进入21世纪,新的编程语言如雨后春笋一样不停地冒出来。需求当然是重要的驱动力量,但是在其中起了重要作用的就是工具链的改善。
2000年,uiuc的chris lattner主持开发了一套称为llvm(low level virtual machine)的编译器工具库套件。后来,llvm的scope越来越大,low level virtual machine已经不足以表示llvm的全部,于是,llvm就变成了正式的名字。llvm可以用于常规编译器,jit编译器,汇编器,调试器,静态分析工具等一系列跟编程语言相关的工作。
后来,chris lattner又主持开发了clang,针对c/c++/objective-c的前端。这个编译器直接挑战了gcc的统治地位。成为apple系统的主要编译器,在android中,指名使用clang的模块也越来越多。
2012年,llvm荣获美国计算机学会acm的软件系统大奖,跟unix,www,tcp/ip,tex,java等经典系统作伴。
<a href="http://awards.acm.org/software_system/year.cfm">acm系统奖完全名单</a>
另外再八卦几句llvm的主要作者和架构师chris lattner。这哥们生于1978年。
2005年,chris lattner加入apple。因为apple对于gcc支持objective-c不力的不满,llvm和clang成为apple替代gcc的杀手级武器。
2010年,chris lattner又开始主持开发swift语言。
好了,言归正传。首先我们想说明的是,跟学院派的厚书给大家的印象不同,其实用llvm写个简单的编译器是件容易的事情,因为大部分事情llvm都替我们做了。
我们先看一个使用llvm工具之后,实现一门编程语言的简图:
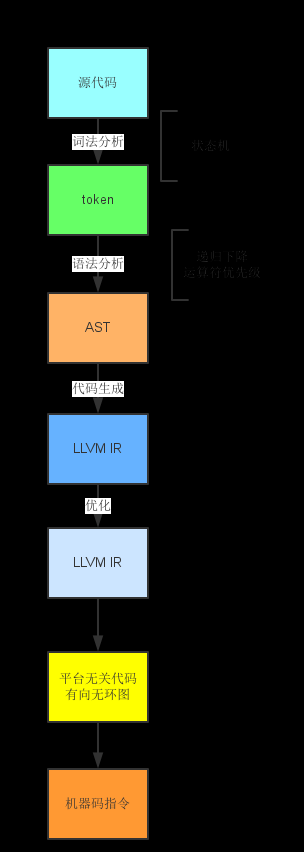
完全需要我们手工,或者依靠其他工具如lex, yacc来做的事情,是从源代码到token的词法分析和从token到ast的语法分析。也就是前端的主要部分需要我们来实现,毕竟我们是这门语言的定义者。在介绍llvm的书里,讲前端的部分都是只占很小的篇幅的,所以大家可以take it easy.
在llvm的万花筒语言例子里,带有注释的词法分析和语法分析也不过400行。大家如果觉得还复杂,后面我会带大家做一些更简单的,先完成一小部分功能,然后迭代式开发。区区百余行代码,不需要学习编译原理。
比如clang就是一个实现了c/c++/objective-c的前端。
从ast转llvm开始,llvm就开始提供一系列的工具帮助我们快速开发。从ir(中间指令代码)到dag(有向无环图)再到机器指令,针对常用的平台,llvm有完善的后端。也就是说,我们只要完成了到ir这一步,后面的工作我们就享有和clang一样的先进生产力了。
口说无凭,有例子为证,这是将二元表达式ast转成ir的函数:
如何生成加减乘除的ir,在这个阶段完全不用关心,llvm会帮我们生成相应的代码。
下面我们再看一个声明函数原型的:
在正则表达式已经成为基本技能的今天,词法分析完全无门槛啊。正常情况下,我们只要写一组正则表达式,或者写个简单的状态机就可以了。
词法分析的输出是将源代码解析成一个个的token。这些token就是有类型和值的一些小单元,比如是关键字,还是数字,还是标识符等等。这个阶段不用管它们是如何组合的,都是干嘛的。
比如一个token类型是数值,值是3. 这个信息就已经足够了,至于这个3干嘛用,后面整理ast的时候再放到合适的位置上去。
至于什么时上下文无关语言,什么是确定有穷自动机,非确定有穷自动机等等这些,暂时都不需要了解。
语法分析诚然是比词法分析要复杂一些。但是幸运的是,对于绝大多数语句和表达式来讲,并不需要高深的知识,“移进-归约”是个好方法,但是在我们学习的相当长的一段时期内都用不上。
语法分析的输出是抽象语法树ast,既然是棵树,自然构造时需要递归。所以在大部分的语句中,我们只按递归下降的方法就足够了。
对于表达式,递归下降还不够用,至少运算符还有优先级啊。所以针对表达式,我们还需要运算符优先分析法。slr,lalr和lr暂时还用不上。
从前面的简单例子中我们已经看到了,这部分大部分调用llvm为我们提供的ir构造工具就可以了。入门阶段我们能想到的,如代码块,函数调用,控制结构等,llvm都为我们准备好了。
llvm主我们提供了大量的优化pass供我们选择和组合。在ir阶段和机器码阶段,我们都将花大量的篇幅来讨论优化。这可能也是我们真正感兴趣的部分。
我们看一个官方的例子,首先定义token的类型,有一种算一种吧。将来扩展都是体力活。
然后就是解析正则表达式,一点技术含量也没有,哈哈~
我对官方的版本做了一点删节,看起来可以更清楚一些:
如果不想手写的话,lex, flex之类的工具很多,就是根据正则表达式来决定token类型,根据类型存一下对应的值。
如果token的类型多,就是搭积木,写正则。都是体力活~
上面介绍了,我们自顶向下,构造抽象语法树。
先定义个根类型吧:
我们先来个简单的,就表示一个数字。这个好办,就一个节点,存个数值。
再来一个例子,变量,就是一个变量名么。赋值是下一步的事情了。
函数原型:
然后我们再看看如何通过token去构造一个数值的ast:
词法分析时,已经把这个数值暂存了,我们把它拿来用就是了。
再看看函数声明的:
先读函数名,再找左括号,然后是参数列表,最后是处理右括号。什么嘛,一点技术含量也没有。。。
上面例子这些,都是没有嵌套的,也不需要递归下降和算符优先。这些是处理比如二元表达式的时候才会遇到的。我们可以先学习容易的,先能把这些容易的组件组成一门虽然语言功能不全,但是真正实现了从源码到机器指令的编译器。
上面的例子都来自官方的例子万花筒(keleidoscope)语言的片段。官方教程当然写得已经足够好,但是还是稍嫌复杂了点,能生成一个可玩的编译器的速度还是有点慢。我打算把学习曲线再降低一下,通过不断地迭代,一点一点搭起可玩的编译器,然后慢慢扩充功能。
先下载llvm
在llvm的tools目录下,下载clang(可选,但是建议):
在llvm的projects目录下,可选下载compiler-rt,libomp,libcxx,libcxxabi。反正我都下载了
既然官方说大部分llvm的开发者都使用ninja,我们也就follow他们吧。
我在mac下,所以使用homebrew来安装cmake和ninja。linux与些类似,gcc版本太旧之类的请自助。windows我还没试过,后面更新一下吧。
在llvm目录下创建build目录
cd build
cmake -g ninja
ninja
从ast转ir开始,我们都要用到llvm的工具啦。先写个小程序学习一下llvm的程序是如何编译的吧:
输出结果如下:
使用llvm库的话,需要一大堆参数.
下面是在我的电脑上的参数:
每次都这么写吓死人了啊。于是llvm为我们提供了llvm-config工具。刚才我那一大串,是用下面的命令行生成的:
完整的编译命令可以这么写:
![swmm与lisflood-fp源码如何一起编译 CMake命令[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)