1.
Suppose you have trained an SVM classifier with a Gaussian kernel, and it learned the following decision boundary on the training set:
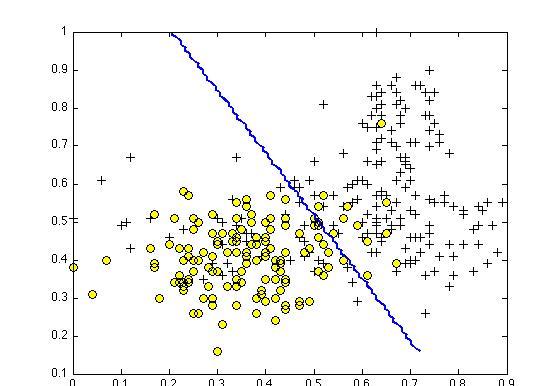
You suspect that the SVM is underfitting your dataset. Should you try increasing or decreasing C ? Increasing or decreasing σ2 ?
答案A
It would be reasonable to try increasing C . It would also be reasonable to try decreasing σ2 .
It would be reasonable to try decreasing C . It would also be reasonable to try increasing σ2 .
It would be reasonable to try increasing C . It would also be reasonable to try increasing σ2 .
It would be reasonable to try decreasing C . It would also be reasonable to try decreasing σ2 .
1
point 2.
The formula for the Gaussian kernel is given by similarity(x,l(1))=exp(−||x−l(1)||22σ2) .
The figure below shows a plot of f1=similarity(x,l(1)) when σ2=1 .

Which of the following is a plot of f1 when σ2=0.25 ?
答案D
Figure 4.
Figure 2.
Figure 3.
1
point 3.
The SVM solves
minθ C∑mi=1y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))+∑nj=1θ2j
where the functions cost0(z) and cost1(z) look like this:
The first term in the objective is:
C∑mi=1y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i)).
This first term will be zero if two of the following four conditions hold true. Which are the two conditions that would guarantee that this term equals zero?
答案CD
For every example with y(i)=0 , we have that θTx(i)≤0 .
For every example with y(i)=1 , we have that θTx(i)≥0 .
For every example with y(i)=0 , we have that θTx(i)≤−1 .
For every example with y(i)=1 , we have that θTx(i)≥1 .
1
point 4.
Suppose you have a dataset with n = 10 features and m = 5000 examples.
After training your logistic regression classifier with gradient descent, you find that it has underfit the training set and does not achieve the desired performance on the training or cross validation sets.
Which of the following might be promising steps to take? Check all that apply.
答案AC
Try using a neural network with a large number of hidden units.
Use a different optimization method since using gradient descent to train logistic regression might result in a local minimum.
Create / add new polynomial features.
Reduce the number of examples in the training set.
1
point 5.
Which of the following statements are true? Check all that apply.
答案CD
Suppose you are using SVMs to do multi-class classification and
would like to use the one-vs-all approach. If you have K different
classes, you will train K - 1 different SVMs.
If the data are linearly separable, an SVM using a linear kernel will
return the same parameters θ regardless of the chosen value of
C (i.e., the resulting value of θ does not depend on C ).
It is important to perform feature normalization before using the Gaussian kernel.
The maximum value of the Gaussian kernel (i.e., sim(x,l(1)) ) is 1.