现在基本上出行,一千五百公里内的路基本上我都选择坐高铁。
每次坐高铁,只有一件事情可以做,就是写东西。
写东西呢又全看心情,要是思路不断,可以一直有空闲的好几个小时,又没人打扰,那写东西,是嗖嗖的。
感觉像个打字员一样,每秒平均120字没问题。再加上用五笔嘛又比较快,不会出现拼错的情况。像一些啐啐念的词,都是心里想到就打出来了。
有时候回头看自己写的东西,感觉自己都没这么说过话。
这会想聊一下性能分析中的曲线分析。
我看过很多的性能报告,像这样的表格有很多。
(下面这个是平均响应时间的表格)
<col>
交易码
tps
100
200
300
400
500
600
700
1
业务1
61
73
85
96
107
120
136
2
业务2
52
62
74
83
94
106
3
业务3
63
75
89
112
127
142
4
业务4
46
55
66
84
5
业务5
93
111
130
148
166
187
211
6
业务6
57
68
79
126
7
业务7
101
117
134
150
165
186
208
8
业务8
49
58
76
108
9
业务9
43
51
77
87
98
10
业务10
144
176
203
232
261
292
334
11
业务11
102
137
154
174
197
12
业务12
141
171
230
260
293
335
13
业务13
140
198
227
254
285
326
14
业务14
123
182
242
270
302
349
15
业务15
189
21
251
283
318
360
16
业务16
156
181
207
262
298
17
业务17
133
202
233
266
296
339
385
18
业务18
95
109
132
147
162
19
业务19
129
145
161
20
业务20
103
152
201
228
250
业务21
30
65
total
1849
2421
2619
3204
3592
4049
4581
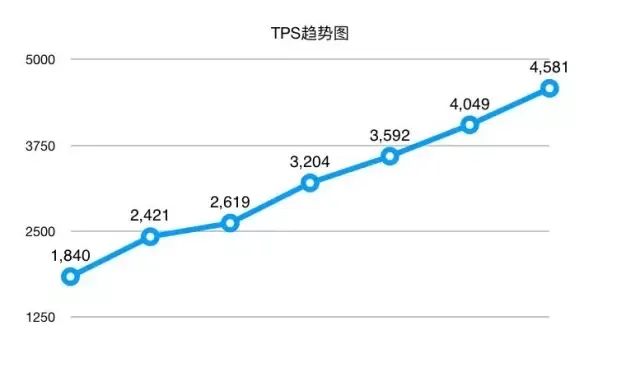
然后画了一个tps的图是这样:
系统资源呢,也是像这样来个表格。
服务器
服务器1
11.01
17.65
22.62
26.53
29.11
31.79
33.35
服务器2
9.25
15.89
20.78
25.46
28.61
30.61
32.99
服务器3
9.95
17.08
21.5
25.83
29.6
31.99
33.5
服务器4
10.82
16.55
21.95
25.41
29.18
31.56
33.9
服务器5
6.9
6.29
6.67
7.01
7.13
8.38
8.46
服务器6
6.8
6.85
7.49
7.38
7.3
8.49
7.77
服务器7
27.24
48
63.77
72.97
79.17
81.88
92.25
服务器8
26.36
46.52
62.21
72.07
77.81
84.72
89.92
然后呢,再画一个图(假设这是cpu的图)。

看到这里,我觉得应该:
有些人心里想,嗯,这图挺好,明明白白的。
也有人心里想,嗯,我就是这么干的。
也有人心里想,嗯,是呀就应该是这样呀,没毛病。
也有人心里想,哦。
我要说,不建议性能报告这么写。为啥呢?
我们先来说说这样写的必要性。
因为有些人做性能场景的时候,是把ramp up和ramp down这两部分的数据给截掉的。我之前问过别人为什么一定要抓稳定的tps和响应时间曲线?为什么问这个问题呢?得到过一个回答:领导要看稳定的曲线;好汇报!
为什么领导要看稳定的曲线,就要千方百计弄个稳定的、合领导心理的、稳定的曲线呢?(因为领导不高兴,就不给钱!那我只能说,没毛病!)这曲线是否反应真实的性能状态呢?
还有一些人是因为看到别人这样写,所以他们也这样写,然而并没有什么反省。
那这样写有什么问题呢?
嗯,其实没啥问题,我也就是问问。(不知道有没有人觉得很无奈看到这里?)
下面正经一点写吧。
我觉得这个曲线要是说反应tps和系统资源的关系。这样说,似乎是没毛病的。所以经常看到下面的描述会是这样的:
总tps在达到4581的时候,服务器7的cpu使用率达到了92.25、服务器8的cpu使用率达到了89.92。
上面这句也就是结果分析中的了。
这样的结果分析有什么用呢?曲线中认真一点的就已经看出来了。为什么还要描述一遍图中的数据又称之为结果分析呢?
我觉得这样的结果分析就是耍流氓。因为没有在分析,而只是在描述数据。做为广而告之的话,我觉得这样写也没什么不可以。但是做为结论分析的话,就不合理了。
那说了半天,你觉得什么才是合理的结果分析的话呢?
我觉得在描述tps、rt、os资源使用率等信息时,应该用实际的图。比如说:我们有一个java写的应用,为了便于引导思路,这里的结构图非常简单。
就是: 压力工具 <-> 应用服务器 <-> db服务器
tps图是这样的:
响应时间图是这样的:
应用服务器 cpu图是这样的。
应用服务器 io是这样的:
应用服务器 gc状态是这样的:
应用服务器 网络是这样的:
db cpu是这样的(其他资源不帖了,我帖累了,默认其他的都没问题吧):
上面的信息我觉得帖得够了。基本上有经验做性能分析的人,看到上面的图就知道一个明确的信息:这个系统有瓶颈。为什么?因为趋势!!
所以,性能分析要趋势分析,要看的是很多数据组成的曲线。而不是每个梯度找个平均值来描述下值就是结果分析了。
另外一个不能用均值描述的原因是,有很多测试,在资源的分配、增减的时候会出现响应时间和另外一些资源的毛刺。
毛刺也是需要解释的。比如说我发的tps图中就出现了00:10:00的时候,tps有下降的情况,并且后面还持续了一会。在这时候也看到了有响应时间的增加。
为什么会出现这种情况呢?这个也是要在分析中解释的。在我这个图中是因为数据库主机中有其他的任务导致了这一段的sql执行时间普遍增加了几个毫秒。
图中的曲线的解释是需要层层分析,慢慢细化,这个过程就是来描述上线后的情形。如果出现了某个用户的响应时间比较长,也是在意料之中的。
结果分析是要描述单个曲线的同时,比如说,上图中的tps是有按梯度增加的,也有没增加的,这就是场景的设计了。再结合响应时间图,有几个业务在随着tps的增加而增加,增加的梯度和方差也都从结果中可以看到。 从tps、rt上,可以把场景的设计明显的看出来。
然后再从tps、rt、资源图上,可以明显知道性能瓶颈是不是有的。但是这并不是说,瓶颈是可以从图上反应出来,那还是不行的。
我现在在做项目中都会明确地说。如果硬件资源用不上去,那就先用硬件资源;硬件资源用上去了,目标没达到,那就开始调优。
如果资源没用上去,tps也不增加,响应时间又增加了,那必须得找到问题在哪。在性能结果分析中也要描述当前的状态是什么,合理不合理。
还要描述性能瓶颈在什么地方。给出上线维护的建议。
性能分析首先是全局趋势分析,然后层层细化的过程。
如果只是为了报告的报告,那就另当别论了。
大家可以关注我们的公众号:7dgroup