dojo/query模块是dojo为开发者提供的dom查询接口。该模块的输出对象是一个使用css选择符来查询dom元素并返回nodelist对象的函数。同时,dojo/query模块也是一个插件,开发者可以使用自定义的查询引擎,query模块会负责将引擎的查询结果包装成dojo自己的nodelist对象。
要理解这个模块就要搞清楚两个问题:
如何查询,查询的原理?
查询结果是什么,如何处理查询结果?
这两个问题涉及到本文的两个主题:选择器引擎和nodelist。
选择器引擎
前端的工作必然涉及到与dom节点打交道,我们经常需要对一个dom节点进行一系列的操作。但我们如何找到这个dom节点呢,为此我们需要一种语言来告诉浏览器我们想要就是这个语言描述的dom节点,这种语言就是css选择器。比如我们想浏览器描述一个dom节点:div > p + .bodhi input[type="checkbox"],它的意思是在div元素下的直接子元素p的下一个class特性中含有bodhi的兄弟节点下的type属性是checkbox的input元素。
选择符种类
元素选择符:通配符*、类型选择符e、类选择符e.class、id选择符e#id
关系选择符:包含(e f)、子选择符(e>f)、相邻选择符(e+f)、兄弟选择符(e~f)
属性选择符: e[att]、e[att="val"]、e[att~="val"]、e[att^="val"]、e[att$="val"]、e[att*="val"]
伪类选择符
伪对象选择符:e:first-letter、e:first-line、e:before、e:after、e::placehoser、e::selection
通过选择器来查询dom节点,最简单的方式是依靠浏览器提供的几个原生接口:getelementbyid、getelementsbytagname、getelementsbyname、getelementsbyclassname、queryselector、queryselectorall。但因为低版本浏览器不完全支持这些接口,而我们实际工作中有需要这些某些高级接口,所以才会有各种各样的选择器引擎。所以选择器引擎就是帮我们查询dom节点的代码类库。
选择器引擎很简单,但是一个高校的选择器引擎会涉及到词法分析和预编译。不懂编译原理的我表示心有余而力不足。
但需要知道的一点是:解析css选择器的时候,都是按照从右到左的顺序来的,目的就是为了提高效率。比如“div p span.bodhi”;如果按照正向查询,我们首先要找到div元素集合,从集合中拿出一个元素,再找其中的p集合,p集合中拿出一个元素找class属性是bodhi的span元素,如果没找到重新回到开头的div元素,继续查找。这样的效率是极低的。相反,如果按照逆向查询,我们首先找出class为bodhi的span元素集合,在一直向上回溯看看祖先元素中有没有选择符内的元素即可,孩子找父亲很容易,但父亲找孩子是困难的。
选择器引擎为了优化效率,每一个选择器都可以被分割为好多部分,每一部分都会涉及到标签名(tag)、特性(attr)、css类(class)、伪节点(persudo)等,分割的方法与选择器引擎有关。比如选择器 div > p + .bodhi input[type="checkbox"]如果按照空格来分割,那它会被分割成以下几部分:
div
>
p
+
.bodhi
input[type="checkbox"]
对于每一部分选择器引擎都会使用一种数据结构来表达这些选择符,如dojo中acme使用的结构:
从这里可以看到有专门的结构来管理不同的类型的选择符。分割出来的每一部分在acme中都会生成一个part,part中有tag、伪元素、属性、元素关系等。。;所有的part都被放到queryparts数组中。然后从右到左每次便利一个part,低版本浏览器虽然不支持高级接口,但是一些低级接口还是支持的,比如:getelementsby*;对于一个part,先匹配tag,然后判断class、attr、id等。这是一种解决方案,但这种方案有很严重的效率问题。(后面这句是猜想)试想一下:我们可不可以把一个part中有效的几项的判断函数来组装成一个函数,对于一个part只执行一次即可。没错,acme就是这样来处理的(这里涉及到预编译问题,看不明白的自动忽略即可。。。)
dojo/query模块的选择器引擎通过dojo/selector/loader来加载。如果没有在dojoconfig中配置selectorengine属性,那么loader模块会自己判断使用acme和是lite引擎,原则是高版本浏览器尽量使用lite,而低版本尽量使用acme。
选择器引擎的代码晦涩难懂,我们只需要关心最终暴露出来的接口的用法即可。
acme:
lite:
nodelist
nodelist来自于原生dom,是一系列dom节点的集合,一个类素组对象,mdn中的解释:
我们看到document.queryselectorall方法返回一个nodelist对象,而且这个方法返回的nodelist对象是一个静态的集合。
所以大多数的前端类库都参照原生设计,查询接口返回的都是一个静态集合。只是有的明确点明如dojo,有的含蓄的实现如jquery。
要了解dojo中的nodelist需要把握以下规则:
dojo中的nodelist就是扩展了能力的array实例。所以需要一个函数将原生array包装起来
nodelist的任何方法返回的还是nodelist实例。就像array的slice、splice还是返回一个array一样
has("array-extensible")的作用是判断数组是否可以被继承,如果原生的数组是可被继承的,那就将nodelist的原型指向一个数组实例,否则指向普通对象。
下面这句话需要扎实的基本功,如果理解这句话,整个脉络就会变得清晰起来。
new的作用等于如下函数:
放到nodelist身上是这样的:
isnew为true,保证了nodelist实例是一个经过扩展的array对象。
nodelist函数的源码:
可以看到如果isnew为false,那就对一个新的array对象进行扩展。
扩展的能力,便是直接在nodelist.prototype上增加的方法。大家直接看源码和我的注释即可。
nodelist提供的很多操作,如:map、filter、concat等,都是借助原生的array提供的相应方法,这些方法返回都是原生的array对象,所以需要对返回的array对象进行包装。有趣的是nodelist提供end()可以回到原始的nodelist中。整个结构如下:
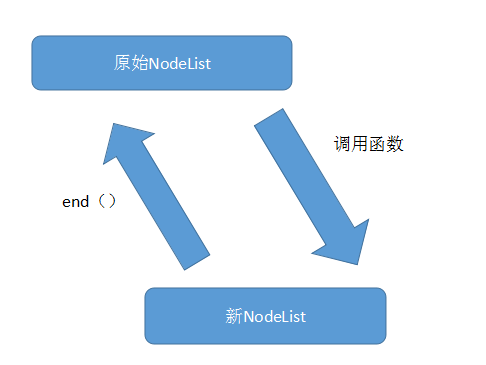
我们来看一下包装函数:
这就是dojo中nodelist的设计!
query模块暴露的方法无非就是对选择器引擎的调用,下面就比较简单了。
如果您觉得这篇文章对您有帮助,请不吝点击推荐,您的鼓励是我分享的动力!!!
![今日头条iOS客户端启动速度优化 技术调研 实测数据[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)