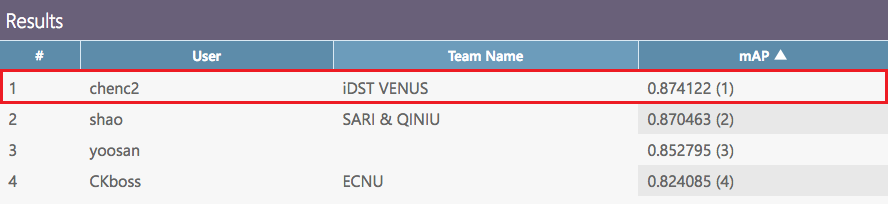
圖1. LSVC2017比賽結果
LSVC 2017資料庫是在Fudan-Columbia視訊資料庫基礎上的擴充,包含8000小時的視訊,500個類目,類目包含物體,場景,動作,社交活動等。 訓練,驗證,測試集合分别有 62000/15000/78000個視訊,總視訊數量超過150000,原始視訊官方提供約3T,這個資料規模比較适合我們提取各種模态特征來分析。在更早進行的Youtube-8M視訊分類比賽中,官方提供抽好的cnn特征,不允許自己額外提取,是以參賽隊隻能在aggregation上進行實驗,本次LSVC比賽我們使用VLAD作為aggregation方法,利用odps對大規模視訊進行特征提取,一般能夠在一兩天的時間内抽完某個模态的特征。
最常用的是ImageNet上pretrain的cnn模型來提取特征,官方提供了vgg的特征,但我們用了最新的Inception Resnet V2 和 Squeeze & Excitation模型。另外,我們針對LSVC資料庫,額外在Places/Food101資料庫上預訓練了兩個模型,在LSVC中,有80類是和食物相關,而且食物相關的類别都很難區分,例如關于蛋的類目包括煮蛋,煎蛋,沙拉蛋等細分的烹饪類别,我們希望通過專門針對food訓練得到的特征能提高模型性能。對于圖像模态,我們以1fps采樣抽取特征。具體得圖像模态間下表。

表1. 圖像模态
模型在audioset資料庫上訓練得到,該資料庫是目前規模最大的audio dataset。
表2. 聲音模态
由于我們aggregation采用VLAD,VLAD本身并沒有encode 時域資訊的能力,是以如果要捕捉時域強相關的類别資訊,例如“baby crawling”,"high jump","long jump",需要模态特征包含時域資訊,C3D是一種很不錯的選擇,不過在視訊領域沒有大規模通用的dataset,是以C3D通常隻能設計的比較簡單。今年Deepmind提出一種I3D(Inflated 3D),能夠在初始化時通過将二維卷積核複制擴充到三維,吸收了imagenet圖像資料資訊,進而可以設計較深層的3D卷積模型,在HMDB/UCF兩個動作分類資料庫上獲得了很好的性能。i3D如下圖,
圖2. I3D 模型框圖
I3D是two stream的模式,除了appearance還提取了optical flow的motion資訊,我們提取的I3D如下表所示:
表3. I3D 模态特征
PCA + Whiten + 8bit Quantization
表4. 各個模态PCA前後次元
在LSVC資料庫中,視訊平均長度為三分鐘,有個别特别長的視訊,我們首先将視訊分為10分鐘的一小段,對于圖像模态,以1fps提取特征可以獲得600幀資料,對于每個training step,我們random的從600幀中抽50幀作為輸入,在test階段,我們重複該過程并去average作為最終預測結果。random的抽幀主要考慮到某些視訊,關鍵場景分布不均勻,例如“marriage proposal”,重要場景經常出現在最後,random可以保證大機率捕獲關鍵。另外random一定程度也起到了data augmentation的作用。對于random會打亂原有視訊時序資訊的問題,由于在I3D的模态中feature本身是帶有temporal資訊的,是以并不會影響action相關視訊的識别。
圖3. 采樣政策
特征融合包括兩個方面,多個模态之間如何融合以及時域特征如何融合。模态之間,我們采用late fusion的政策,即各個模态先通過Aggregation模型擷取vector再concatenate起來。而Aggregation模型,我們采用了netVLAD的方式。netVLAD首先被提出應用在place image retrieval任務中,最後一層feature map上每個位置可以當做local feature,通過VLAD encode,在傳統VLAD基礎上改進了Cluster assignment的方式,使整個過程可back propagate,在視訊分類問題中,輸入feature為模态特征,各個模态encode成vlad向量。
圖4. 多模态視訊分類框圖
表5. 單模态實驗結果
可以看到,在ImageNet上pretrain提取的feature獲得比較好的效果,尤其是Squeeze & excitation Network。
表6. 模态比較實驗結果
首先我們将scene,food,audio加在最好單模态模型Senet後,發現可以提升mAP一個百分點,但當我們加了I3D之後,性能顯著增加達到了近0.84,通過分析AP提升較大的類目後,發現action相關的顯著提升,進一步驗證了spatial-temporal feature的重要性。另外一方面,第二第三列說明了在LSVC裡,food是非常難分的類别,通過額外在food資料庫上訓練的特征能提升food類别的性能。最佳單模型是融合了I3D,Inception-resnet-v2, Senet,food後的結果,達到0.8485。最後送出的結果是25個混合模型的ensemble,在test集上獲得了mAP:0.8741。
通過這次比賽,我們發現包含時域資訊的C3D特征結合netVLAD起到了很好的效果,主要原因在于對于未裁剪的視訊分類,情況比較複雜,既包含了action,object,還需要識别哪裡是關鍵場景,在action資料庫上pretrain的C3D特征是對于frame level object feature很好的補充,通過netVLAD,模型能夠有效的挖掘出對ground truth貢獻比較大的模态以及時刻。最後在參加比賽時,ensemble通常能将mAP在最好單模型的基礎上提高3到4個點,也很關鍵。我們将繼續研究大規模視訊分類的方法,梳理每個步驟的優化方法,在業務場景中落地。