linux性能定位思路:
简介:
本文主要从以下四个维度指标,来讲解Linux监控及性能问题定位
CPU 、Memory 、 IO 、Network
一、top命令解析
使用top命令查看进程使用资源情况

| top - 19:45:57 | 当前系统时间 |
| 50 days | 系统已经运行了50天 |
| 1 user | 当前登陆1个用户 |
| load average | 系统负载,反应进程在CPU排队情况,等于【正在运行的进程+等待CPU时间片段的进程+等待IO的进程】三个数值分别表示为过去1分钟/5分钟/15分钟的负载平均值。正常值为小于CPU的颗粒数 |
| Task: 96 total | 总进程数 |
| 1 running | 正在运行的进程数 |
| 95 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 冻结进程数(僵尸进程数) |
| %Cpu(s): | |
| 0.7 us | 用户进程消耗的cpu,一般小于70%/80%是正常的 |
| 1.0 sy | 系统内核进程消耗的cpu(操作系统的底层资源是在内核完成的,比如读写磁盘。超过10%就很高了,可能是IO、中断、上下文切换导致的 |
| 0.0 ni | 改变过优先级的进程占用CPU的百分比 |
| 98.3 id | 空闲cpu百分比 |
| 0.0 wa | 等待IO的进程所消耗的占CPU的百分比,直观说就是 如果这个值很高 就代表 cpu利用率不高 但是io很繁忙,需要去查一下io |
| 0.0 hi | 硬件中断所消耗的CPU占比(硬中断 Hardware IRQ) |
| 0.0 si | 软件中断所消耗的CPU占比(软中断 Software Interrupts) |
| 0.0 st | 不需要关注 |
| KiB Mem : | |
| 1883564 total | 物理内存总量 |
| 554480 free | 空闲内存总量 |
| 362208 used | 使用的物理内存总量 |
| 966876 buff/cache | 用作内核缓存的内存量 |
| cache缓存 | 存的是最近一段时间内存频繁从磁盘中读取的热点数据,为了避免频繁从磁盘取热点数据。如果内存不足时,cache缓存会变小,将内存让出来 |
| buff缓冲 | 内存不是实时把数据写入磁盘中的,而是一批一批的数据写到磁盘中。一批一批的数据就是 buffers |
| KiB Swap: | 交换区内存,一小部分在内存,大部分在磁盘上。在磁盘上开辟了一块空间,当作内存来使用。最终运行在磁盘上。内存的运行速度至少是磁盘运行速度的几百倍。所以交换区的内存,运行速度非常慢。swap used值变高,说明物理内存不够用,而且系统开始变慢。从功能上讲,交换分区主要是在内存不够用的时候,将部分内存上的数据交换到swap空间上,以便让系统不会因内存不够用而导致oom或者更致命的情况出现。 |
| 0 total | 交换区总量 |
| 0 free | 空闲交换区总量 |
| 0 used | 使用的交换区总量 |
| 1325836 avail Mem | 缓冲的交换区总量 |
| 进程信息 | |
| PID | 进程id |
| PR | 优先级(值越低优先级越高) |
| NI | nice值,负值表示高优先级,正值表示低优先级 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。(只需要观察这个值)RES=CODE+DATA |
| SHR | 共享内存大小,单位kb。这个值可能会比较大,因为可能是多个进程共享的。 |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| %MEM | 进程使用的物理内存百分比 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| COMMAND | 命令名/命令行 |
%iowait 这个值的含义,不用去关注,直观说就是 如果这个值很高 就代表 cpu利用率不高 但是io很繁忙。只知道高了,就去查io问题就行了
%iowait 官方解释
Percentage of time that the CPU or CPUs were idle during
which the system had an outstanding disk I/O request
%iowait 表示在一个采样周期内有百分之几的时间属于以下情况:CPU空闲、并且有仍未完成的I/O请求。 1.1top命令
默认进入top时,各进程是按照CPU的占用量来排序的
多核cpu情况下,在top基本视图中,按键盘数字“1”可以监控每个逻辑CPU的状况
查看具体某个进程的信息
top -p pid(进程id)
top -p 620
查看某个进程下的线程信息
输入H,显示所有线程的情况
top -p pid #只看某个进程的数据
top -H -p pid #查看某个进程的线程数据
top -H -p 30350
显示完整命令
top -c
或者先输入top命令,然后再按c,来切换显示进程的完成命令
注意:
ctrl+z 退出top命令,但是top进程依然在
ctrl+c退出top命令,并杀死该进程。
输入M,按内存使用率排序
输入P,按cpu使用率来排序,默认也是cpu使用率排序
二、IO
2.0 io
读写
2.1 IO与cpu的关系
参考链接:
I/O会一直占用CPU吗? - 知乎
IO所需要的CPU资源非常少。大部分工作是分派给DMA完成的。
2.2 IO整个流程:
CPU计算文件地址 ——> 委派DMA读取文件 ——> DMA接管总线 ——> CPU的A进程阻塞,挂起——> CPU切换到B进程 ——> DMA读完文件后通知CPU(一个中断异常)——> CPU切换回A进程操作文件
IO设备发送中断,CPU收到中断后,挂起当前的进程,然后处理中断,处理完后,回到之前的进程
计算机硬件上使用DMA来访问磁盘等IO,也就是请求发出后,CPU就不再管了,直到DMA处理器完成任务,再通过中断告诉CPU完成了。
所以,单独的一个IO时间,对CPU的占用是很少的,阻塞了就更不会占用CPU了,因为程序都不继续运行了,CPU时间交给其它线程和进程了。
虽然IO不会占用大量的CPU时间,但是非常频繁的IO还是会非常浪费CPU时间的,所以面对大量IO的任务,有时候是需要算法来合并IO,或者通过cache来缓解IO压力的。
2.3
查看io的常用三个命令
iostat -x
pidstat -d
sar -d
三、load average(平均负载)
平均负载:
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。
所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
通俗一点讲,负载就是正在使用/等待cpu的队列 与 等待io的队列之和。
负载的解读:
首先,假设最简单的情况,你的系统只有一个CPU,所有的运算都必须由这个CPU来完成。
那么,我们不妨把这个CPU想象成一座大桥,桥上只有一根车道,所有车辆都必须从这根车道上通过。(很显然,这座桥只能单向通行。)
系统负荷为0,意味着大桥上一辆车也没有。
系统负荷为0.5,意味着大桥一半的路段有车。
系统负荷为1.0,意味着大桥的所有路段都有车,也就是说大桥已经"满"了。但是必须注意的是,直到此时大桥还是能顺畅通行的。
系统负荷为1.7,意味着车辆太多了,大桥已经被占满了(100%),后面等着上桥的车辆为桥面车辆的70%。以此类推,系统负荷2.0,意味着等待上桥的车辆与桥面的车辆一样多;系统负荷3.0,意味着等待上桥的车辆是桥面车辆的2倍。总之,当系统负荷大于1,后面的车辆就必须等待了;系统负荷越大,过桥就必须等得越久。
CPU的系统负荷,基本上等同于上面的类比。大桥的通行能力,就是CPU的最大工作量;桥梁上的车辆,就是一个个等待CPU处理的进程(process)。
如果CPU每分钟最多处理100个进程,那么系统负荷0.2,意味着CPU在这1分钟里只处理20个进程;系统负荷1.0,意味着CPU在这1分钟里正好处理100个进程;系统负荷1.7,意味着除了CPU正在处理的100个进程以外,还有70个进程正排队等着CPU处理。
为了电脑顺畅运行,系统负荷最好不要超过1.0,这样就没有进程需要等待了,所有进程都能第一时间得到处理。很显然,1.0是一个关键值,超过这个值,系统就不在最佳状态了,你要动手干预了。
系统负荷的经验法则
1.0是系统负荷的理想值吗?
不一定,系统管理员往往会留一点余地,当这个值达到0.7,就应当引起注意了。经验法则是这样的:
当系统负荷持续大于0.7(但 70% 这个数字并不是绝对的),你必须开始调查了,问题出在哪里,防止情况恶化。
当系统负荷持续大于1.0,你必须动手寻找解决办法,把这个值降下来。
当系统负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。你不应该让系统达到这个值。
平均负载与cpu使用率
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待I/O 的进程, 而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高
多处理器情况
上面,我们假设你的电脑只有1个CPU。如果你的电脑装了2个CPU,会发生什么情况呢?
2个CPU,意味着电脑的处理能力翻了一倍,能够同时处理的进程数量也翻了一倍。
还是用大桥来类比,两个CPU就意味着大桥有两根车道了,通车能力翻倍了。
所以,2个CPU表明系统负荷可以达到2.0,此时每个CPU都达到100%的工作量。推广开来,n个CPU的电脑,可接受的系统负荷最大为n。
多核处理器情况
芯片厂商往往在一个CPU内部,包含多个CPU核心,这被称为多核CPU。
在系统负荷方面,多核CPU与多CPU效果类似,所以考虑系统负荷的时候,必须考虑这台电脑有几个CPU、每个CPU有几个核心。然后,把系统负荷除以总的核心数,只要每个核心的负荷不超过1.0,就表明电脑正常运行。
怎么知道电脑有多少个CPU核心呢?
"cat /proc/cpuinfo"命令,可以查看CPU信息。
"grep -c 'model name' /proc/cpuinfo"命令,直接返回CPU的总核心数。
最佳观察时长
最后一个问题,"load average"一共返回三个平均值----1分钟系统负荷、5分钟系统负荷,15分钟系统负荷,
三个不同时间间隔的平均值,其实给我们提供了,分析系统负载趋势的数据来源,让我们能更全面、更立体地理解目前的负载状况
如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
但如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去15 分钟内却有很大的负载。
反过来,如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦 1分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化了。
四、进程的各种状态
就绪状态(Running):
进程已经准备好,已分配到所需资源,只要分配到CPU就能够立即运行。
运行态和就绪态之间的转换是由进程调度程序引起的,进程调度程序是操作系统的一部分。
就绪状态不消耗cpu
运行状态(Running):
进程处于就绪状态被调度后,进程进入执行状态
可中断睡眠状态:
正在运行的进程由于某些事件而暂时无法运行,进程受到阻塞。在条件满足就会被唤醒(也可以提前被信号打断唤醒),进入就绪状态等待系统调用
一般都是等待事务,这个过程很长,不知道啥时候返回结果。比如python中的input
不可中断睡眠状态(磁盘休眠状态):
除了不会因为接收到信号而被唤醒运行之外,他与可中断状态相同。
等待资源,过程很快会返回结果,毫秒级别,不用打断。在满足请求时进入就绪状态等待系统调用。
在这个状态的进程通常会等待IO的结束。
比如:
cpu是在内存里运行的,数据缺失,会去磁盘里取,读取磁盘,等待数据磁盘从数据返回,这个过程是就是不可中断。
这个过程很快。
终止状态/僵尸状态(ZOMBIE):
该进程已经结束了,但是父进程还没有使用wait()系统调用。因为父进程不能读取到子进程退出的返回代码,所以就会产生僵死进程。为了父进程能够获知它的消息,子进程的进程描述符仍然被保留,一但父进程调用wait(),进程描述符就会被释放。该进程无法再被执行
停止状态:
进程停止执行,进程不能投入运行。通常这种状态发生在接受到SIGSTOP、SIGTSTP、SIGTTIN、SIGOUT等信号(停止信号)的时候,正常停止。此外,在调试期间接受到的任何信号,都会使进程进入这种状态。
使用top命令,查看s列,为每个进程的状态。
线程的就绪状态与运行状态,都是R(RUNNING)状态。我们无法从R上区分当前进程到底是就绪还是正在运行。
进程与线程:
进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
五、CPU
cpu 相当于 车间工人,内存相当于车间,磁盘相当于仓库。cpu只能在内存里工作。
5.1 CPU数量&每颗物理CPU的核数
一个服务器主板可以插多个CPU称为多路,一个CPU可以有多个物理核。
如果开启了超线程,一个物理核可以分成n个逻辑核(一般是2),n为超线程的数量。
总核数 = 物理CPU个数 * 每颗物理CPU的核数
总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
注:我们常说的几核一般不包括逻辑核数。
查看物理cpu数:主板上实际插入的cpu数量
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l cpu核数:单块CPU上面能处理数据的芯片组的数量,如双核、四核等 (cpu cores)
cat /proc/cpuinfo| grep "cpu cores"| uniq 注:查的是每颗CPU的物理核数
逻辑cpu数:一般情况下,逻辑cpu=物理CPU个数×每颗核数,如果不相等的话,则表示服务器的CPU支持超线程技术
查看单颗CPU的逻辑核数
cat /proc/cpuinfo | grep “siblings” | uniq 查看所有CPU的逻辑核数
cat /proc/cpuinfo| grep "processor"| wc -l grep -c 'model name' /proc/cpuinfo 查看CPU信息:
cat /proc/cpuinfo 系统上只有一个cpu,但是这个cpu的物理核是4。代表在一瞬间,有4个人在干活。
使用top命令,观察cpu。
%Cpu(s),s说明是复数,存在多个cpu,我们按1,可以展开
cpu0负责所有cpu内核的调度。
使用top命令,查看cpu数据时,发现cpu0的使用率远远高于cpu1,可能导致问题的原因
1、cpu调度有问题
2、某些应用程序
5.2 云服务器的cpu
我查看了一下自己买的华为云服务的cpu规格
2vCPUs:
云服务器一般都是说几核,如2核,其实就是vCPU,几核就是几个vCPU。如2核就是2vCPU,注意,这里是2个虚拟cpu,并不是2个物理cpu。(1个物理cpu可以虚拟出多个vCPU)
5.3 CPU工作原理&CPU时间片
cpu 时间片消耗表|cpu消耗表 - 小林野夫 - 博客园
1秒=1000毫秒(ms)=1,000,000 微秒(μs)=1,000,000,000 纳秒(ns)=1,000,000,000,000 皮秒(ps)
举个例子:cpu 相当于一个 车间工人,将1秒钟,分成10份,第一个1/10秒,做a事情,下一个1/10秒,做b事情,这样轮流依次做不同的事情。
cpu时间片的大小通常为10~100ms,在 Windows 操作系统上,一个时间片通常在十几毫秒(译者注:默认 15.625ms)
时间片即CPU分配给各个程序的时间,每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间,使各个程序从表面上看是同时进行的。
如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程。如果进程在时间片结束前阻塞或结束,则CPU当即进行切换。而不会造成CPU资源浪费。
如果时间片为20ms,某个线程所需要的时间小于20ms,那么不到20ms就会切换到其他线程;如果一个线程所需的时间超过20ms,系统也最多只给20ms。
在宏观上:我们可以同时打开多个应用程序,每个程序并行不悖,同时运行。
但在微观上:由于只有一个CPU,一次只能处理程序要求的一部分,如何处理公平,一种方法就是引入时间片,每个程序轮流执行。
进程时间片:20ms
进程上下文切换:10ms
线程上下文切换 :3.8μs,这个分为同进程线程和非同进程线程他们时间不一样
中断上下文切换:很短
GC:对第0代执行一次垃圾回收时间不超过1ms
固态硬盘访问10-100us
机械硬盘访问1-10ms
5.4 CPU各种指标
us:用户进程消耗的cpu
sy:系统内核进程消耗的cpu
哪些行为消耗us:
进程在执行业务逻辑的时候,消耗cpu,属于us。
当us消耗过高时,我们需要关注哪些用户进程导致了us过高。
哪些行为消耗sy:
系统写日志,对cpu的消耗,属于sy。
进程的上下文切换,对cpu的消耗,属于sy。
操作系统的底层资源是在内核完成的,比如读写磁盘。
超过10%就很高了,可能是IO、中断、上下文切换导致的。需要查看wa与si。
wa高,则是io导致的,si高则是上下文切换、中断导致的。
5.4.3NI&PR
ni,用户进程空间内改变过优先级的进程占用CPU百分比
两列:PR(priority)进程优先级和 NI(nice)优先级切换等级
PR 列的值是:rt 或大于等于 0 的数字;NI 列的值是:[-20, 19]之间的数字
NI -- Nice Value
这项任务的优先价值。负的nice值意味着更高的优先级,而正的nice值意味着更低的优先级。
该字段中的0表示在确定任务的调度能力时不会调整优先级。
PR -- Priority 优先事项
任务的调度优先级。如果在该字段中看到“rt”,则表示任务正在实时调度优先级下运行。
任务列表数量很多,一般都超过了 CPU 的数量,超过了 CPU 的数量的进程,都要使用 CPU,就要排队,排队,有 3 种队列:Deadline 最后期限队列 dl_rq,实时任务队列 rt_rq,cfs 公平队列 cfs_rq. 每种队列中排队的任务比较多,事情就会比较复杂,所以需要有默认的、大家都遵循的‘优先级’,和出现紧急情况,能灵活调整的‘调度策略’。
六、硬盘
数据最终的存贮,在硬盘。如mysql的数据,存在硬盘里。但是系统存取硬盘数据的速度比较慢,在内存里存取数据比较快。
在性能方面,固态硬盘读写速度是远远超过机械硬盘的。
固态硬盘访问10-100us
机械硬盘访问1-10ms
七、内存
把硬盘里的数据,取出来,放到内存里,然后cpu在内存里对数据进行加工。
新生成的数据,也是在内存里生成,然后同步到磁盘里。
内存往磁盘里同步数据,不是实时进行的。比如日常工作过程中,使用电脑编辑文档,没有做保存,电脑断电重启后,发现文档里的内容丢失了。因为这些数据在内存里,并没有同步到磁盘里。
1、内存是什么?
1)内存又称主存,是 CPU 能直接寻址的存储空间,由半导体器件制成
2)内存的特点是存取速率快
2、内存的作用
- 1)暂时存放 cpu 的运算数据
- 2)硬盘等外部存储器交换的数据
- 3)保障 cpu 计算的稳定性和高性能
内存页:
一块内存的大小,一般一页时4kb(可以自己调),mysql里,一块内存快时16kb。取一页数据,就是取出16kb的数据。
如果一页内存时,数据不在内存时,这是会产生缺页异常,但不是真的异常,只是因为内存里缺少数据,这是需要去磁盘读取数据,放到内存里,此时缺页异常就恢复了。
使用top命令查看内存
Mem 物理内存、swap 内存
KiB Swap 内存:
交换区内存,一小部分在内存,大部分在磁盘上。在磁盘上开辟了一块空间,当作内存来使用。最终运行在磁盘上。内存的运行速度至少是磁盘运行速度的几百倍。所以交换区的内存,运行速度非常慢。swap used值变高,说明物理内存不够用,而且系统开始变慢。从功能上讲,交换分区主要是在内存不够用的时候,将部分内存上的数据交换到swap空间上,以便让系统不会因内存不够用而导致oom或者更致命的情况出现。
分析Mem 物理内存:
查看total总量、free空闲、used使用的内存。
分析swap 内存:
看有没有在使用swap内存,不看total,看used,不是看used被使用,而是观察used的使用量,往上升,才代表swap内存被使用。当使用swap内存时,系统运行速度会变慢。
Mem物理内存free的值不会为0.
系统都有保护措施,如果内存彻底为0了,那么系统连shutup、teardown 关机 重启这些命令都不能执行。所以,系统设置了一个保护值,这个值在几十M左右。所以free这个值,不会为0。
什么时候内存就不足了?
java应用程序,除了内存溢出会导致内存不足,其他的比如内存4g,用了3个g,这不是内存不足。java应用程序内存不足,只有一个表现,就是程序报内存溢出了,其他都不是内存不足。因为java程序是先申请内存,java进程启动时,会申请分配很大的内存,内存使用率肯定很高。
如果其他的程序,非预申请程序。内存使用率不要超过85%。
buffers/cache
cache 缓存:
缓存的是最近一段时间频繁从磁盘里取的文件(热点数据),缓存也是在内存里。
这些热点数据,用完之后并没有丢弃,而是缓存在了内存里,为了避免频繁的从磁盘里交互数据。
当内存紧张时,缓存数据会变小。
buffers缓冲:
向磁盘里写的数据。
使用top命令,查看进程的列信息。
只需要关注RES就可以了,RES表示该进程占用的物理内存。(SHR是共享内存,VITR=SHR+虚拟内存)
八、中断
中断概念:
中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的 CPU 暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。
Linux中通常分为硬中断(Hardware IRQ)和软中断(Software Interrupts)
(1) 硬中断
由与系统相连的外设(比如网卡、硬盘)自动产生的。主要是用来通知操作系统系统外设状态的变化。比如当网卡收到数据包
的时候,就会发出一个中断。我们通常所说的中断指的是硬中断(hardirq)。
(2) 软中断
为了满足实时系统的要求,中断处理应该是越快越好。linux为了实现这个特点,当中断发生的时候,硬中断处理那些短时间
就可以完成的工作,而将那些处理事件比较长的工作,放到中断之后来完成,也就是软中断(softirq)来完成。
导致软中断的情况:
主动中断:在时间片内cpu完成了任务,主动让出cpu
被动中断:在时间片内,cpu没有完成任务,被动让出cpu
用户进程主动发起中断
大量中断导致系统上下文切换,会消耗内核cpu(系统cpu)
九、上下文切换
参考博客:
在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
3种上下文切换情况:
根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。
进程内核空间/用户空间切换导致CPU上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,CPU 特权等级的 Ring 0 和 Ring 3。进程既可以在用户空间运行,又可以在内核空间中运行。
进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。
比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
系统调用(进程内核空间/用户空间切换)的过程发生 CPU 上下文切换
CPU 寄存器里原来用户态的指令位置,需要先保存起来。
接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。
最后才是跳转到内核态运行内核任务 。
而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。
所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的:
进程上下文切换,是指从一个进程切换到另一个进程运行。
而系统调用过程中一直是同一个进程在运行
进程上下文切换
进程是由内核来管理和调度的,进程的切换只能发生在内核态。
所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:
在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;
而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在 CPU 上运行才能完成。
每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。
这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。
大量的上下文切换会消耗我们的cpu,导致平均负载升高。
进程切换时才需要切换上下文,换句话说,只有在进程调度的时候,才需要切换上下文。
Linux 为每个 CPU 都维护了一个就绪队列,将活跃进程(即正在运行和正在等待CPU 的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。
进程在什么时候才会被调度到cpu上运行:
场景一:
就是一个进程执行完终止了,它之前使用的 CPU 会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行。
场景二:
为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。
这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
场景三:
进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
场景四:
当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
场景五:
当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
场景六:
发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
线程上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。
所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
可以这么理解线程和进程:
当进程只有一个线程时,可以认为进程就等于线程。
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
线程的上下文切换其实就可以分为两种情况:
第一种,前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据
同进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。
中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。另外,跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题
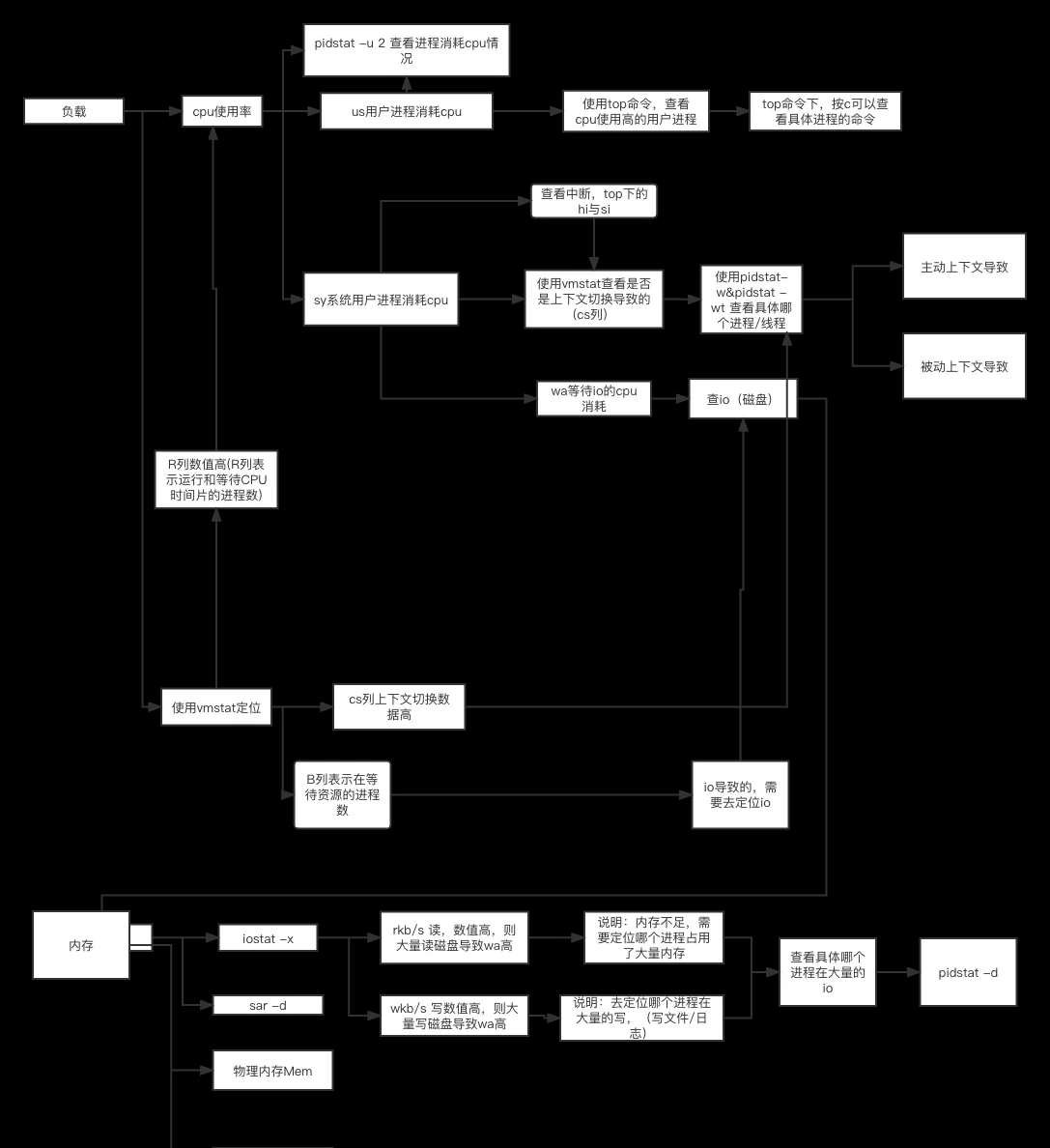
十、vmstat介绍
vmstat可以对操作系统的内存信息、进程状态、 CPU活动、磁盘等信息进行监控,不足之处是无法 对某个进程进行深入分析。
vmstat
vmstat [-a] [-n] [-S unit] [delay [ count]]
-a:显示活跃和非活跃内存
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这 时刷新次数为无穷。
-d:显示各个磁盘相关统计信息。
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、
1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
-p:显示指定磁盘分区统计信息
-D:显示磁盘总体信息 一般用法
- delay:刷新时间间隔。如果不指定,只显示一条结果。
- count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这 时刷新次数为无穷。
vmstat 10
10秒刷新一次结果,只要不停止,会持续显示刷新后的数据
vmstat 10 5
10秒刷新一次结果,一共显示5次数据
字段说明
| procs | |
| R列 | R列表示运行和等待CPU时间片的进程数,这个值如果长期大于系统CPU个数, 说明CPU不足,需要增加CPU |
| B列 | B列表示在等待资源的进程数,比如正在等待I/O或者内存交换等 |
| memory | |
| swpd列 | swpd列表示切换到内存交换区的内存大小(单位KB),通俗讲就是虚拟内存的 大小。如果swap值不为0或者比较大,只要si、so的值长期为0.这种情况一般属 于正常情况。 |
| free列 | free列表示当前空闲的物理内存(单位KB) |
| Buff列 | Buff列表示baffers cached内存大小,也就是缓冲大小,一般对块设备的读写 才需要缓冲。 |
| Cache列 | Cache列表示page cached的内存大小,也就是缓存大小,一般作为文件系统进 行缓冲,频繁访问的文件都会被缓存,如果cache值非常大说明缓存文件比较多, 如果此时io中的bi比较小,说明文件系统效率比较好。 |
| swap | |
| Si列 | Si列表示由磁盘调入内存,也就是内存进入内存交换区的内存大小。 |
| so列 | so列表示由内存进入磁盘,也就是有内存交换区进入内存的内存大小。 一般情况下,si、so的值都为0,如果si、so的值长期不为0,则说明系统内存不 足,需要增加系统内存。 |
| io | |
| bi列 | bi列表示由块设备读入数据的总量,即读磁盘,单位kb/s。 |
| bo列 | bo列表示写到块设备数据的总量,即写磁盘,单位kb/s |
| 备注 | 如果bi+bo值过大,且wa值较大,则表示系统磁盘IO瓶颈。 |
| system | |
| in列 | in列(interrupt)表示某一时间间隔内观测到的每秒设备中断数 |
| cs列 | cs列表示每秒产生的上下文切换次数。(6位数以上才算不正常) |
| 备注 | 这2个值越大,则由内核消耗的CPU就越多 |
| cpu | |
| us列 | us列表示用户进程消耗的CPU时间百分比,us值越高,说明用户进程消耗cpu时 间越多,如果长期大于50%,则需要考虑优化程序或者算法。 |
| sy列 | sy列表示系统内核进程消耗的CPU时间百分比,一般来说us+sy应该小于80%, 如果大于80%,说明可能出现CPU瓶颈。 |
| id列 | id列表示CPU处在空闲状态的时间百分比 |
| wa列 | wa列表示等待所占的CPU时间百分比,wa值越高,说明I/O等待越严重,根据经 验wa的参考值为20%,如果超过20%,说明I/O等待严重,引起I/O等待的原因可能 是磁盘大量随机读写造成的,也可能是磁盘或者此监控器的带宽瓶颈(主要是块 操作)造成的。 |
| 备注 | 如果评估CPU,需要重点关注procs项的r列值和CPU项的us、sy、wa列 的值。 |
R列+B列 就是我们理论上的负载
查看系统上下文切换情况
使用 vmstat 这个工具,来查询系统的上下文切换情况 ,主要关注以下几项。
主要关注以下四个数据:
| system | |
| cs(context switch) | 是每秒上下文切换的次数 |
| in(interrupt) | 则是每秒中断的次数。 |
| rocs | |
| r(Running or Runnable) | 是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。 |
| b(Blocked) | 则是处于不可中断睡眠状态的进程数 |
十一、pidstat工具介绍
pidstat 是sysstat 工具下的一个命令
安装:
yum install -y sysstat
用法
用法: pidstat [ 选项 ] [ [ ] ]
Options are:
[ -d ] [ -h ] [ -I ] [ -l ] [ -R ] [ -r ] [ -s ] [ -t ] [ -U [ ] ]
[ -u ] [ -V ] [ -v ] [ -w ] [ -C ] [ -G ] [ --human ]
[ -p { [,...] | SELF | ALL } ] [ -T { TASK | CHILD | ALL } ]
常用参数
- -u:默认的参数,显示各个进程的cpu使用统计
- -r:显示各个进程的内存使用统计
- -d:显示各个进程的IO使用情况
- -p:指定进程号
- -w:显示每个进程的上下文切换情况
- -t:显示选择任务的线程的统计信息外的额外信息
所有进程cpu的使用情况
pidstat 说明:
- PID:进程ID
- %usr:进程在用户空间占用cpu的百分比
- %system:进程在内核空间占用cpu的百分比
- %guest:进程在虚拟机占用cpu的百分比
- %CPU:进程占用cpu的百分比
- CPU:处理进程的cpu编号(可以查看当前进程在哪个cpu上运行)
- %wait:
- Command:当前进程对应的命令
查看内存使用情况
pidstat -r -p 2818 1 4
pid为2818的进程,四秒钟的内存使用情况,每秒展示一次,展示四次
也可以直接pidstat -r,是全部进程的内存使用情况
[root@iz2ze2w3v37sit3vf71kuez ~]# pidstat -r -p 2818 1 4
Linux 3.10.0-514.26.2.el7.x86_64 (iz2ze2w3v37sit3vf71kuez) 2021年08月13日 _x86_64_ (1 CPU)
20时22分32秒 UID PID minflt/s majflt/s VSZ RSS %MEM Command
20时22分33秒 0 2818 0.00 0.00 95252 3824 0.20 sysbench
20时22分34秒 0 2818 0.00 0.00 95252 3824 0.20 sysbench
20时22分35秒 0 2818 0.00 0.00 95252 3824 0.20 sysbench
20时22分36秒 0 2818 0.00 0.00 95252 3824 0.20 sysbench
平均时间: 0 2818 0.00 0.00 95252 3824 0.20 sysbench 说明:
PID:进程标识符
Minflt/s:任务每秒发生的次要错误,不需要从磁盘中加载页
Majflt/s:任务每秒发生的主要错误,需要从磁盘中加载页
VSZ:虚拟地址大小,虚拟内存的使用KB
RSS:常驻集合大小,非交换区内存使用KB
Command:task命令名 11.1查看各个进程IO使用情况
命令
pidstat -d
[root@iz2ze2w3v37sit3vf71kuez ~]# pidstat -d
Linux 3.10.0-514.26.2.el7.x86_64 (iz2ze2w3v37sit3vf71kuez) 2021年08月14日 _x86_64_ (1 CPU)
07时48分00秒 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
07时48分00秒 0 1 0.73 2.25 0.08 433 systemd
07时48分00秒 0 25 0.00 0.00 0.00 54 kswapd0
07时48分00秒 0 27 0.00 0.00 0.00 0 khugepaged
07时48分00秒 0 215 0.00 0.00 0.00 3937 kworker/u4:2
07时48分00秒 0 258 0.00 0.60 0.00 56303 jbd2/vda1-8
07时48分00秒 0 326 0.05 0.26 0.00 2760 systemd-journal
07时48分00秒 0 350 0.00 0.00 0.00 47 systemd-udevd
07时48分00秒 0 420 0.00 0.02 0.00 413 auditd 字段说明
- PID:进程id
- kB_rd/s:每秒从磁盘读取的KB
- kB_wr/s:每秒写入磁盘KB
- kB_ccwr/s:任务取消的写入磁盘的KB。当任务截断脏的pagecache的时候会发生。
- COMMAND:task的命令名
- iodelay: IO的延迟时间
IO延迟是指控制器将IO指令发出后,到IO完成的过程中所消耗的时间。
pidstat -d 查看哪个进程的IO有问题,主要查看iodelay(io的延迟时间),一般小于1(单位ms)。
如果持续大于10,说明磁盘有瓶颈。
11.2 查看每个进程上下文切换的详细情况
命令
pidstat -w
只查看进程的上下文切换情况
pidstat -w 5 5:间隔5秒,抓取一下数据
pidstat -w 5 2 5:间隔5秒,抓取一下数据
2:移动抓取2次。
字段说明
- cswch ,表示每秒主动任务上下文切换(voluntary context switches)的次数
- nvcswch ,表示每秒被动任务上下文切换的(non voluntary context switches)次数
所谓主动上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说,
I/O、内存等系统资源不足时,就会发生主动上下文切换。
而被动上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生
的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生被动上下文切换。
pidstat -wt
查看进程及线程的上下文切换情况
注意:
pidstat -w 5 2 与
pidstat -wt 5 2 -w是只查看进程上下文切换,-wt查看进程及线程的上下文切换情况。
如上图,java是单进程多线程,查看一个java进程,这个进程的上下文切换为0,但是线程是有上下文切换数据的。
所以我们在查看上下文切换的数据时,既要查看进程的,也要查看线程的。
11.3 查看特定进程的线程统计情况
命令
pidstat -t -p 3214
或者
pidstat -p 3214 -t
[root@iz2ze2w3v37sit3vf71kuez ~]# pidstat -t -p 3214 2
Linux 3.10.0-514.26.2.el7.x86_64 (iz2ze2w3v37sit3vf71kuez) 2021年08月14日 _x86_64_ (1 CPU)
08时12分02秒 UID TGID TID %usr %system %guest %wait %CPU CPU Command
08时12分04秒 0 3214 - 7.54 92.46 0.00 0.00 100.00 0 sysbench
08时12分04秒 0 - 3214 0.00 0.00 0.00 0.00 0.00 0 |__sysbench
08时12分04秒 0 - 3215 0.00 5.03 0.00 36.68 5.03 0 |__sysbench
08时12分04秒 0 - 3216 0.50 4.02 0.00 32.66 4.52 0 |__sysbench
08时12分04秒 0 - 3217 0.50 4.52 0.00 40.70 5.03 0 |__sysbench
08时12分04秒 0 - 3218 0.00 4.52 0.00 36.18 4.52 0 |__sysbench
08时12分04秒 0 - 3219 0.00 4.52 0.00 32.16 4.52 0 |__sysbench
08时12分04秒 0 - 3220 0.50 4.52 0.00 17.59 5.03 0 |__sysbench
08时12分04秒 0 - 3221 0.50 5.03 0.00 38.69 5.53 0 |__sysbench
08时12分04秒 0 - 3222 0.50 5.03 0.00 32.16 5.53 0 |__sysbench
08时12分04秒 0 - 3223 0.00 4.52 0.00 38.19 4.52 0 |__sysbench
08时12分04秒 0 - 3224 0.50 4.52 0.00 46.23 5.03 0 |__sysbench
08时12分04秒 0 - 3225 0.50 5.03 0.00 48.24 5.53 0 |__sysbench
08时12分04秒 0 - 3226 0.50 5.03 0.00 39.20 5.53 0 |__sysbench
08时12分04秒 0 - 3227 0.50 4.52 0.00 35.18 5.03 0 |__sysbench
08时12分04秒 0 - 3228 0.00 4.52 0.00 36.68 4.52 0 |__sysbench
08时12分04秒 0 - 3229 0.00 5.03 0.00 37.69 5.03 0 |__sysbench
08时12分04秒 0 - 3230 0.50 4.52 0.00 43.72 5.03 0 |__sysbench
08时12分04秒 0 - 3231 0.50 4.52 0.00 35.18 5.03 0 |__sysbench
08时12分04秒 0 - 3232 0.50 4.52 0.00 47.74 5.03 0 |__sysbench
08时12分04秒 0 - 3233 0.50 5.03 0.00 45.73 5.53 0 |__sysbench
08时12分04秒 0 - 3234 0.50 4.52 0.00 43.22 5.03 0 |__sysbench 说明:
TGID: 主线程的表示
TID: 线程id
%usr: 进程/线程在用户空间占用cpu的百分比
%system: 进程/线程在内核空间占用cpu的百分比
%guest: 进程/线程在虚拟机占用cpu的百分比
%CPU: 进程/线程占用cpu的百分比
CPU: 处理/线程进程的cpu编号
Command: 当前进程对应的命令 备注:
以上的几项,进程的数据是所有线程的数据之和
十二、iostat
查看博客:
https://www.jianshu.com/p/5fed8be1b6e8
概述
iostat 主要用于输出磁盘IO 和 CPU的统计信息。
iostat属于sysstat软件包。可以用yum install sysstat 直接安装。
iostat 用法
用法:iostat [选项] [<时间间隔>] [<次数>]
命令参数:
-c: 显示CPU使用情况
-d: 显示磁盘使用情况
-N: 显示磁盘阵列(LVM) 信息
-n: 显示NFS 使用情况
-k: 以 KB 为单位显示
-m: 以 M 为单位显示
-t: 报告每秒向终端读取和写入的字符数和CPU的信息
-V: 显示版本信息
-x: 显示详细信息
-p:[磁盘] 显示磁盘和分区的情况
iostat 结果列表字段释义
[root@iz2ze2w3v37sit3vf71kuez ~]# iostat
Linux 3.10.0-514.26.2.el7.x86_64 (iz2ze2w3v37sit3vf71kuez) 2021年08月15日 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.76 0.00 0.61 0.02 0.00 98.61
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.40 0.84 4.40 3985637 20823164 cpu属性值说明:
%user:
CPU处在用户模式下的时间百分比。
%nice:
CPU处在带NICE值的用户模式下的时间百分比。
%system:
CPU处在系统模式下的时间百分比。
%iowait:
CPU等待输入输出完成时间的百分比。
%steal:
管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:
CPU空闲时间百分比。 备注:
如果%iowait的值过高,表示硬盘存在I/O瓶颈。
%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。
%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
disk属性值说明:
device:磁盘名称
tps:每秒钟发送到的I/O请求数.
Blk_read/s:每秒读取的block数.
Blk_wrtn/s:每秒写入的block数.
Blk_read:读入的block总数.
Blk_wrtn:写入的block总数. iostat -x 查看cpu和磁盘的详细信息
[root@iz2ze2w3v37sit3vf71kuez ~]# iostat -x
Linux 3.10.0-514.26.2.el7.x86_64 (iz2ze2w3v37sit3vf71kuez) 2021年08月15日 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.76 0.00 0.61 0.02 0.00 98.61
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.27 0.04 0.36 0.84 4.40 26.06 0.00 5.64 8.75 5.28 0.58 0.02 结果列表字段释义
avgqu-sz:
平均i/o队列长度,建议不超过1
svctm:
磁盘本身(磁盘读写)的耗时<4ms。平均每次设备的IO操作的服务时间(毫秒),即delta(use)/delta(rio+wio)
await:
操作系统每次IO的平均耗时,等待磁盘读写时间+svctm之和,单位是毫秒。
一般情况下await大于svctm,他们的差值越小,则说明队列越短。反之,差值越大,队列越长,说明系统出了问题。
%util:
磁盘繁忙程度。i/O请求占cpu的百分比,比率越大,说明越饱和。当%util达到1时,说明设备带宽已经被占满。
rrqm/s:
每秒进行merge的读操作次数。即 rmerge/s
wrqm/s:
每秒进行merge的写操作次数。即 wmerge/s
r/s:
每秒完成的读 I/O 设备次数。即 rio/s
w/s:
每秒完成的写 I/O 设备次数。即 wio/s
rkB/s:
每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s:
每秒写K字节数。是 wsect/s 的一半。
avgrq-sz:
平均每次设备I/O操作的数据大小 (扇区)。 通过rkB/s与wkB/s可以判断出,如果io很高的话,到底是读导致的还是写导致的。如果是读导致的,应该是内存不足。如果写占比大,说明某个应用程序在写。此时可以查看哪个程序在写东西,(写文件或者写日志)
磁盘分以下三类:
机械硬盘(HDD)是传统硬盘,单道寻址,比较慢。
固态磁盘,多通道寻址,比机械磁盘快。
混合硬盘(SSHD)
12.2 iostat -d 查看磁盘情况
[root@iz2ze2w3v37sit3vf71kuez ~]# iostat -d
Linux 3.10.0-514.26.2.el7.x86_64 (iz2ze2w3v37sit3vf71kuez) 2021年08月16日 _x86_64_ (1 CPU)
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
vda 0.42 0.91 4.73 4392681 22860432 结果列表显示
Device:
磁盘名称
tps:
该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。
"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。
kB_read/s:
每秒从设备(drive expressed)读取的数据量
kB_wrtn/s:
每秒向设备(drive expressed)写入的数据量;
kB_read:
读取的总数据量;
kB_wrtn:
写入的总数量数据量;这些单位都为Kilobytes。 十三、sysbench介绍
1)sysbench安1.0装
具体的安装方式,按照这个连接:
---------------------
下面的安装方式,也许会报错
需要的软件包:
automake
libtool
sysbench-1.0.zip
安装:
sysbench-1.0:
wget https://github.com/akopytov/sysbench/archive/1.0.zip -O "sysbench-1.0.zip" 下载之后的名字是1.0.zip。
解压之后为sysbench-1.0
cd sysbench-1.0 执行autogen.sh用它来生成configure这个文件
./autogen.sh 执行
./configure && make && make install 来完成sysbench的安装
automake libtool:
yum install automake libtool 2)sysbench介绍:
SysBench是一个模块化的、跨平台、多线程基准测试工具,主要用于评估测试各种不同系统参数下的数据库负载情况。它主要包括以下几种方式的测试:
- cpu性能
- 磁盘io性能
- 内存分配及传输速度
- POSIX线程性能
- 调度程序性能
- 数据库性能(OLTP基准测试)
3)通用选项说明
sysbench --help
Usage:
sysbench [options]... [testname] [command]
Commands implemented by most tests: prepare run cleanup help
General options:
--threads=N number of threads to use [1],创建测试线程的数目。默认为1.
--events=N limit for total number of events [0],请求的最大数目,0代表不限制。
--time=N limit for total execution time in seconds [10],最大执行时间,单位是s。默认是10s
--forced-shutdown=STRING number of seconds to wait after the --time limit before forcing shutdown, or 'off' to disable [off],超过max-time强制中断。默认是off。
--thread-stack-size=SIZE size of stack per thread [64K],每个线程的堆栈大小。默认是64K。
--rate=N average transactions rate. 0 for unlimited rate [0]
--report-interval=N periodically report intermediate statistics with a specified interval in seconds. 0 disables intermediate reports [0],指定每多少秒在屏幕上输出一次结果
--report-checkpoints=[LIST,...] dump full statistics and reset all counters at specified points in time. The argument is a list of comma-separated values representing the amount of time in seconds elapsed from start of test when report checkpoint(s) must be performed. Report checkpoints are off by default. []
--debug[=on|off] print more debugging info [off],是否显示更多的调试信息。默认是off。
--validate[=on|off] perform validation checks where possible [off],#在可能情况下执行验证检查。默认是off。
--help[=on|off] print help and exit [off],#帮助信息
--version[=on|off] print version and exit [off],#版本信息
--config-file=FILENAME File containing command line options
--tx-rate=N deprecated alias for --rate [0]
--max-requests=N deprecated alias for --events [0]
--max-time=N deprecated alias for --time [0]
--num-threads=N deprecated alias for --threads [1]
Pseudo-Random Numbers Generator options:
--rand-type=STRING random numbers distribution {uniform,gaussian,special,pareto} [special]
--rand-spec-iter=N number of iterations used for numbers generation [12]
--rand-spec-pct=N percentage of values to be treated as 'special' (for special distribution) [1]
--rand-spec-res=N percentage of 'special' values to use (for special distribution) [75]
--rand-seed=N seed for random number generator. When 0, the current time is used as a RNG seed. [0]
--rand-pareto-h=N parameter h for pareto distribution [0.2]
Log options:
--verbosity=N verbosity level {5 - debug, 0 - only critical messages} [3],日志级别,默认为3,5=debug,0=只包含重要信息
--percentile=N percentile to calculate in latency statistics (1-100). Use the special value of 0 to disable percentile calculations [95]
--histogram[=on|off] print latency histogram in report [off]
General database options:
--db-driver=STRING specifies database driver to use ('help' to get list of available drivers) [mysql]
--db-ps-mode=STRING prepared statements usage mode {auto, disable} [auto]
--db-debug[=on|off] print database-specific debug information [off]
Compiled-in database drivers:
mysql - MySQL driver
pgsql - PostgreSQL driver
mysql options:
--mysql-host=[LIST,...] MySQL server host [localhost]
--mysql-port=[LIST,...] MySQL server port [3306]
--mysql-socket=[LIST,...] MySQL socket
--mysql-user=STRING MySQL user [sbtest]
--mysql-password=STRING MySQL password []
--mysql-db=STRING MySQL database name [sbtest]
--mysql-ssl[=on|off] use SSL connections, if available in the client library [off]
--mysql-ssl-cipher=STRING use specific cipher for SSL connections []
--mysql-compression[=on|off] use compression, if available in the client library [off]
--mysql-debug[=on|off] trace all client library calls [off]
--mysql-ignore-errors=[LIST,...] list of errors to ignore, or "all" [1213,1020,1205]
--mysql-dry-run[=on|off] Dry run, pretend that all MySQL client API calls are successful without executing them [off]
pgsql options:
--pgsql-host=STRING PostgreSQL server host [localhost]
--pgsql-port=N PostgreSQL server port [5432]
--pgsql-user=STRING PostgreSQL user [sbtest]
--pgsql-password=STRING PostgreSQL password []
--pgsql-db=STRING PostgreSQL database name [sbtest]
Compiled-in tests:#测试项目
fileio - File I/O test
cpu - CPU performance test
memory - Memory functions speed test,#内存
threads - Threads subsystem performance test,#线程
mutex - Mutex performance test#互斥性能测试
See 'sysbench <testname> help' for a list of options for each test. 4)查看帮助文档&更多选项
-- 查看总体帮助文档
#sysbench --help -- 查测试cpu的帮助文档
#sysbench --test=cpu help
--cpu-max-prime=N 最大质数发生器数量。默认是10000 -- 查看IO测试的帮助文档
#sysbench --test=fileio help
[root@iz2ze2w3v37sit3vf71kuez ~]# sysbench --test=fileio help
WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
sysbench 1.0.17 (using system LuaJIT 2.0.4)
fileio options:
--file-num=N number of files to create [128],创建测试文件的数量。默认是128
--file-block-size=N block size to use in all IO operations [16384],测试时文件块的大小。默认是16384(16K)
--file-total-size=SIZE total size of files to create [2G],测试文件的总大小。默认是2G
--file-test-mode=STRING 文件测试模式{seqwr(顺序写), seqrewr(顺序读写), seqrd(顺序读), rndrd(随机读), rndwr(随机写), rndrw(随机读写)}
--file-io-mode=STRING 文件操作模式{sync(同步),async(异步),fastmmap(快速map映射),slowmmap(慢map映射)}。默认是sync
--file-async-backlog=N number of asynchronous operatons to queue per thread [128]
--file-extra-flags=[LIST,...] 使用额外的标志来打开文件{sync,dsync,direct} 。默认为空
--file-fsync-freq=N 执行fsync()的频率。(0 – 不使用fsync())。默认是100
--file-fsync-all[=on|off] 每执行完一次写操作就执行一次fsync。默认是off
--file-fsync-end[=on|off] 在测试结束时才执行fsync。默认是on
--file-fsync-mode=STRING 使用哪种方法进行同步{fsync, fdatasync}。默认是fsync
--file-merged-requests=N 如果可以,合并最多的IO请求数(0 – 表示不合并)。默认是0
--file-rw-ratio=N 测试时的读写比例,默认时为1.5,即可3:2。 -- 查看测试内存的帮助文档
#sysbench --test=memory help
[root@iz2ze2w3v37sit3vf71kuez ~]# sysbench --test=memory help
WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
sysbench 1.0.17 (using system LuaJIT 2.0.4)
memory options:
--memory-block-size=SIZE 测试时内存块大小。默认是1K
--memory-total-size=SIZE 传输数据的总大小。默认是100G
--memory-scope=STRING 内存访问范围{global,local}。默认是global
--memory-hugetlb=[on|off] 从HugeTLB池内存分配。默认是off
--memory-oper=STRING 内存操作类型。{read, write, none} 默认是write
--memory-access-mode=STRING存储器存取方式{seq,rnd} 默认是seq -- 查看测试线程的帮助文档
#sysbench threads help
[root@iz2ze2w3v37sit3vf71kuez ~]# sysbench threads help
sysbench 1.0.17 (using system LuaJIT 2.0.4)
threads options:
--thread-yields=N number of yields to do per request [1000],每个请求产生多少个线程。默认是1000
--thread-locks=N number of locks per thread [8],每个线程的锁的数量。默认是8 -- 查看mutex的帮助文档
#sysbench mutex help
[root@iz2ze2w3v37sit3vf71kuez ~]# sysbench mutex help
sysbench 1.0.17 (using system LuaJIT 2.0.4)
mutex options:
--mutex-num=N total size of mutex array [4096],数组互斥的总大小。默认是4096
--mutex-locks=N number of mutex locks to do per thread [50000],每个线程互斥锁的数量。默认是50000
--mutex-loops=N number of empty loops to do outside mutex lock [10000],内部互斥锁的空循环数量。默认是10000 cpu性能测试
常用参数
- –cpu-max-prime: 素数生成数量的上限
- –threads: 线程数
- –time: 运行时长,单位秒
- –events: event上限次数
结果分析
[root@iz2ze2w3v37sit3vf71kuez ~]# sysbench cpu --cpu-max-prime=20000 --threads=2 run
sysbench 1.0.17 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 2//线程数为2
Initializing random number generator from current time
Prime numbers limit: 20000//2万个素数
Initializing worker threads...
Threads started!
CPU speed:
events per second: 303.63
General statistics:
total time: 10.0040s //花费10s
total number of events: 3038 //10秒内所有线程一共完成了3038次event
Latency (ms):
min: 2.78 //最小耗时2.78ms
avg: 6.57 //平均耗时6.57ms
max: 43.05 //最大耗时43.05ms
95th percentile: 26.20 //95%在26.20ms完成
sum: 19968.27
Threads fairness:
events (avg/stddev): 1519.0000/2.00
execution time (avg/stddev): 9.9841/0.00 磁盘IO性能测试
#准备数据
sysbench --test=fileio --file-total-size=2G prepare
#运行测试
[root@zijie ~]# sysbench --test=fileio --file-total-size=2G --file-test-mode=rndrw --max-time=30 --max-requests=0 run
WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
WARNING: --max-time is deprecated, use --time instead
sysbench 1.0.18 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 1
Initializing random number generator from current time
Extra file open flags: (none)
128 files, 16MiB each
2GiB total file size
Block size 16KiB
Number of IO requests: 0
Read/Write ratio for combined random IO test: 1.50
Periodic FSYNC enabled, calling fsync() each 100 requests.
Calling fsync() at the end of test, Enabled.
Using synchronous I/O mode
Doing random r/w test
Initializing worker threads...
Threads started!
File operations:
reads/s: 612.68
writes/s: 408.44
fsyncs/s: 1307.77
Throughput:
read, MiB/s: 9.57 //读吞吐
written, MiB/s: 6.38 //写吞吐
General statistics:
total time: 30.0436s
total number of events: 69851
Latency (ms):
min: 0.00
avg: 0.43
max: 213.95
95th percentile: 1.76
sum: 29921.46
Threads fairness:
events (avg/stddev): 69851.0000/0.00
execution time (avg/stddev): 29.9215/0.00
#清理数据
sysbench --test=fileio --file-total-size=2G cleanup 内存分配及传输速度测试
参数详解:
–memory-block-size=SIZE 测试内存块的大小,默认为1K
–memory-total-size=SIZE 数据传输的总大小,默认为100G
–memory-scope=STRING 内存访问的范围,包括全局和本地范围,默认为global
–memory-hugetlb=[on|off] 是否从HugeTLB池分配内存的开关,默认为off
–memory-oper=STRING 内存操作的类型,包括read, write, none,默认为write
–memory-access-mode=STRING 内存访问模式,包括seq,rnd两种模式,默认为seq
结果分析
#顺序分配
[root@zijie ~]# sysbench --num-threads=12 --max-requests=10000 --test=memory --memory-block-size=8K --memory-total-size=1G --memory-access-mode=seq run
WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
WARNING: --num-threads is deprecated, use --threads instead
WARNING: --max-requests is deprecated, use --events instead
sysbench 1.0.18 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 12
Initializing random number generator from current time
Running memory speed test with the following options:
block size: 8KiB
total size: 1024MiB
operation: write
scope: global
Initializing worker threads...
Threads started!
Total operations: 131064 (1068428.85 per second)
1023.94 MiB transferred (8347.10 MiB/sec)
General statistics:
total time: 0.1206s
total number of events: 131064
Latency (ms):
min: 0.00
avg: 0.00
max: 0.69
95th percentile: 0.00
sum: 97.04
Threads fairness:
events (avg/stddev): 10922.0000/0.00
execution time (avg/stddev): 0.0081/0.00
#随机分配
[root@zijie ~]# sysbench --num-threads=12 --max-requests=10000 --test=memory --memory-block-size=8K --memory-total-size=1G --memory-access-mode=rnd run
WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
WARNING: --num-threads is deprecated, use --threads instead
WARNING: --max-requests is deprecated, use --events instead
sysbench 1.0.18 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 12
Initializing random number generator from current time
Running memory speed test with the following options:
block size: 8KiB
total size: 1024MiB
operation: write
scope: global
Initializing worker threads...
Threads started!
Total operations: 131064 (246216.85 per second)
1023.94 MiB transferred (1923.57 MiB/sec)
General statistics:
total time: 0.5304s
total number of events: 131064
Latency (ms):
min: 0.00
avg: 0.04
max: 355.12
95th percentile: 0.00
sum: 4756.95
Threads fairness:
events (avg/stddev): 10922.0000/0.00
execution time (avg/stddev): 0.3964/0.09 POSIX线程性能测试
常用参数
- –thread-yields=N 每个请求产生多少个线程。默认是1000
- –thread-locks=N 每个线程的锁的数量。默认是8
[root@zijie ~]# sysbench --test=threads --num-threads=64 --thread-yields=100 --thread-locks=2 run
WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
WARNING: --num-threads is deprecated, use --threads instead
sysbench 1.0.18 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 64
Initializing random number generator from current time
Initializing worker threads...
Threads started!
General statistics:
total time: 10.0213s
total number of events: 35298
Latency (ms):
min: 0.26
avg: 18.15
max: 6190.05
95th percentile: 4.33
sum: 640679.20
Threads fairness:
events (avg/stddev): 551.5312/2416.65
execution time (avg/stddev): 10.0106/0.01 调度程序性能
常用参数
- –mutex-num=N 数组互斥的总大小。默认是4096
- –mutex-locks=N 每个线程互斥锁的数量。默认是50000
- –mutex-loops=N 内部互斥锁的空循环数量。默认是10000
结果分析
[root@zijie ~]# sysbench --num-threads=2 --test=mutex --mutex-num=1024 --mutex-locks=10000 --mutex-loops=10000 run
WARNING: the --test option is deprecated. You can pass a script name or path on the command line without any options.
WARNING: --num-threads is deprecated, use --threads instead
sysbench 1.0.18 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
General statistics:
total time: 0.0729s
total number of events: 2
Latency (ms):
min: 57.09
avg: 60.43
max: 63.77
95th percentile: 63.32
sum: 120.86
Threads fairness:
events (avg/stddev): 1.0000/0.00
execution time (avg/stddev): 0.0604/0.00 十四、stress工具介绍
Linux压力测试工具Stress
安装
yum install stress 十五、mapstat命令介绍
十六、案例分析-上下文切换
演示服务器 centos 7
1)查看正常情况下的上下文切换情况
vmstat 5
每5秒更新一下数据
2)模拟多线程切换
创建20个线程,持续300秒
#sysbench threads --threads=20 --time=300 run
红色框起来的部分,那时我们开始加压。in 和 cs 明显升高
vmstat 5 [root@iz2ze2w3v37sit3vf71kuez ~]# sysbench threads --threads=20 --time=300 run
sysbench 1.0.17 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 20
Initializing random number generator from current time
Initializing worker threads...
Threads started!
General statistics:
total time: 300.0129s
total number of events: 274087
Latency (ms):
min: 0.85
avg: 21.89
max: 391.57
95th percentile: 61.08
sum: 5999952.14
Threads fairness:
events (avg/stddev): 13704.3500/90.91
execution time (avg/stddev): 299.9976/0.00 使用pidstat查看线程的上下文切换情况
[root@iz2ze2w3v37sit3vf71kuez ~]# pidstat 5
Linux 3.10.0-514.26.2.el7.x86_64 (iz2ze2w3v37sit3vf71kuez) 2021年08月16日 _x86_64_ (1 CPU)
18时00分42秒 UID PID %usr %system %guest %wait %CPU CPU Command
18时00分47秒 0 20566 7.58 91.62 0.00 0.00 99.20 0 sysbench
18时00分47秒 0 31845 0.00 0.20 0.00 0.00 0.20 0 aliyun-service pidstat -w
查看进程的上下文切换情况
分析:
1,vmstat命令下,发现cs列的上下文切换从1227已经涨到了140多万
R列:就绪队列长度已经到了9,远远超过了cpu的个数1,所以会产生大量的cpu竞争
us和sy列:cpu使用率加起来已经到100%其中系统 CPU 使用率,也就是 sy 列高达 91%,说明 CPU 主要是被内核占用了
in 列:中断次数也上升到了 1412左右,说明中断处理也是个潜在的问题
综合这几个指标,可以知道,系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高
2,从 pidstat 的输出你可以发现,CPU 使用率的升高果然是 sysbench 导致的,它的 CPU使用率已经达到了 99%。但上下文切换则是来自其他进程,包括主动上下文切换最高的rcu_sched
3,**使用-wt 参数表示输出线程的上下文切换指标 **
虽然 sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。看来,上下文切换罪魁祸首,还是过多的sysbench 线程。
pidstat -wt
重点:
在日常工作中,使用pidstat 查看上下文切换的时候,建议使用pidstat -w 和pidstat -wt各查看一下。
因为如果使用-w,只是查看进程的数据,当线程造成大量上下文切换时,是不会显示线程的数据。所以需要单独看一下线程的数据
Linux strace命令详解
简介
strace常用来跟踪进程执行时的系统调用和所接收的信号。
在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通 过系统调用访问硬件设备。
strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
输出参数含义
strace cat /dev/null
[root@iz2ze2w3v37sit3vf71kuez opt]# strace cat /dev/null
execve("/usr/bin/cat", ["cat", "/dev/null"], [/* 35 vars */]) = 0
brk(0) = 0x1ea6000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f10ecdbe000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=29072, ...}) = 0
mmap(NULL, 29072, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f10ecdb6000
close(3) = 0
open("/lib64/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0@\34\2\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=2118128, ...}) = 0
mmap(NULL, 3932672, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f10ec7de000
mprotect(0x7f10ec995000, 2093056, PROT_NONE) = 0
mmap(0x7f10ecb94000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1b6000) = 0x7f10ecb94000
mmap(0x7f10ecb9a000, 16896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f10ecb9a000
close(3) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f10ecdb5000
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f10ecdb3000
arch_prctl(ARCH_SET_FS, 0x7f10ecdb3740) = 0
mprotect(0x7f10ecb94000, 16384, PROT_READ) = 0
mprotect(0x60b000, 4096, PROT_READ) = 0
mprotect(0x7f10ecdbf000, 4096, PROT_READ) = 0
munmap(0x7f10ecdb6000, 29072) = 0
brk(0) = 0x1ea6000
brk(0x1ec7000) = 0x1ec7000
brk(0) = 0x1ec7000
open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=106070960, ...}) = 0
mmap(NULL, 106070960, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f10e62b5000
close(3) = 0
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 0), ...}) = 0
open("/dev/null", O_RDONLY) = 3
fstat(3, {st_mode=S_IFCHR|0666, st_rdev=makedev(1, 3), ...}) = 0
fadvise64(3, 0, 0, POSIX_FADV_SEQUENTIAL) = 0
read(3, "", 65536) = 0
close(3) = 0
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++ 每一行都是一条系统调用,等号左边是系统调用的函数名及其参数,右边是该调用的返回值。
strace 显示这些调用的参数并返回符号形式的值。strace 从内核接收信息,而且不需要以任何特殊的方式来构建内核。
strace参数
-c 统计每一系统调用的所执行的时间,次数和出错的次数等.
-d 输出strace关于标准错误的调试信息.
-f 跟踪由fork调用所产生的子进程.
-ff 如果提供-o filename,则所有进程的跟踪结果输出到相应的filename.pid中,pid是各进程的进程号.
-F 尝试跟踪vfork调用.在-f时,vfork不被跟踪.
-h 输出简要的帮助信息.
-i 输出系统调用的入口指针.
-q 禁止输出关于脱离的消息.
-r 打印出相对时间关于,,每一个系统调用.
-t 在输出中的每一行前加上时间信息.
-tt 在输出中的每一行前加上时间信息,微秒级.
-ttt 微秒级输出,以秒了表示时间.
-T 显示每一调用所耗的时间.
-v 输出所有的系统调用.一些调用关于环境变量,状态,输入输出等调用由于使用频繁,默认不输出.
-V 输出strace的版本信息.
-x 以十六进制形式输出非标准字符串
-xx 所有字符串以十六进制形式输出.
-a column
设置返回值的输出位置.默认 为40.
-e expr
指定一个表达式,用来控制如何跟踪.格式如下:
[qualifier=][!]value1[,value2]...
qualifier只能是 trace,abbrev,verbose,raw,signal,read,write其中之一.value是用来限定的符号或数字.默认的 qualifier是 trace.感叹号是否定符号.例如:
-eopen等价于 -e trace=open,表示只跟踪open调用.而-etrace!=open表示跟踪除了open以外的其他调用.有两个特殊的符号 all 和 none.
注意有些shell使用!来执行历史记录里的命令,所以要使用\\.
-e trace=set
只跟踪指定的系统 调用.例如:-e trace=open,close,rean,write表示只跟踪这四个系统调用.默认的为set=all.
-e trace=file
只跟踪有关文件操作的系统调用.
-e trace=process
只跟踪有关进程控制的系统调用.
-e trace=network
跟踪与网络有关的所有系统调用.
-e strace=signal
跟踪所有与系统信号有关的 系统调用
-e trace=ipc
跟踪所有与进程通讯有关的系统调用
-e abbrev=set
设定 strace输出的系统调用的结果集.-v 等与 abbrev=none.默认为abbrev=all.
-e raw=set
将指 定的系统调用的参数以十六进制显示.
-e signal=set
指定跟踪的系统信号.默认为all.如 signal=!SIGIO(或者signal=!io),表示不跟踪SIGIO信号.
-e read=set
输出从指定文件中读出 的数据.例如:
-e read=3,5
-e write=set
输出写入到指定文件中的数据.
-o filename
将strace的输出写入文件filename
-p pid
跟踪指定的进程pid.
-s strsize
指定输出的字符串的最大长度.默认为32.文件名一直全部输出.
-u username
以username 的UID和GID执行被跟踪的命令 命令实例
通用的完整用法:
strace -o output.txt -T -tt -e trace=all -p 28979
上面的含义是 跟踪28979进程的所有系统调用(-e trace=all),并统计系统调用的花费时间,以及开始时间(并以可视化的时分秒格式显示),最后将记录结果存在output.txt文件里面。
strace案例
用strace调试程序
在理想世界里,每当一个程序不能正常执行一个功能时,它就会给出一个有用的错误提示,告诉你在足够的改正错误的线索。但遗憾的是,我们不是生活在理想世界 里,有时候一个程序出现了问题,你无法找到原因。
这就是调试程序出现的原因。
strace是一个必不可少的 调试工具,strace用来监视系统调用。
你不仅可以调试一个新开始的程序,也可以调试一个已经在运行的程序(把strace绑定到一个已有的PID上 面)。
这里具体的案例分析,可以查看原博客的案例分析:Linux strace命令详解_Linux教程_Linux公社-Linux系统门户网站
也可以看以下案例分析-场景六。
lsof
参考链接:
https://www.jianshu.com/p/a3aa6b01b2e1
lsof(list open files)是一个查看进程打开的文件的工具。
在 linux 系统中,一切皆文件。通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。所以 lsof 命令不仅可以查看进程打开的文件、目录,还可以查看进程监听的端口等 socket 相关的信息。本文将介绍 lsof 命令的基本用法,本文中 demo 的演示环境为 centos 7。
常用选项
-a 指示其它选项之间为与的关系
-c <进程名> 输出指定进程所打开的文件
-d <文件描述符> 列出占用该文件号的进程
+d <目录> 输出目录及目录下被打开的文件和目录(不递归)
+D <目录> 递归输出及目录下被打开的文件和目录
-i <条件> 输出符合条件与网络相关的文件
-n 不解析主机名
-p <进程号> 输出指定 PID 的进程所打开的文件
-P 不解析端口号
-t 只输出 PID
-u 输出指定用户打开的文件
-U 输出打开的 UNIX domain socket 文件
-h 显示帮助信息
-v 显示版本信息 查看用户信息
可以获取各种用户的信息,以及它们在系统上正干着的事情,包括它们的网络活动、对文件的操作等。
使用-u显示指定用户打开了什么
systemd-u 350 root txt REG 253,1 361376 661440 /usr/lib/systemd/systemd-udevd
systemd-u 350 root mem REG 253,1 62184 657587 /usr/lib64/libnss_files-2.17.so
systemd-u 350 root mem REG 253,1 7259752 1179976 /etc/udev/hwdb.bin
systemd-u 350 root mem REG 253,1 19888 657916 /usr/lib64/libattr.so.1.1.0
systemd-u 350 root DEL REG 253,1 657746 /usr/lib64/libz.so.1.2.7;60d1c6ab
systemd-u 350 root mem REG 253,1 157424 657758 /usr/lib64/liblzma.so.5.2.2
systemd-u 350 root mem REG 253,1 20040 657784 /usr/lib64/libuuid.so.1.3.0 命令和进程
可以查看指定程序或进程由什么启动,这通常会很有用,而你可以使用lsof通过名称或进程ID过滤来完成这个任务。下面列出了一些选项:
使用-c查看指定的命令正在使用的文件和网络连接
1. # lsof -c syslog-ng
3. COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
4. syslog-ng 7547 root cwd DIR 3,3 4096 2 /
5. syslog-ng 7547 root rtd DIR 3,3 4096 2 /
6. syslog-ng 7547 root txt REG 3,3 113524 1064970 /usr/sbin/syslog-ng
7. -- snipped --
使用-p查看指定进程ID已打开的内容
1. # lsof -p 10075
3. -- snipped --
4. sshd 10068 root mem REG 3,3 34808 850407 /lib/libnss_files-2.4.so
5. sshd 10068 root mem REG 3,3 34924 850409 /lib/libnss_nis-2.4.so
6. sshd 10068 root mem REG 3,3 26596 850405 /lib/libnss_compat-2.4.so
7. sshd 10068 root mem REG 3,3 200152 509940 /usr/lib/libssl.so.0.9.7
8. sshd 10068 root mem REG 3,3 46216 510014 /usr/lib/liblber-2.3
9. sshd 10068 root mem REG 3,3 59868 850413 /lib/libresolv-2.4.so
10. sshd 10068 root mem REG 3,3 1197180 850396 /lib/libc-2.4.so
11. sshd 10068 root mem REG 3,3 22168 850398 /lib/libcrypt-2.4.so
12. sshd 10068 root mem REG 3,3 72784 850404 /lib/libnsl-2.4.so
13. sshd 10068 root mem REG 3,3 70632 850417 /lib/libz.so.1.2.3
14. sshd 10068 root mem REG 3,3 9992 850416 /lib/libutil-2.4.so
15. -- snipped -- 案例分析-平均负载
准备
预先安装 stress 和 sysstat 包
工具:iostat、mpstat、pidstat
stress 是一个 Linux 系统压力测试工具,
sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能。这个包的两个命令 mpstat 和 pidstat。
mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标
场景一:CPU密集型进程
第一个终端运行 stress 命令,模拟一个 CPU 使用率 100% 的场景
如果linux服务器,只有一核cpu,执行:
stress --cpu 1 --timeout 600 [root@iz2ze2w3v37sit3vf71kuez ~]# stress --cpu 1 --timeout 600
stress: info: [20859] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd 如果linux服务器,两核cpu,执行:
stress --cpu 2 --timeout 600 在第二个终端运行 top 查看平均负载的变化情况
负载达到了2.5,cpu利用率达到了100%
在第三个终端运行 mpstat 查看 CPU 使用率的变化情况:
mpstat -P ALL 5 -P ALL 表示监控所有cpu
5 表示间隔5秒输出一次数据
我的机器只有一个CPU。下图是一个多cpu截图(来源与网络)
场景二:
stress -i 1 --timeout 600 负载上升,sy 消耗很大。si中断是0,wa值比较大,则是很有可能是io导致的。
场景三
stress -c 8 --timeout 600