平时写过多进程多线程程序,比如使用linux的系统调用fork创建子进程和glibc中的nptl包里的pthread_create创建线程,甚至在java里使用Thread类创建线程等,虽然使用问题不大,但需要知道底层原理。这次在自己写操作系统的时候,看了一遍linux内核的进程创建过程。算是有了比较深入的理解。
进程概念:进程是对正在运行程序的一个抽象。一个进程就是一个正在执行程序的实例,包括程序计数器、寄存器、和变量的当前值,文件描述符等。从概念上说,每个进程拥有它自己的虚拟cpu。
线程概念:线程,有时被称为轻量进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程ID,当前指令指针,寄存器集合,堆栈等,线程创建速度快,因为线程和所属进程共享资源,避免了资源复制和重新创建的开销。在linux下线程属于轻量级进程,拥有完全一样的数据结构,是系统调度的最小单位。并且线程和cpu是1:1模型,也就是说当前cpu在一个时间片周期内只运行一个线程,这样可以充分利用硬件。
看下进程和线程结构体struct task_struct,由于此结构体成员很多只分析比较重要的成员。
/*
* 进程结构体,同时也是轻量级进程(线程)结构体,基本调度单位
* 由于结构体成员很多,只看关键成员
*/
struct task_struct {
/*进程状态 -1 不能运行错误状态, 0 可以运行,在待运行队列, >0表示进程停止,比如在等待队列 */
volatile long state;
/*内核栈信息*/
struct thread_info *thread_info;
unsigned long flags; /* 进程标志 */
unsigned long ptrace; //追踪标志
#ifdef CONFIG_SMP
#ifdef __ARCH_WANT_UNLOCKED_CTXSW
int oncpu; //在哪个cpu上运行
#endif
#endif
//smp架构下负载权重
int load_weight; /* for niceness load balancing purposes */
//优先级,静态优先级,普通优先级
int prio, static_prio, normal_prio;
//运行队列
struct list_head run_list;
//优先级队列指针,在进程调度算法中用到
struct prio_array *array;
//IO优先级
unsigned short ioprio;
unsigned int btrace_seq;
//进程平均休眠时间
unsigned long sleep_avg;
unsigned long long timestamp, last_ran;
unsigned long long sched_time; /* sched_clock time spent running */
enum sleep_type sleep_type;
unsigned long policy;
cpumask_t cpus_allowed;
//进程的时间片
unsigned int time_slice, first_time_slice;
struct list_head tasks;
/*
* ptrace_list/ptrace_children forms the list of my children
* that were stolen by a ptracer.
*/
struct list_head ptrace_children;
struct list_head ptrace_list;
//内存描述符结构,如果为内核线程mm为null,只用active_mm,并且active_mm使用上个进程的mm
struct mm_struct *mm, *active_mm;
/* task state */
//二进制文件格式结构
struct linux_binfmt *binfmt;
//进程推出状态
long exit_state;
//退出码,退出信号
int exit_code, exit_signal;
/* ??? */
unsigned long personality;
//当前进程是否执行了二进制文件
unsigned did_exec:1;
//进程的pid,每个task_struct结构体唯一
pid_t pid;
//线程组id,如果当前task_struct是一个线程,则该值是所属进程的id
//getpid也是返回的此值
pid_t tgid;
/*
*进程的真实父进程,如果进程P的父进程不存在(比如退出),就指向1号init进程(由内核创建)
*/
struct task_struct *real_parent; /* real parent process (when being debugged) */
/*
*当前进程的父进程
*/
struct task_struct *parent; /* parent process */
/*
*当前进程的子进程列表
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* 当前进程的兄弟进程列表*/
struct task_struct *group_leader; /* 线程组领导,如果当前进程是线程,就是创建该线程的进程 */
/* pid 哈希表,通过pid查找进程结构. */
struct pid_link pids[PIDTYPE_MAX];
/*线程组链表*/
struct list_head thread_group;
struct completion *vfork_done; /* vfork()使用的结构 */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
unsigned long rt_priority; //实时进程优先级
/*执行命令,比如./a.out*/
char comm[TASK_COMM_LEN]; /* executable name excluding path
- access with [gs]et_task_comm (which lock
it with task_lock())
- initialized normally by flush_old_exec */
/* cpu寄存器的状态 */
struct thread_struct thread;
/* f文件系统信息 */
struct fs_struct *fs;
/* 打开的文件描述符信息 */
struct files_struct *files;
/* 命名空间信息 */
struct namespace *namespace;
/* 信号处理 */
struct signal_struct *signal;
struct sighand_struct *sighand;
}; 复制
其中一部分是进程资源相关的,比如mm, active_mm, fs,files,namespace,signal等成员,一部分和调度相关的比如sleep_avg,time_slice,prio,static_prio等。再看其中三个比较重要的结构:
struct thread_info 字面意思是线程信息,其实主要是内核栈的信息,每个进程都有自己的内核栈和用户栈,还可以设置中断栈,其中和进程上下文切换相关的主要是内核栈。
struct thread_info {
struct task_struct *task; /* 内核栈所对应的进程指针*/
struct exec_domain *exec_domain; /* 执行域,比如64位系统执行32位程序 */
unsigned long flags; /* 标志位 */
unsigned long status; /* 线程同步标志 */
__u32 cpu; /* 当前cpu */
int preempt_count; /* 内核抢占标记,0表示可以抢占,大于0表示不能抢占,小于0错误*/
//线程地址空间
mm_segment_t addr_limit; /* thread address space:
0-0xBFFFFFFF for user-thead
0-0xFFFFFFFF for kernel-thread
*/
void *sysenter_return;
struct restart_block restart_block;
//前一个堆栈的esp,比如中断嵌套时
unsigned long previous_esp; /* ESP of the previous stack in case
of nested (IRQ) stacks
*/
//0数组,表示内核栈的起始地址
__u8 supervisor_stack[0];
}; 复制
此结构实现的很精妙,栈底表示thread_info结构,但也有危险,内核栈大小默认8KB,如果嵌套过多,可能会导致爆栈,所以内核态编程禁止使用递归。此结构如下图:
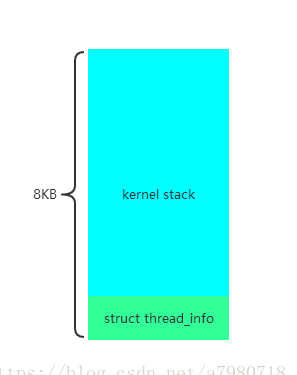
struct thread_info的起始地址要8KB对齐,在进入内核态后,会将用户态堆栈切换为内核态堆栈 ,这样我们就可以根据当前栈指针获取struct thread_info结构体,进而获取当前进程的task_struct指针,也就是有名的current宏,下面看如何获取的
/* 寄存器变量,表示当前栈指针esp寄存器*/
register unsigned long current_stack_pointer asm("esp") __attribute_used__;
/* 获取thread_info结构体指针*/
static inline struct thread_info *current_thread_info(void)
{
/*
*THREAD_SIZE = 8KB, thread_info的起始地址要8KB对齐,这样就变成esp & 0xFFFFE000
*比如thread_info起始地址是0x4000, 栈顶为0x6000,当前esp为0x5110,则0x5110 & 0xFFFFE000 = 0x4000
*/
return (struct thread_info *)(current_stack_pointer & ~(THREAD_SIZE - 1));
}
//获取current指针
static __always_inline struct task_struct * get_current(void)
{
return current_thread_info()->task;
}
#define current get_current() 复制
第二个重要的结构是struct thread_struct结构体表示cpu寄存器相关信息,此结构体在进程上下文切换时有用,被挂起进程的eip esp cs等寄存器值会存在此结构,表示如下:
/*thread_struct特定cpu寄存器信息,在进程上下文切换时有用*/
struct thread_struct {
/* TLS描述符 */
struct desc_struct tls_array[GDT_ENTRY_TLS_ENTRIES];
unsigned long esp0;
unsigned long sysenter_cs;//内核代码段寄存器值
unsigned long eip; //内核eip寄存器值
unsigned long esp; //内核栈指针
unsigned long fs; //fs寄存器值
unsigned long gs; //gs寄存器值
/* Hardware debugging registers */ //debug寄存器信息
unsigned long debugreg[8]; /* %%db0-7 debug registers */
/* fault info */
unsigned long cr2, trap_no, error_code; //cr2缺页地址,trap_no异常号,error_code错误码
/* floating point info */
union i387_union i387; //浮点寄存器信息
/* virtual 86 mode info */
struct vm86_struct __user * vm86_info;
unsigned long screen_bitmap;
unsigned long v86flags, v86mask, saved_esp0;
unsigned int saved_fs, saved_gs;
/* IO permissions */
unsigned long *io_bitmap_ptr;//IO权限指针
unsigned long iopl;
/* max allowed port in the bitmap, in bytes: */
unsigned long io_bitmap_max; //IO位图
}; 复制
第三个是struct mm_struct,表示内存描述符,此描述符主要描述了进程的虚拟地址空间信息。结构如下:
struct mm_struct {
//vma链表的起始结构
struct vm_area_struct * mmap; /* list of VMAs */
struct rb_root mm_rb; //红黑树根节点主要组织vma
struct vm_area_struct * mmap_cache; /* last find_vma result,上次调用find vma的结果缓存 */
//获取未映射区域地址
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
//mmap区基地址
unsigned long mmap_base; /* base of mmap area */
//用户进程虚拟空间大小
unsigned long task_size; /* size of task vm space */
//空洞空间大小
unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
//内核从这个地址搜索进程地址空间中的空闲区
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
//页目录指针
pgd_t * pgd;
//使用此mm的用户数
atomic_t mm_users; /* How many users with user space? */
//mm的引用次数
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
//属于此mm的vma数量
int map_count; /* number of VMAs */
//读写信号量
struct rw_semaphore mmap_sem;
//页表锁
spinlock_t page_table_lock; /* Protects page tables and some counters */
//mm结构链表
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
/* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
mm_counter_t _file_rss; //分配给文件的页框数
mm_counter_t _anon_rss; //分配给匿名页的页框数
//进程所拥有的最大页框数
unsigned long hiwater_rss; /* High-watermark of RSS usage */
//进程所拥有的最大页数
unsigned long hiwater_vm; /* High-water virtual memory usage */
//分别表示进程地址空间页数,锁住的页数,共享文件内存映射的页数,可执行内存映射的页数
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
//分别表示栈空间页框数,保留页数,默认标志位,页表项数量
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
//分别表示进程代码段起始地址,结束地址,数据段起始地址,结束地址
unsigned long start_code, end_code, start_data, end_data;
//分别表示进程堆起始地址,结束地址,栈起始地址
unsigned long start_brk, brk, start_stack;
//分别表示进程参数起始地址,结束地址,环境变量起始地址,结束地址
unsigned long arg_start, arg_end, env_start, env_end;
//开始执行程序时使用
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
unsigned dumpable:2;
cpumask_t cpu_vm_mask;
/* 特定结构的mm上下文 */
mm_context_t context;
/* 进程将在这个时间有资格获得交换标记 */
unsigned long swap_token_time;
//如果最近发生了缺页中断,则设置该标志
char recent_pagein;
/* 正在把进程地址空间的内容卸载到转储文件中的轻量级进程数量 */
int core_waiters;
//转储原语
struct completion *core_startup_done, core_done;
/* 异步io锁 */
rwlock_t ioctx_list_lock;
//异步io上下文链表
struct kioctx *ioctx_list;
}; 复制
重要的结构体介绍完了,可以看创建流程了,进程线程的创建都要调用同一个函数就是do_fork, 系统调用sys_fork,sys_clone,和内核线程的创建kernel_thread函数最终都要调用do_fork。
/*
* fork进程的主要函数,sys_fork,sys_clone等用户系统调用和kernel_thread创建内核线程函数都会调用
* 此函数。也就是说不管是进程还是线程创建最终都会进入此函数。在这不管是线程还是进程统一用进程
* 描述。
* clone_flags: fork进程标志
* stack_start: 新进程的栈起始地址
* regs:进行调用前保存的各个寄存器的值,比如从用户态进入内核态保存在栈中的各个寄存器的值
* stack_size:新进程的栈大小
* parent_tidptr:当创建线程时,表示父进程的用户态变量地址
* child_tidptr:当创建线程时,表示新线程的用户态变量地址
*/
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0; //内核追踪标志
struct pid *pid = alloc_pid(); //分配一个pid结构,struct pid的nr成员表示进程号
long nr;
if (!pid)
return -EAGAIN;
nr = pid->nr; //进程号
if (unlikely(current->ptrace)) {
trace = fork_traceflag (clone_flags);
if (trace)
clone_flags |= CLONE_PTRACE;
}
//进程复制核心函数
p = copy_process(clone_flags, stack_start, regs, stack_size, parent_tidptr, child_tidptr, nr);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) { //如果进程复制没有出错
struct completion vfork;
if (clone_flags & CLONE_VFORK) {//vfork标志
p->vfork_done = &vfork;
init_completion(&vfork);
}
if ((p->ptrace & PT_PTRACED) || (clone_flags & CLONE_STOPPED)) {
/*
* We'll start up with an immediate SIGSTOP.
*/
sigaddset(&p->pending.signal, SIGSTOP);
set_tsk_thread_flag(p, TIF_SIGPENDING);
}
//如果没有CLONE_STOPPED标志,则调用wake_up_new_task将新进程加入可运行队列
if (!(clone_flags & CLONE_STOPPED))
wake_up_new_task(p, clone_flags);
else
p->state = TASK_STOPPED; //否则将新进程设置为停止
if (unlikely (trace)) {
current->ptrace_message = nr;
ptrace_notify ((trace << 8) | SIGTRAP);
}
if (clone_flags & CLONE_VFORK) { //如果是VFORK标志则需要先等待新进程执行完
wait_for_completion(&vfork);
if (unlikely (current->ptrace & PT_TRACE_VFORK_DONE)) {
current->ptrace_message = nr;
ptrace_notify ((PTRACE_EVENT_VFORK_DONE << 8) | SIGTRAP);
}
}
} else {
free_pid(pid);
nr = PTR_ERR(p);
}
return nr; //返回新进程的pid
} 复制
其中最主要的copy过程全部交给了copy_process,此函数复制了所有进程资源信息,下面看此函数
/*
* clone_flags:fork标志
* stack_start:新进程栈起始地址
* regs:调用时保存的各个寄存器值
* stack_size: 新进程栈大小
* parent_tidptr:创建线程时,父进程的用户态变量指针
* child_tidptr:创建线程时,新线程的用户态变量指针
* pid: 要创建的新进程分配的pid
*/
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
int pid)
{
int retval;
struct task_struct *p = NULL;
/*标志检查,表示不能同时设置这两个标志,CLONE_NEWNS表示要创建一个自己的命名空间,也就是
*即自己挂载的文件系统,而CLONE_FS表示和父进程共享目录,所以矛盾
*/
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
/*
* CLONE_THREAD表示将子进程插入到父进程同一线程组中,并且必须共享父进程的信号描述符,
* 所以和!(clone_flags & CLONE_SIGHAND)矛盾
*/
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* 如果共享信号描述符,则必须共享内存空间,所以和!(clone_flags & CLONE_VM)矛盾
*
*/
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
//安全相关检查
retval = security_task_create(clone_flags);
if (retval)
goto fork_out;
retval = -ENOMEM;
//创建新进程struct task_struct指针
p = dup_task_struct(current);
if (!p)
goto fork_out;
#ifdef CONFIG_TRACE_IRQFLAGS
DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled);
DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled);
#endif
retval = -EAGAIN;
//判断当前用户进程数是否超过阈值
if (atomic_read(&p->user->processes) >=
p->signal->rlim[RLIMIT_NPROC].rlim_cur) {
if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) &&
p->user != &root_user)
goto bad_fork_free;
}
//新进程用户引用次数加一
atomic_inc(&p->user->__count);
//新进程用户进程数加一
atomic_inc(&p->user->processes);
get_group_info(p->group_info);
/*
* If multiple threads are within copy_process(), then this check
* triggers too late. This doesn't hurt, the check is only there
* to stop root fork bombs.
*/
/*
*判断系统中线程数是否超过最大线程数,此变量max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE);
*在fork_init函数初始化,比如4GB的内存则最大线程数为65536
*/
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
if (p->binfmt && !try_module_get(p->binfmt->module))
goto bad_fork_cleanup_put_domain;
//加载可执行文件标志置为0
p->did_exec = 0;
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
copy_flags(clone_flags, p); //复制进程标志flags
p->pid = pid; //给新进程赋值进程号pid
retval = -EFAULT;
//如果是设置了CLONE_PARENT_SETTID标志,则将子进程的pid复制给父进程的parent_tidptr
if (clone_flags & CLONE_PARENT_SETTID)
if (put_user(p->pid, parent_tidptr))
goto bad_fork_cleanup_delays_binfmt;
//初始化新进程的子进程链表
INIT_LIST_HEAD(&p->children);
//初始化新进程的兄弟进程链表
INIT_LIST_HEAD(&p->sibling);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
clear_tsk_thread_flag(p, TIF_SIGPENDING);
init_sigpending(&p->pending);
//以下都是初始化一些成员变量
p->utime = cputime_zero;
p->stime = cputime_zero;
p->sched_time = 0;
p->rchar = 0; /* I/O counter: bytes read */
p->wchar = 0; /* I/O counter: bytes written */
p->syscr = 0; /* I/O counter: read syscalls */
p->syscw = 0; /* I/O counter: write syscalls */
acct_clear_integrals(p);
...........
//将新进程pid复制给新进程tgid
p->tgid = p->pid;
//如果设置CLONE_THREAD标志,说明创建的是线程,则将父进程的tgid复制给新进程的tgid,说明获取线程
//所属的进程id需要获取tgid成员
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid;
if ((retval = security_task_alloc(p))) //安全相关检查
goto bad_fork_cleanup_policy;
if ((retval = audit_alloc(p))) //审计检查
goto bad_fork_cleanup_security;
/* 以下开始复制所有资源*/
if ((retval = copy_semundo(clone_flags, p)))//i386下为空
goto bad_fork_cleanup_audit;
if ((retval = copy_files(clone_flags, p))) //复制打开的文件描述符
goto bad_fork_cleanup_semundo;
if ((retval = copy_fs(clone_flags, p))) //复制文件路径
goto bad_fork_cleanup_files;
if ((retval = copy_sighand(clone_flags, p))) //复制信号处理
goto bad_fork_cleanup_fs;
if ((retval = copy_signal(clone_flags, p))) //复制信号
goto bad_fork_cleanup_sighand;
if ((retval = copy_mm(clone_flags, p))) //复制内存描述符
goto bad_fork_cleanup_signal;
if ((retval = copy_keys(clone_flags, p))) //i386下为空
goto bad_fork_cleanup_mm;
if ((retval = copy_namespace(clone_flags, p))) //复制命名空间
goto bad_fork_cleanup_keys;
//复制进程上下文相关信息
retval = copy_thread(0, clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_namespace;
//子进程在用户态下的指针,CLONE_CHILD_SETTID设置了
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
/*
* Clear TID on mm_release()?
*/
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr: NULL;
p->robust_list = NULL;
#ifdef CONFIG_COMPAT
p->compat_robust_list = NULL;
#endif
INIT_LIST_HEAD(&p->pi_state_list);
p->pi_state_cache = NULL;
/*
* sigaltstack should be cleared when sharing the same VM
*/
if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM)
p->sas_ss_sp = p->sas_ss_size = 0;
/*
* Syscall tracing should be turned off in the child regardless
* of CLONE_PTRACE.
*/
clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE);
#ifdef TIF_SYSCALL_EMU
clear_tsk_thread_flag(p, TIF_SYSCALL_EMU);
#endif
/* Our parent execution domain becomes current domain
These must match for thread signalling to apply */
p->parent_exec_id = p->self_exec_id;
/* ok, now we should be set up.. */
p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL);
p->pdeath_signal = 0;
p->exit_state = 0;
/*
* Ok, make it visible to the rest of the system.
* We dont wake it up yet.
*/
p->group_leader = p; //将新进程的线程组领导进程设置为自己
INIT_LIST_HEAD(&p->thread_group); //初始化线程组链表
INIT_LIST_HEAD(&p->ptrace_children);//初始化追踪子进程链表
INIT_LIST_HEAD(&p->ptrace_list); //初始化追踪链表
/* Perform scheduler related setup. Assign this task to a CPU. */
sched_fork(p, clone_flags); //如果是smp系统则给新进程指定cpu
/* Need tasklist lock for parent etc handling! */
write_lock_irq(&tasklist_lock);
p->cpus_allowed = current->cpus_allowed;
if (unlikely(!cpu_isset(task_cpu(p), p->cpus_allowed) ||
!cpu_online(task_cpu(p))))
set_task_cpu(p, smp_processor_id());
/* 如果设置CLONE_PARENT 或 CLONE_THREAD则新进程的真实父进程和父进程的真实父进程一样*/
if (clone_flags & (CLONE_PARENT|CLONE_THREAD))
p->real_parent = current->real_parent;
else
p->real_parent = current; //否则新进程的真实父进程就是当前进程
p->parent = p->real_parent; //新进程的父进程是新进程的真实父进程
spin_lock(¤t->sighand->siglock);
/*
* Process group and session signals need to be delivered to just the
* parent before the fork or both the parent and the child after the
* fork. Restart if a signal comes in before we add the new process to
* it's process group.
* A fatal signal pending means that current will exit, so the new
* thread can't slip out of an OOM kill (or normal SIGKILL).
*/
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_cleanup_namespace;
}
//如果新进程是线程,则将父进程的组领导复制给新进程组领导,如果是进程则组领导是新进程本身
if (clone_flags & CLONE_THREAD) {
p->group_leader = current->group_leader;
list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group);
if (!cputime_eq(current->signal->it_virt_expires,
cputime_zero) ||
!cputime_eq(current->signal->it_prof_expires,
cputime_zero) ||
current->signal->rlim[RLIMIT_CPU].rlim_cur != RLIM_INFINITY ||
!list_empty(¤t->signal->cpu_timers[0]) ||
!list_empty(¤t->signal->cpu_timers[1]) ||
!list_empty(¤t->signal->cpu_timers[2])) {
/*
* Have child wake up on its first tick to check
* for process CPU timers.
*/
p->it_prof_expires = jiffies_to_cputime(1);
}
}
/*
* 继承父进程的IO优先级
*/
p->ioprio = current->ioprio;
if (likely(p->pid)) { //如果新进程pid有效
add_parent(p); //将新进程加入到兄弟进程链表
if (unlikely(p->ptrace & PT_PTRACED))
__ptrace_link(p, current->parent);
//如果新进程p是线程组领导,也就是创建的是进程,则将父进程的一些资源复制给新进程
if (thread_group_leader(p)) {
p->signal->tty = current->signal->tty;
//将当前进程的进程组ID复制给新进程进程组ID,新进程老进程都指向同一个进程组
p->signal->pgrp = process_group(current);
//将当前进程的回话ID复制给新进程,新老进程同属一个回话ID
p->signal->session = current->signal->session;
attach_pid(p, PIDTYPE_PGID, process_group(p));
attach_pid(p, PIDTYPE_SID, p->signal->session);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
__get_cpu_var(process_counts)++;
}
attach_pid(p, PIDTYPE_PID, p->pid);
nr_threads++;
}
total_forks++; //fork次数加一
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
return p; //copy成功返回新进程的指针
/*以下是出错处理*/
bad_fork_cleanup_namespace:
exit_namespace(p);
bad_fork_cleanup_keys:
exit_keys(p);
bad_fork_cleanup_mm:
if (p->mm)
mmput(p->mm);
bad_fork_cleanup_signal:
cleanup_signal(p);
bad_fork_cleanup_sighand:
__cleanup_sighand(p->sighand);
............
............
bad_fork_free:
free_task(p);
fork_out:
return ERR_PTR(retval);
} 复制
此函数中调用的最主要的函数为dup_task_struct,copy_files,copy_fs,copy_sighand,copy_signal,copy_mm,copy_namespace,copy_thread。在处理进程线程的pgid,tgid,group_leader,parent时也有区别,pgid是进程组ID,tgid是线程组ID,group_leader是线程组领导进程,parent是父进程,如果创建的是进程则group_leader是新进程本身,pgid是当前进程(创建子进程的进程)的pgid,tgid是新进程本身,parent是当前进程(创建子进程的进程)。如果创建是的线程则group_leader是当前进程(创建线程的进程)的group_leader,pgid是当前进程的pgid,tgid是当前进程的tgid,parent是当前进程的parent。其中copy_files,copy_fs,copy_sighand,copy_signal,copy_namespace处理流程差不多,都是判断是否有CLONE_XXX标志,如果有则和父进程公用同一个描述符,如果没有则新分配然后初始化。只分析copy_files。然后重点分析dup_task_struct,copy_mm,copy_thread。
copy_files是复制父进程打开的文件描述符,流程如下:
static inline int copy_fs(unsigned long clone_flags, struct task_struct * tsk)
{
if (clone_flags & CLONE_FS) { //如果设置了CLONE_FS标志则不修改新进程的此成员和父进程一样
atomic_inc(¤t->fs->count);
return 0;
}
//否则给新进程分配文件描述符对象,然后将父进程的描述符,复制给新进程的文件描述符
tsk->fs = __copy_fs_struct(current->fs);
if (!tsk->fs)
return -ENOMEM;
return 0;
} 复制
下面看dup_task_struct,分配新进程的task_struct结构体并且做一些初始化。
static inline void setup_thread_stack(struct task_struct *p, struct task_struct *org)
{
//将父进程的thread_info信息复制给新进程的thread_info
*task_thread_info(p) = *task_thread_info(org);
task_thread_info(p)->task = p; //将新进程thread_info的task指针,指向新进程的task地址
}
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk; //新进程指针
struct thread_info *ti; //新进程thread_info指针
prepare_to_copy(orig); //体系结构相关函数,i386为空
tsk = alloc_task_struct(); //通过slab cache分配进程对象
if (!tsk)
return NULL;
ti = alloc_thread_info(tsk); //分配thread_info对象
if (!ti) {
free_task_struct(tsk); //如果分配失败则释放新进程对象
return NULL;
}
*tsk = *orig; /*
*首先将父进程的task_struct结构体各个成员复制给新进程,有需要变化的成员
*下面再修改,无需变化的则不用管
*/
tsk->thread_info = ti; //将新进程thread_info结构指向新的thread_info
setup_thread_stack(tsk, orig); //设置新进程的内核栈
/* One for us, one for whoever does the "release_task()" (usually parent) */
atomic_set(&tsk->usage,2);
atomic_set(&tsk->fs_excl, 0);
tsk->btrace_seq = 0;
tsk->splice_pipe = NULL;
return tsk;
} 复制
主要是通过slab分配器,分配一个task_struct结构体,并将父进程的成员信息,复制给新进程,然后设置新进程的内核栈。
再看最重要的函数copy_mm,顾名思义复制内存空间,虚拟内存技术是现代cpu和操作系统的精华所在,重点分析下此函数。
/*
* clone_flags:clone标志
* tsk:新进程结构体指针
*/
static int copy_mm(unsigned long clone_flags, struct task_struct * tsk)
{
struct mm_struct * mm, *oldmm;//新进程mm和父进程mm
int retval;
tsk->min_flt = tsk->maj_flt = 0;
tsk->nvcsw = tsk->nivcsw = 0;
tsk->mm = NULL; //新进程mm初始化为NULL
tsk->active_mm = NULL; //新进程active_mm也初始化为NULL
/*
* Are we cloning a kernel thread?
*
* We need to steal a active VM for that..
*/
oldmm = current->mm; //oldmm为当前进程的内存描述符
if (!oldmm) //如果当前进程的mm为null说明当前进程是内核线程,直接返回
return 0;
if (clone_flags & CLONE_VM) { //如果CLONE标志有CLONE_VM,说明要共享虚拟内存
atomic_inc(&oldmm->mm_users); //当前进程的mm描述符用户数加一
mm = oldmm; //新进程的mm描述符等于父进程的描述符,说明两个进程共享虚拟内存,线程就是这样
goto good_mm; //跳转到goto_mm
}
retval = -ENOMEM;
//如果不共享虚拟内存空间,则需要创建一个新的内存描述符,并将父进程的mm有关信息复制到子进程
mm = dup_mm(tsk);
if (!mm)
goto fail_nomem;
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
fail_nomem:
return retval;
} 复制
从此函数也可以看出,线程和进程的一个重要区别是,是否共享虚拟内存空间,如果创建的是线程则直接把父进程的mm引用,给新线程,如果是进程则需要复制一份内存空间给新进程,所以创建线程消耗要小很多,接下来看dup_mm函数。
/*
* tsk:新进程结构体指针
*/
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;//新进程mm和当前进程mm
int err;
if (!oldmm)
return NULL; //如果当前进程mm为NULL则返回
mm = allocate_mm(); //给新进程分配mm对象,通过slab cache分配器分配的
if (!mm)
goto fail_nomem; //如果内存出错跳转到fail_nomem
memcpy(mm, oldmm, sizeof(*mm));//将当前进程的mm所有信息,复制给新进程mm
if (!mm_init(mm)) //初始化新进程mm
goto fail_nomem;
if (init_new_context(tsk, mm)) //初始化mm上下文,在x86架构下主要是复制LDT(局部描述符表)
goto fail_nocontext;
err = dup_mmap(mm, oldmm); //复制vma和页表项
if (err)
goto free_pt;
mm->hiwater_rss = get_mm_rss(mm);
mm->hiwater_vm = mm->total_vm;
return mm;
free_pt:
mmput(mm);
fail_nomem:
return NULL;
fail_nocontext:
/*
* If init_new_context() failed, we cannot use mmput() to free the mm
* because it calls destroy_context()
*/
mm_free_pgd(mm);
free_mm(mm);
return NULL;
} 复制
此函数主要为新进程分配内存描述符,初始化一些属性,然后调用dup_mmap复制vma和页表,下面看mm_init
static struct mm_struct * mm_init(struct mm_struct * mm)
{
atomic_set(&mm->mm_users, 1); //新进程mm的用户数初始化为1
atomic_set(&mm->mm_count, 1); //新进程mm引用次数初始化为1
init_rwsem(&mm->mmap_sem); //初始化mmap信号量
INIT_LIST_HEAD(&mm->mmlist); //初始化mmlist链表
mm->core_waiters = 0;
mm->nr_ptes = 0; //页表项初始化为0
set_mm_counter(mm, file_rss, 0); //文件映射页初始化为0
set_mm_counter(mm, anon_rss, 0); //匿名映射页初始化为0
spin_lock_init(&mm->page_table_lock); //初始化mm自旋锁
rwlock_init(&mm->ioctx_list_lock); //初始化异步IO链表锁
mm->ioctx_list = NULL; //初始化异步IO链表
mm->free_area_cache = TASK_UNMAPPED_BASE; //空闲区域为mmap起始地址,为1GB 0x40000000
mm->cached_hole_size = ~0UL; //空洞区域0XFFFFFFFF
if (likely(!mm_alloc_pgd(mm))) { //分配页目录对象
mm->def_flags = 0;
return mm;
}
free_mm(mm);
return NULL;
}
static inline int mm_alloc_pgd(struct mm_struct * mm)
{
mm->pgd = pgd_alloc(mm); //分配页目录对象
if (unlikely(!mm->pgd)) //如果内存不足,返回失败
return -ENOMEM;
return 0;
}
/*
* 体系结构相关函数,x86 32位系统只有2级和3级页表,64位系统有4级页表,新版本linux的有5级页表
* 其实页目录基地址就是一个unsigned long *指针,一共1024项
*/
pgd_t *pgd_alloc(struct mm_struct *mm)
{
int i;
pgd_t *pgd = kmem_cache_alloc(pgd_cache, GFP_KERNEL);//通过slab cache分配页目录对象
if (PTRS_PER_PMD == 1 || !pgd) //如果是二级页表也就是没PUD和PMD,则直接返回页目录对象
return pgd;
//如果是三级页表,则分配PMD并设置页目录
for (i = 0; i < USER_PTRS_PER_PGD; ++i) {
pmd_t *pmd = kmem_cache_alloc(pmd_cache, GFP_KERNEL);
if (!pmd)
goto out_oom;
set_pgd(&pgd[i], __pgd(1 + __pa(pmd)));
}
return pgd; //返回页目录对象
out_oom:
//如果出错,则把分配的pmd释放
for (i--; i >= 0; i--)
kmem_cache_free(pmd_cache, (void *)__va(pgd_val(pgd[i])-1));
kmem_cache_free(pgd_cache, pgd);//如果出错释放页目录对象
return NULL;
} 复制
mm_init主要做了初始化一些成员变量,分配页目录对象,并初始化页目录对象。
下面看重要的函数dup_mmap复制vma和页表,先介绍下linux的页表结构,linux支持四级页表,但是有的cpu mmu只支持两级页表或者三级页表,比如x86_32如果不开启PAE则只支持2级页表,开启PAE支持3级页表,x86_64支持四级页表,所以为了适应不同硬件,linux写了一个很巧妙的代码,在只支持二级页表的cpu中,pud和pmd的结果都是pgd,看以下代码
//在支持二级或三级页表的cpu中返回pgd
static inline pud_t * pud_offset(pgd_t * pgd, unsigned long address)
{
return (pud_t *)pgd;
}
//在支持四级页表的cpu中返回真正的pud
#define pud_offset(pgd, address) ((pud_t *) pgd_page(*(pgd)) + pud_index(address)) 复制
x86_32不开启PAE的情况下支持二级页表,mmu翻译过程如下图

线性地址22到31位做为页目录偏移,定位到1024项页目录的其中某一项,然后取页目录的12到31位作为页表项基地址,线性地址的12到21位为偏移定位到具体的页表项,取页表项的12到31位作为内存页面的基地址加上 线性地址的0到11位作为偏移,定位到具体的物理地址。
x86_64支持四级页表,mmu翻译过程如下图:
和二级页表性质差不多,只不过分的更细,因为地址长度为48位。这里不再熬述。下面看具体的复制过程
/*
* mm:新进程mm
* oldmm: 当前进程mm
* 主要功能复制vma,复制页表
*/
static inline int dup_mmap(struct mm_struct *mm, struct mm_struct *oldmm)
{
struct vm_area_struct *mpnt, *tmp, **pprev;
struct rb_node **rb_link, *rb_parent;
int retval;
unsigned long charge;
struct mempolicy *pol;
down_write(&oldmm->mmap_sem);
flush_cache_mm(oldmm); //体系结构相关,x86下为空实现
/*
* Not linked in yet - no deadlock potential:
*/
down_write_nested(&mm->mmap_sem, SINGLE_DEPTH_NESTING);
mm->locked_vm = 0;
mm->mmap = NULL; //新mm起始vma为NULL
mm->mmap_cache = NULL; //最近find_vma的结果为NULL
//将当前进程的mmap区域基地址复制给新mm的free_area_cache
mm->free_area_cache = oldmm->mmap_base;
//cached_hole_size为0xFFFFFFFF,刚才已经赋值又重新赋值,手下误
mm->cached_hole_size = ~0UL;
//vma数量初始为0
mm->map_count = 0;
cpus_clear(mm->cpu_vm_mask);
//初始化vma的红黑树根节点
mm->mm_rb = RB_ROOT;
rb_link = &mm->mm_rb.rb_node;
rb_parent = NULL;
pprev = &mm->mmap; //新mm的起始vma地址给pprev
//遍历当前进程所有的vma
for (mpnt = oldmm->mmap; mpnt; mpnt = mpnt->vm_next) {
struct file *file;
if (mpnt->vm_flags & VM_DONTCOPY) {//如果此vma有不能copy标志,则统计一些信息后跳过
long pages = vma_pages(mpnt);
mm->total_vm -= pages;
vm_stat_account(mm, mpnt->vm_flags, mpnt->vm_file,
-pages);
continue;
}
charge = 0;
if (mpnt->vm_flags & VM_ACCOUNT) {
unsigned int len = (mpnt->vm_end - mpnt->vm_start) >> PAGE_SHIFT;
if (security_vm_enough_memory(len))
goto fail_nomem;
charge = len;
}
//给新进程分配vma
tmp = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
if (!tmp)
goto fail_nomem;
*tmp = *mpnt; //将当前进程此vma的所有属性复制给新进程的此vma
pol = mpol_copy(vma_policy(mpnt));
retval = PTR_ERR(pol);
if (IS_ERR(pol))
goto fail_nomem_policy;
vma_set_policy(tmp, pol);
tmp->vm_flags &= ~VM_LOCKED; //新进程vma去掉VM_LOCKED标志
tmp->vm_mm = mm; //将新进程的vma的内存描述符指向新进程mm
tmp->vm_next = NULL; //新进程vma的next为NULL
anon_vma_link(tmp); //如果是匿名vma,则加入匿名vma链表
file = tmp->vm_file; //新vma所对应的文件
if (file) { //如果此vma是映射的文件,则将当前进程的非线性映射,复制给新进程
struct inode *inode = file->f_dentry->d_inode;
get_file(file);
if (tmp->vm_flags & VM_DENYWRITE)
atomic_dec(&inode->i_writecount);
/* insert tmp into the share list, just after mpnt */
spin_lock(&file->f_mapping->i_mmap_lock);
tmp->vm_truncate_count = mpnt->vm_truncate_count;
flush_dcache_mmap_lock(file->f_mapping);
vma_prio_tree_add(tmp, mpnt);
flush_dcache_mmap_unlock(file->f_mapping);
spin_unlock(&file->f_mapping->i_mmap_lock);
}
/*
* Link in the new vma and copy the page table entries.
*/
*pprev = tmp; //将临时vma复制给新进程的mmap链表
pprev = &tmp->vm_next; //pprev指向下一个地址
//将新进程的vma插入红黑树
__vma_link_rb(mm, tmp, rb_link, rb_parent);
rb_link = &tmp->vm_rb.rb_right;
rb_parent = &tmp->vm_rb;
mm->map_count++; //vma个数加一
retval = copy_page_range(mm, oldmm, mpnt);//复制vma所有的页表项
if (tmp->vm_ops && tmp->vm_ops->open)
tmp->vm_ops->open(tmp);
if (retval)
goto out;
}
retval = 0;
out:
up_write(&mm->mmap_sem);//释放信号量
flush_tlb_mm(oldmm); //体系结构相关,x86为空实现
up_write(&oldmm->mmap_sem);
return retval;
fail_nomem_policy:
kmem_cache_free(vm_area_cachep, tmp); //如果出错则释放刚才分配的vma
fail_nomem:
retval = -ENOMEM;
vm_unacct_memory(charge);
goto out;
} 复制
主要是vma的复制,页表项的复制在copy_page_range函数,看此函数和该函数调用的函数,可以细细品味,linux如何使用一套代码应对不同cpu2 3 4级页表复制时的策略。代码写的很巧妙,适配性很强。
/*
* 将当前进程页表复制给新进程的页表
* dst_mm:新进程mm
* src_mm: 当前进程mm
* vma:当前进程的vma
*/
int copy_page_range(struct mm_struct *dst_mm, struct mm_struct *src_mm,
struct vm_area_struct *vma)
{
pgd_t *src_pgd, *dst_pgd; //当前进程页目录,新进程页目录
unsigned long next;
unsigned long addr = vma->vm_start; //vma线性区起始地址
unsigned long end = vma->vm_end; //vma线性区结束地址
//如果是巨页,则调用copy_hugetlb_page_range
if (is_vm_hugetlb_page(vma))
return copy_hugetlb_page_range(dst_mm, src_mm, vma);
//普通页表复制
dst_pgd = pgd_offset(dst_mm, addr); //addr对应的新页目录项指针
src_pgd = pgd_offset(src_mm, addr); //addr对应的当前目录项指针
do {
/*
*next边界确定,如果是二级页表,一个页目录可以映射4MB,所以如果end - addr大于4MB,
*则next最大为addr + 4MB,否则为next = end
*/
next = pgd_addr_end(addr, end);
//如果硬件只支持二级页表,这项没用,非二级页表,则是判断页目录是否为NULL
if (pgd_none_or_clear_bad(src_pgd))
continue;
//copy pud表,如果硬件只支持二级页表,则pud就是pgd
if (copy_pud_range(dst_mm, src_mm, dst_pgd, src_pgd,
vma, addr, next))
return -ENOMEM;
} while (dst_pgd++, src_pgd++, addr = next, addr != end);
return 0;
} 复制
下面开始pud的复制函数,如果是二级三级页表返回的还是pgd ,啥也不做
/*
* 复制pud表,linux通用代码实现是4级页表,但是通过高超代码设计可以适配2 3 4级页表,可见代码质量很高,
* 设计很巧妙
*/
static inline int copy_pud_range(struct mm_struct *dst_mm, struct mm_struct *src_mm,
pgd_t *dst_pgd, pgd_t *src_pgd, struct vm_area_struct *vma,
unsigned long addr, unsigned long end)
{
pud_t *src_pud, *dst_pud; //当前进程pud表,新进程pud表
unsigned long next;
/*
*如果cpu支持四级页表,如果pgd有对应的pud,则返回pud表指针,否则分配一个pud
*如果cpu支持二级页表,则直接返回PGD
*/
dst_pud = pud_alloc(dst_mm, dst_pgd, addr);
if (!dst_pud)
return -ENOMEM;
/*
* 如果是四级页表返回当前进程的pud表,如果是二级页表返回pgd
*/
src_pud = pud_offset(src_pgd, addr);
do {
//确定next地址,如果是四级页表,则在x86_64架构下一项pud映射为1GB物理内存,所以
//next的边界最大为addr + 1GB
next = pud_addr_end(addr, end);
if (pud_none_or_clear_bad(src_pud))
continue;
//复制pmd表
if (copy_pmd_range(dst_mm, src_mm, dst_pud, src_pud,
vma, addr, next))
return -ENOMEM;
} while (dst_pud++, src_pud++, addr = next, addr != end);
return 0;
} 复制
下面开始复制pmd,逻辑同上
static inline int copy_pmd_range(struct mm_struct *dst_mm, struct mm_struct *src_mm,
pud_t *dst_pud, pud_t *src_pud, struct vm_area_struct *vma,
unsigned long addr, unsigned long end)
{
pmd_t *src_pmd, *dst_pmd;
unsigned long next;
/*
*如果cpu支持四级页表,如果pud有对应的pmd,则返回pmd表指针,否则分配一个pmd
*如果cpu支持二级页表,则直接返回PGD
*如果cpu支持三级页表,则返回PGD对应的PMD
*/
dst_pmd = pmd_alloc(dst_mm, dst_pud, addr);
if (!dst_pmd)
return -ENOMEM;
/*
* 如果是三级或者四级页表返回当前进程的pmd表,如果是二级页表返回pgd
*/
src_pmd = pmd_offset(src_pud, addr);
do {
//确定next地址,x86_32开启PAE支持三级页表,则一项PMD映射2MB内存,x86_64支持四级页表
//一项PMD映射也是映射2MB内存
next = pmd_addr_end(addr, end);
if (pmd_none_or_clear_bad(src_pmd))
continue;
//重要函数,复制最后一级页表项,234级页表都最重要的函数
if (copy_pte_range(dst_mm, src_mm, dst_pmd, src_pmd,
vma, addr, next))
return -ENOMEM;
} while (dst_pmd++, src_pmd++, addr = next, addr != end);
return 0;
} 复制
最重要的复制函数就是copy_pte_range,如下
/*
* copy页表最终函数,也是最重要的函数,cpu不管支持2 3 4级页表都将在此函数完成最终
* 复制
*/
static int copy_pte_range(struct mm_struct *dst_mm, struct mm_struct *src_mm,
pmd_t *dst_pmd, pmd_t *src_pmd, struct vm_area_struct *vma,
unsigned long addr, unsigned long end)
{
pte_t *src_pte, *dst_pte; //当前进程页表项,新进程页表项
spinlock_t *src_ptl, *dst_ptl; //自旋锁
int progress = 0;
int rss[2];
again:
rss[1] = rss[0] = 0; //映射页表数
//获取新进程pmd对应的页表项指针,如果为NULL则新分配一个
dst_pte = pte_alloc_map_lock(dst_mm, dst_pmd, addr, &dst_ptl);
if (!dst_pte)
return -ENOMEM;
//获取当前进程pmd对应的页表项指针
src_pte = pte_offset_map_nested(src_pmd, addr);
src_ptl = pte_lockptr(src_mm, src_pmd);
spin_lock_nested(src_ptl, SINGLE_DEPTH_NESTING);
//开始复制
do {
/*
* We are holding two locks at this point - either of them
* could generate latencies in another task on another CPU.
*/
if (progress >= 32) {//如果progess>=32
progress = 0;
/*
*因为如果页表项很多。复制很耗时间,所以如果有进程需要调度,则先跳出循环,去调度
*新进程,在下面cond_resched()后有一个goto again,也就是当前进程再次被调度执行
*的时候,会重新从打断的地方复制
*/
if (need_resched() ||
need_lockbreak(src_ptl) ||
need_lockbreak(dst_ptl))
break;
}
if (pte_none(*src_pte)) { //如果页表项为null则跳过当前页表项
progress++; //progress+1,因为此操作耗时短,所以只加一
continue;
}
//如果pte不为NULL则开始真正复制pte
copy_one_pte(dst_mm, src_mm, dst_pte, src_pte, vma, addr, rss);
progress += 8;//copy_one_pte耗时稍微长,所以progress+8
} while (dst_pte++, src_pte++, addr += PAGE_SIZE, addr != end);
spin_unlock(src_ptl);
pte_unmap_nested(src_pte - 1);
add_mm_rss(dst_mm, rss[0], rss[1]);
pte_unmap_unlock(dst_pte - 1, dst_ptl);
cond_resched(); //调度其它进程
//如果此进程被挂起了,再次恢复运行时,需要检查是否复制完,如果没有则接着复制
if (addr != end)/
goto again;
return 0;
} 复制
此函数有一个点很重要,就是在进行页表项复制时,如果页表项很多会很耗时间,如果此时有一个进程优先级很高,需要被调度,则我们不能等到复制完才去调度,这样会让用户难以忍受,或者如果是实时进程,则会出现问题,所以每复制四项,就去检查是否有需要被调度的进程,如果有,则立马进行调度。
下面看copy_one_pte函数,最终的复制函数
/*
* 复制一个页表项
* dst_mm: 新进程的mm描述符
* src_mm: 当前进程mm描述符
* dst_pte:新进程的页表项
* src_pte: 当前进程页表项
* vma:当前进程vma
* addr:映射起始地址
* rss:映射页面数
*/
static inline void
copy_one_pte(struct mm_struct *dst_mm, struct mm_struct *src_mm,
pte_t *dst_pte, pte_t *src_pte, struct vm_area_struct *vma,
unsigned long addr, int *rss)
{
unsigned long vm_flags = vma->vm_flags; //vma标志
pte_t pte = *src_pte; //当前进程pte表项临时变量
struct page *page; //页面指针
/* pte contains position in swap or file, so copy. */
if (unlikely(!pte_present(pte))) { //如果pte对应的页框不在内存
if (!pte_file(pte)) { //如果pte映射的不是文件,则说明页框被换到了swap交换区
swp_entry_t entry = pte_to_swp_entry(pte);
swap_duplicate(entry);
/* make sure dst_mm is on swapoff's mmlist. */
//如果新进程的mmlist为空,则把新进程的mm添加到mm链表
if (unlikely(list_empty(&dst_mm->mmlist))) {
spin_lock(&mmlist_lock);
if (list_empty(&dst_mm->mmlist))
list_add(&dst_mm->mmlist,
&src_mm->mmlist);
spin_unlock(&mmlist_lock);
}
//如果编译时配置了页面迁移,这个才有用
if (is_write_migration_entry(entry) &&
is_cow_mapping(vm_flags)) {
/*
* COW mappings require pages in both parent
* and child to be set to read.
*/
make_migration_entry_read(&entry);
pte = swp_entry_to_pte(entry);
set_pte_at(src_mm, addr, src_pte, pte);
}
}
goto out_set_pte;//如果是文件映射则直接跳到设置新页表项函数
}
/*
* If it's a COW mapping, write protect it both
* in the parent and the child
*/
/*
*如果父进程此vma是写时复制,则将pte表项的写权限标志清除,这样在父进程或者子进程写
*数据的时候会触发缺页异常程序,然后缺页异常处理程序会判断是因为写时复制导致的,这样
*会为父进程或者子进程分配新的页面,并把旧页面的内容复制到新页面。这样做的好处是
* 减少开销,将复制操作延迟到了写数据的时候。
*/
if (is_cow_mapping(vm_flags)) {
//清除父进程写权限
ptep_set_wrprotect(src_mm, addr, src_pte);
//清除子进程写权限
pte = *src_pte;
}
/*
* If it's a shared mapping, mark it clean in
* the child
*/
//如果vma具有共享标志,则将pte脏标志清除
if (vm_flags & VM_SHARED)
pte = pte_mkclean(pte);
pte = pte_mkold(pte); //清除pte已经使用标志
//获取父进程pte对应的物理页框
page = vm_normal_page(vma, addr, pte);
if (page) {
get_page(page);//页框引用次数加一
page_dup_rmap(page);//页框映射次数加一
rss[!!PageAnon(page)]++; //匿名页或非匿名页映射加一
}
out_set_pte:
set_pte_at(dst_mm, addr, dst_pte, pte); //把修改后的pte复制给新进程pte
} 复制
此函数最重要的一点就是对于可写的区,比如数据段,堆,栈等vma所对应的pte,需要设置写时复制,父子进程共享只读段,可以写的段需要独自拥有,但是可写段的数据复制要延迟到写发生的时候,这样可以提高效率,或者是避免不必要的操作,比如虽然数据段可写,但是接下来的代码直到进程结束没有发生写操作,这样我们就不必去复制页面了。另外fork函数也会快很多,所以有必要把写时复制延迟到写的时候在缺页处理函数中执行。进程 线程(轻量级进程)创建的主要函数已经讲完了,其中进程和线程的主要区别就是共享资源的问题,进程不共享任何资源,父子进程只会映射到相同的只读数据段,线程会共享fs(共享根目录和当前工作目录),files(打开文件描述符),mm(虚拟内存空间),SIGNAL(信号)等,所以线程创建要快很多,少去了很多资源的复制。
下面看最后一个函数,copy_thread主要复制cpu特定的进程上下文信息
int copy_thread(int nr, unsigned long clone_flags, unsigned long esp,
unsigned long unused,
struct task_struct * p, struct pt_regs * regs)
{
struct pt_regs * childregs; //子进程内核栈顶
struct task_struct *tsk;
int err;
childregs = task_pt_regs(p);//获取子进程栈顶指针
*childregs = *regs; //将父进程的内核栈帧结构复制给子进程内核栈帧
childregs->eax = 0; //调用完毕后创建进程完毕后子进程返回值
childregs->esp = esp; //子进程的用户栈顶指针,在发生特权级切换时,内核栈会变成用户栈
p->thread.esp = (unsigned long) childregs; //内核栈顶指针
p->thread.esp0 = (unsigned long) (childregs+1);
//新进程第一次被调度时,执行ret_from_fork汇编例程
p->thread.eip = (unsigned long) ret_from_fork;
savesegment(fs,p->thread.fs); //保存fs段寄存器
savesegment(gs,p->thread.gs);//保存gs段寄存器
/*
* IO相关逻辑
*/
tsk = current;
if (unlikely(test_tsk_thread_flag(tsk, TIF_IO_BITMAP))) {
p->thread.io_bitmap_ptr = kmalloc(IO_BITMAP_BYTES, GFP_KERNEL);
if (!p->thread.io_bitmap_ptr) {
p->thread.io_bitmap_max = 0;
return -ENOMEM;
}
memcpy(p->thread.io_bitmap_ptr, tsk->thread.io_bitmap_ptr,
IO_BITMAP_BYTES);
set_tsk_thread_flag(p, TIF_IO_BITMAP);
}
/*
* Set a new TLS for the child thread?
*/
//为子线程设置TLS
if (clone_flags & CLONE_SETTLS) {
struct desc_struct *desc;
struct user_desc info;
int idx;
err = -EFAULT;
if (copy_from_user(&info, (void __user *)childregs->esi, sizeof(info)))
goto out;
err = -EINVAL;
if (LDT_empty(&info))
goto out;
idx = info.entry_number;
if (idx < GDT_ENTRY_TLS_MIN || idx > GDT_ENTRY_TLS_MAX)
goto out;
desc = p->thread.tls_array + idx - GDT_ENTRY_TLS_MIN;
desc->a = LDT_entry_a(&info);
desc->b = LDT_entry_b(&info);
}
err = 0;
out:
//IO位图相关操作
if (err && p->thread.io_bitmap_ptr) {
kfree(p->thread.io_bitmap_ptr);
p->thread.io_bitmap_max = 0;
}
return err;
} 复制
此函数最重要的就是内核栈的设置,把返回用户态的栈和地址都从父进程复制给了子进程,然后将子进程上下文切换用到的数据结构thread_struct的esp成员指向了子进程的内核栈。
创建进程线程主要流程图如下:
至此分析完毕。