下载streamingpro
<a href="https://github.com/allwefantasy/streamingpro">readme中有下载地址</a>
如果你使用了 spark 2.0 版本,则要下载对应页面上的spark 安装包。因为目前spark 2.0 默认支持scala 2.11。我提供了一个机遇scala 2.10版本的。
我们假设您将文件放在了/tmp目录下。
启动streamingpro
local模式:
后可进入查询界面:
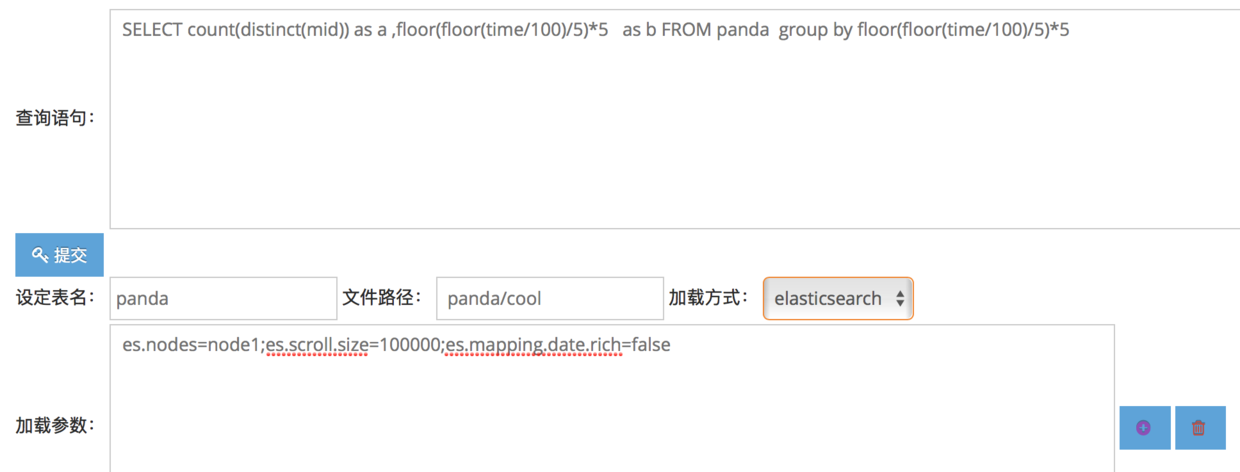
snip20160709_5.png
目前支持elasticsearch 索引,hdfs parquet 等的查询,并且支持多表查询。
除了交互式界面以外,也支持接口查询:
参数支持:

上面的参数都是成套出现,你可以配置多套,从而映射多张表。
集群模式:
接着进入spark-ui界面获取driver的地址,就可以访问了。
因为集群模式,driver的地址是变化的,所以一旦集群启动后我们需要注册到某个地方,从而能然前端知道。目前支持zookeeper的方式,在启动命令行中添加如下几个参数:
之后前端程序只要访问
就能获取ip和端口了。