接入层通常指请求流量的入口,该层的主要目的有:负载均衡、非法请求过滤、请求聚合、缓存、降级、限流、a/b测试、服务质量监控等等,可以参考笔者写的《使用nginx+lua(openresty)开发高性能web应用》。
对于nginx接入层限流可以使用nginx自带了两个模块:连接数限流模块ngx_http_limit_conn_module和漏桶算法实现的请求限流模块ngx_http_limit_req_module。还可以使用openresty提供的lua限流模块lua-resty-limit-traffic进行更复杂的限流场景。
limit_conn用来对某个key对应的总的网络连接数进行限流,可以按照如ip、域名维度进行限流。limit_req用来对某个key对应的请求的平均速率进行限流,并有两种用法:平滑模式(delay)和允许突发模式(nodelay)。
limit_conn是对某个key对应的总的网络连接数进行限流。可以按照ip来限制ip维度的总连接数,或者按照服务域名来限制某个域名的总连接数。但是记住不是每一个请求连接都会被计数器统计,只有那些被nginx处理的且已经读取了整个请求头的请求连接才会被计数器统计。
<b>配置示例:</b>
================================
limit_conn:要配置存放key和计数器的共享内存区域和指定key的最大连接数;此处指定的最大连接数是1,表示nginx最多同时并发处理1个连接;
limit_conn_zone:用来配置限流key、及存放key对应信息的共享内存区域大小;此处的key是“$binary_remote_addr”其表示ip地址,也可以使用如$server_name作为key来限制域名级别的最大连接数;
limit_conn_status:配置被限流后返回的状态码,默认返回503;
limit_conn_log_level:配置记录被限流后的日志级别,默认error级别。
<b>limit_conn的主要执行过程如下所示:</b>
1、请求进入后首先判断当前limit_conn_zone中相应key的连接数是否超出了配置的最大连接数;
2.1、如果超过了配置的最大大小,则被限流,返回limit_conn_status定义的错误状态码;
2.2、否则相应key的连接数加1,并注册请求处理完成的回调函数;
3、进行请求处理;
4、在结束请求阶段会调用注册的回调函数对相应key的连接数减1。
limt_conn可以限流某个key的总并发/请求数,key可以根据需要变化。
<b>按照ip限制并发连接数配置示例:</b>
首先定义ip维度的限流区域:
接着在要限流的location中添加限流逻辑:
即允许每个ip最大并发连接数为2。
使用ab测试工具进行测试,并发数为5个,总的请求数为5个:
将得到如下access.log输出:
此处我们把access log格式设置为log_format main '[$time_local] [$msec] $status';分别是“日期 日期秒/毫秒值 响应状态码”。
如果被限流了,则在error.log中会看到类似如下的内容:
<b></b>
按照域名限制并发连接数配置示例:
首先定义域名维度的限流区域:
即允许每个域名最大并发请求连接数为2;这样配置可以实现服务器最大连接数限制。
limit_req是令牌桶算法实现,用于对指定key对应的请求进行限流,比如按照ip维度限制请求速率。
配置示例:
limit_req:配置限流区域、桶容量(突发容量,默认0)、是否延迟模式(默认延迟);
limit_req_zone:配置限流key、及存放key对应信息的共享内存区域大小、固定请求速率;此处指定的key是“$binary_remote_addr”表示ip地址;固定请求速率使用rate参数配置,支持10r/s和60r/m,即每秒10个请求和每分钟60个请求,不过最终都会转换为每秒的固定请求速率(10r/s为每100毫秒处理一个请求;60r/m,即每1000毫秒处理一个请求)。
limit_req的主要执行过程如下所示:
1、请求进入后首先判断最后一次请求时间相对于当前时间(第一次是0)是否需要限流,如果需要限流则执行步骤2,否则执行步骤3;
2.1、如果没有配置桶容量(burst),则桶容量为0;按照固定速率处理请求;如果请求被限流,则直接返回相应的错误码(默认503);
2.2、如果配置了桶容量(burst>0)且延迟模式(没有配置nodelay);如果桶满了,则新进入的请求被限流;如果没有满则请求会以固定平均速率被处理(按照固定速率并根据需要延迟处理请求,延迟使用休眠实现);
2.3、如果配置了桶容量(burst>0)且非延迟模式(配置了nodelay);不会按照固定速率处理请求,而是允许突发处理请求;如果桶满了,则请求被限流,直接返回相应的错误码;
3、如果没有被限流,则正常处理请求;
4、nginx会在相应时机进行选择一些(3个节点)限流key进行过期处理,进行内存回收。
<b>首先定义ip维度的限流区域:</b>
限制为每秒500个请求,固定平均速率为2毫秒一个请求。
即桶容量为0(burst默认为0),且延迟模式。
使用ab测试工具进行测试,并发数为2个,总的请求数为10个:
虽然每秒允许500个请求,但是因为桶容量为0,所以流入的请求要么被处理要么被限流,无法延迟处理;另外平均速率在2毫秒左右,比如1465381556.410和1465381556.411被处理了;有朋友会说这固定平均速率不是1毫秒嘛,其实这是因为实现算法没那么精准造成的。
如果被限流在error.log中会看到如下内容:
如果被延迟了在error.log(日志级别要info级别)中会看到如下内容:
为了方便测试设置速率为每秒2个请求,即固定平均速率是500毫秒一个请求。
固定平均速率为500毫秒一个请求,通容量为3,如果桶满了新的请求被限流,否则可以进入桶中排队并等待(实现延迟模式)。
为了看出限流效果我们写了一个req.sh脚本:
首先进行6个并发请求6次url,然后休眠300毫秒,然后再进行6个并发请求6次url;中间休眠目的是为了能跨越2秒看到效果,如果看不到如下的效果可以调节休眠时间。
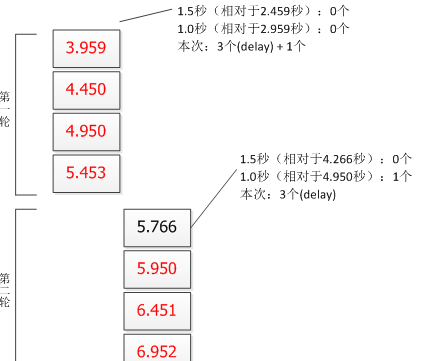
桶容量为3,即桶中在时间窗口内最多流入3个请求,且按照2r/s的固定速率处理请求(即每隔500毫秒处理一个请求);桶计算时间窗口(1.5秒)=速率(2r/s)/桶容量(3),也就是说在这个时间窗口内桶最多暂存3个请求。因此我们要以当前时间往前推1.5秒和1秒来计算时间窗口内的总请求数;另外因为默认是延迟模式,所以时间窗内的请求要被暂存到桶中,并以固定平均速率处理请求:
第一轮:有4个请求处理成功了,按照漏桶桶容量应该最多3个才对;这是因为计算算法的问题,第一次计算因没有参考值,所以第一次计算后,后续的计算才能有参考值,因此第一次成功可以忽略;这个问题影响很小可以忽略;而且按照固定500毫秒的速率处理请求。
第二轮:因为第一轮请求是突发来的,差不多都在1465433203.959时间点,只是因为漏桶将速率进行了平滑变成了固定平均速率(每500毫秒一个请求);而第二轮计算时间应基于1465433203.959;而第二轮突发请求差不多都在1465433205.766时间点,因此计算桶容量的时间窗口应基于1465433203.959和1465433205.766来计算,计算结果为1465433205.766这个时间点漏桶为空了,可以流入桶中3个请求,其他请求被拒绝;又因为第一轮最后一次处理时间是1465433205.453,所以第二轮第一个请求被延迟到了1465433205.950。这里也要注意固定平均速率只是在配置的速率左右,存在计算精度问题,会有一些偏差。
如果桶容量改为1(burst=1),执行req.sh脚本可以看到如下输出:
桶容量为1,按照每1000毫秒一个请求的固定平均速率处理请求。
为了方便测试配置为每秒2个请求,固定平均速率是500毫秒一个请求。
<b>接着在要限流的location中添加限流逻辑:</b>
桶容量为3,如果桶满了直接拒绝新请求,且每秒2最多两个请求,桶按照固定500毫秒的速率以nodelay模式处理请求。
为了看到限流效果我们写了一个req.sh脚本:
<b>将得到类似如下access.log输出:</b>

桶容量为3(,即桶中在时间窗口内最多流入3个请求,且按照2r/s的固定速率处理请求(即每隔500毫秒处理一个请求);桶计算时间窗口(1.5秒)=速率(2r/s)/桶容量(3),也就是说在这个时间窗口内桶最多暂存3个请求。因此我们要以当前时间往前推1.5秒和1秒来计算时间窗口内的总请求数;另外因为配置了nodelay,是非延迟模式,所以允许时间窗内突发请求的;另外从本示例会看出两个问题:
第一轮和第七轮:有4个请求处理成功了;这是因为计算算法的问题,本示例是如果2秒内没有请求,然后接着突然来了很多请求,第一次计算的结果将是不正确的;这个问题影响很小可以忽略;
第五轮:1.0秒计算出来是3个请求;此处也是因计算精度的问题,也就是说limit_req实现的算法不是非常精准的,假设此处看成相对于2.75的话,1.0秒内只有1次请求,所以还是允许1次请求的。
如果限流出错了,可以配置错误页面:
limit_conn_zone/limit_req_zone定义的内存不足,则后续的请求将一直被限流,所以需要根据需求设置好相应的内存大小。
此处的限流都是单nginx的,假设我们接入层有多个nginx,此处就存在和应用级限流相同的问题;那如何处理呢?一种解决办法:建立一个负载均衡层将按照限流key进行一致性哈希算法将请求哈希到接入层nginx上,从而相同key的将打到同一台接入层nginx上;另一种解决方案就是使用nginx+lua(openresty)调用分布式限流逻辑实现。
之前介绍的两个模块使用上比较简单,指定key、指定限流速率等就可以了,如果我们想根据实际情况变化key、变化速率、变化桶大小等这种动态特性,使用标准模块就很难去实现了,因此我们需要一种可编程来解决我们问题;而openresty提供了lua限流模块lua-resty-limit-traffic,通过它可以按照更复杂的业务逻辑进行动态限流处理了。其提供了limit.conn和limit.req实现,算法与nginx limit_conn和limit_req是一样的。
此处我们来实现ngx_http_limit_req_module中的【场景2.2测试】,不要忘记下载lua-resty-limit-traffic模块并添加到openresty的lualib中。
<b>配置用来存放限流用的共享字典:</b>
<b>以下是实现【场景2.2测试】的限流代码limit_req.lua:</b>
即限流逻辑再nginx access阶段被访问,如果不被限流继续后续流程;如果需要被限流要么sleep一段时间继续后续流程,要么返回相应的状态码拒绝请求。
在分布式限流中我们使用了简单的nginx+lua进行分布式限流,有了这个模块也可以使用这个模块来实现分布式限流。
另外在使用nginx+lua时也可以获取ngx.var.connections_active进行过载保护,即如果当前活跃连接数超过阈值进行限流保护。
nginx也提供了limit_rate用来对流量限速,如limit_rate 50k,表示限制下载速度为50k。
到此笔者在工作中涉及的限流用法就介绍完,这些算法中有些允许突发,有些会整形为平滑,有些计算算法简单粗暴;其中令牌桶算法和漏桶算法实现上是类似的,只是表述的方向不太一样,对于业务来说不必刻意去区分它们;因此需要根据实际场景来决定如何限流,最好的算法不一定是最适用的。
https://en.wikipedia.org/wiki/token_bucket
https://en.wikipedia.org/wiki/leaky_bucket
http://redis.io/commands/incr
http://nginx.org/en/docs/http/ngx_http_limit_req_module.html
http://nginx.org/en/docs/http/ngx_http_limit_conn_module.html
https://github.com/openresty/lua-resty-limit-traffic
http://nginx.org/en/docs/http/ngx_http_core_module.html#limit_rate
本文转载自 开涛的博客 kaitao-1234567 微信公众号