1.Standalone-client 提交任务方式
提交命令:
[root@node4 bin]# ./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi /opt/spark-2.3.1/examples/jars/spark-examples_2.11-2.3.1.jar 100
[root@node4 bin]# ./spark-submit --master spark://node1:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi /opt/spark-2.3.1/examples/jars/spark-examples_2.11-2.3.1.jar 100
#两种提交都行 执行原理图解
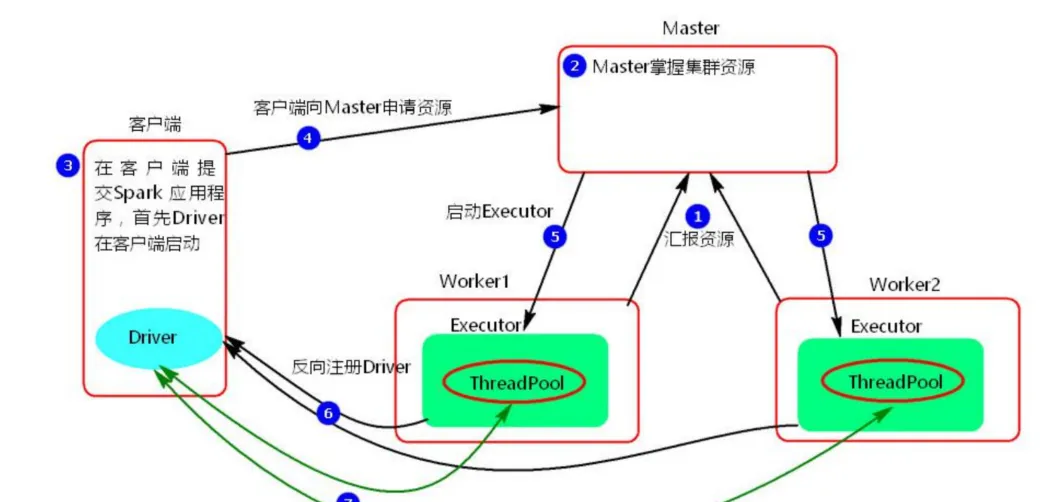
执行流程:
- client 模式提交任务后,会在客户端启动 Driver 进程。
- Driver 会向 Master 申请启动 Application 启动的资源。
- Master 收到请求之后会在对应的 Worker 节点上启动 Executor
- Executor 启动之后,会注册给 Driver 端,Driver 掌握一批计算 资源。
- Driver 端将 task 发送到 worker 端执行。worker 将 task 执行结 果返回到 Driver 端。
特点:当在客户端提交多个Spark application时,每个application都会启动一个Driver
总结:client 模式适用于测试调试程序。Driver 进程是在客户端启动的,这里的客 户端就是指提交应用程序的当前节点。在 Driver 端可以看到 task 执行的情 况。生产环境下不能使用 client 模式,是因为:假设要提交 100 个,application 到集群运行,Driver 每次都会在 client 端启动,那么就会导致 客户端 100 次网卡流量暴增的问题。client 模式适用于程序测试,不适用 于生产环境,在客户端可以看到 task 的执行和结果
2.Standalone-cluster 提交任务方式
提交命令
[root@node4 bin]# ./spark-submit --master spark://node1:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi /opt/spark-2.3.1/examples/jars/spark-examples_2.11-2.3.1.jar 100 执行原理图解

执行流程
- cluster 模式提交应用程序后,会向 Master 请求启动 Driver.
- Master 接受请求,随机在集群一台节点启动 Driver 进程。
- Driver 启动后为当前的应用程序申请资源。
- Driver 端发送 task 到 worker 节点上执行。
- worker 将执行情况和执行结果返回给 Driver 端。
- Driver 负责应用程序资源的申请。
- 任务的分发。
- 结果的回收。
- 监控 task 执行情况。