【1】创建目录对象
创建文件–带有文件目录 如
test1/test3/hello.txt
。如果目标对象已经存在,则会进行覆盖。
AmazonS3 singleAmazonS3 = this.getSingleAmazonS3();
// 创建文件--带有文件目录 如 test1/test3/hello.txt
Bucket bucket = cosFileSystem.getBucket(singleAmazonS3);
singleAmazonS3.putObject(bucket.getName(),"test1/test3/hello.txt",new File("./hello.txt")); 通过控制台登录查看,会看到如下结构:
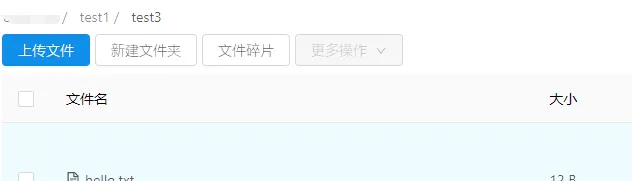
注意,这里目标对象的key建议不要以
/
开头,否则bucket内会有一个目录
/
,这个不符合COS的规范。比如
/test1/test3/hello.txt
,其最终效果不是我们想象的
test1 -- test3 目录下有个hello.txt
,而是
/ -- test1---test3 下有个hello.txt
。
对象名称如果带有目录,那么应该是
a/b/hello.txt
格式,
a\b\hello.txt
格式是错误的,不支持的。
【2】获取文件对象
① 通过key直接获取文件对象本身
假设文件对象名称为
test1/test4/hello.txt
,那么如下所示可以拿到文件对象然后包装为流。之后就是最基本的IO操作了,可以实现文件下载。
S3Object amazonS3Object = singleAmazonS3.getObject(bucket.getName(), "test1/test4/hello.txt");
S3ObjectInputStream objectInputStream = amazonS3Object.getObjectContent();
BufferedInputStream bufferedInputStream = new BufferedInputStream(objectInputStream); ② 获取文件下载链接
Bucket bucket = getBucket(singleAmazonS3);
GeneratePresignedUrlRequest request = new GeneratePresignedUrlRequest(bucket.getName(), "test1/test4/hello.txt");
URL url = singleAmazonS3.generatePresignedUrl(request);
logger.debug("{}生成的文件下载链接为:{}",saveName,url);
HttpURLConnection connection = (HttpURLConnection)url.openConnection();
connection.setConnectTimeout(15000);
connection.connect();
InputStream urlInputStream = connection.getInputStream(); ③ 判断文件对象是否存
AmazonS3 singleAmazonS3 = this.getSingleAmazonS3();
Bucket bucket = singleAmazonS3.listBuckets().get(0);
// true or false
boolean exist = singleAmazonS3.doesObjectExist(bucket.getName(), "111.txt"); 【3】异常解决
// 原始上传
singleAmazonS3.putObject(bucket.getName(), saveName,inputStream , new ObjectMetadata());
//修改为如下 -也就是说给objectMetadata设置长度
ObjectMetadata objectMetadata = new ObjectMetadata();
objectMetadata.setContentLength(inputStream.available());
singleAmazonS3.putObject(bucket.getName(), saveName,inputStream , objectMetadata); ![java实现pdf文件的电子签字+盖章+二维码+水印+PDF文件加密的解决方案二、使用itextPDF实现PDF电子公章工具类三、thymeleaf+itext签字功能+PDF文件加密实现四、PDF实现生成水印并删除源文件五、PDF使用工具Adobe Acrobat DC+PDF+Itext模板实现二维码功能[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)