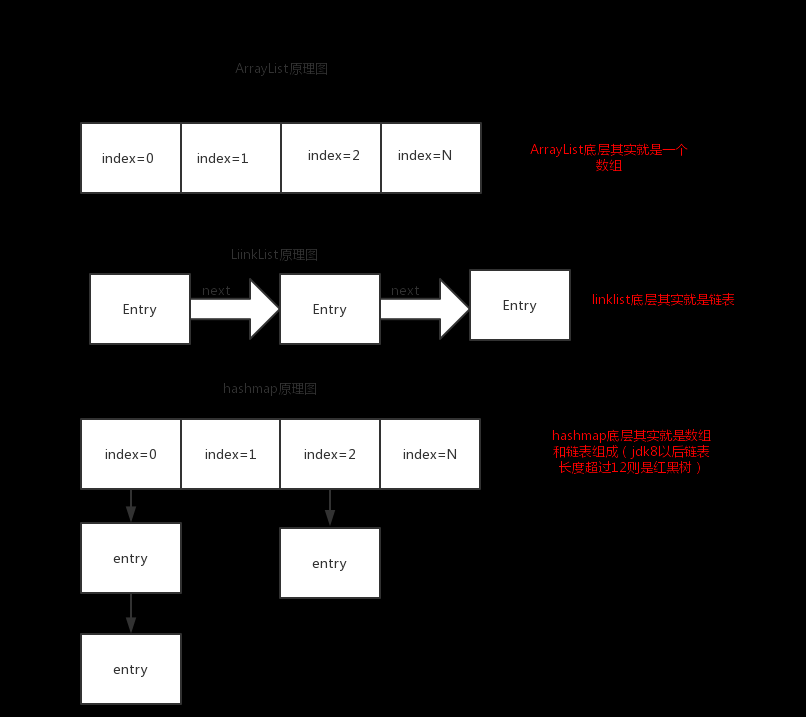
上面是我个人画的简单的原理图,通过上面的图片我们基本也是可以看出几个集合底层到底是什么。所以要手写一个简单自己的集合也是非常简单的,
手写思路:
1、创建一个接口然后定义需要实现的方法
2、现实接口然后编写每个方法的简单逻辑
3、测试成果

这是我个人写的代码目录,还是很简单的
1、HashMap:
public interface EasyMap<k,v> {
int size();
boolean isEmpty();
Object get(Object key);
void put(Object key,Object value);
interface Entry<k,v>{
k getKey();
v getValue();
}
}
public class EasyHashMap implements EasyMap{
//默认初始容器大小
private final int DEFAULT_INITIAL_CAPACITY=1<<4;
// 根据定义的静态内部类,初始化链表,长度为默认长度
Node[] hashMap = new Node[DEFAULT_INITIAL_CAPACITY];
// 加载因子
private final float DEFAULT_LOAD_FACTOR = 0.75f;
//长度
int size=0;
@Override
public int size() {
return size;
}
@Override
public boolean isEmpty() {
return size==0;
}
@Override
public void put(Object key, Object value) {
// 判断是否超过加载因子(是都一定要先判断,一开始加入时就开始执行判断,也很耗时
// 或许可以到达一定程度后再开始判断以减少判断次数)
if (++size * 1.0 / hashMap.length > DEFAULT_LOAD_FACTOR)
rehash();
//计算hashcode
int hashvalue=hash(key);
// 计算出应该存放的位置
int index=indexFor(hashvalue,hashMap.length);
Node node = new Node(hashvalue,key, value);
input(node,hashMap,index);
}
// 添加函数
private void input(Node node, Node[] hashMap, int index) {
//判断下标是否存在值,不存在则直接设置值
if(hashMap[index]==null){
hashMap[index]=node;
}else{
// 否则,遍历链表
// 先用temp记下HeadNode[index],然后遍历链表
//存在则key则不添加
Node temp = hashMap[index];
if (node.key.equals(temp.key)) {
System.out.println(“键值” + temp.key + “已存在”);
} else {
while (temp.next != null) {
temp = temp.next;
}
}
temp.next = node; // 把要加入的节点加到链表最后
}
}
@Override
public Object get(Object key) {
int index = indexFor(hash(key), hashMap.length);
// 先找到在哪条链中
Node temp = hashMap[index];
// 先判断头节点是否为空
if (temp == null)
return null;
else {
if (key .equals(temp.key) )
return temp.value;
else {// 遍历链表
while (temp.next != null) {
temp = temp.next;
if (key == temp.key)
return temp.value;
}
}
}
return null;
}
//这个方法的好处就是
public void rehash() {
// 每次扩展都把当前的哈希表增大一倍
Node[] newHeadNode = new Node[hashMap.length * 2];
// 把原来的哈希表依次重新hash进去
for (int i = 0; i < hashMap.length; i++) {
if (hashMap[i] != null) {
int newindex = indexFor(hashMap[i].hashCode, hashMap.length * 2);
// 重新new新的节点来保存原理hash表中的键值对
Node rehashheadnode = new Node(hashMap[i].hashCode,hashMap[i].key, hashMap[i].value);
input(rehashheadnode, newHeadNode, newindex);
Node temp = hashMap[i];
while (temp.next != null) {
temp = temp.next;
Node rehashnextnode = new Node(temp.hashCode,temp.key, temp.value);
int nextindex = indexFor(temp.hashCode, newHeadNode.length);
input(rehashnextnode, newHeadNode, nextindex);
}
}
}
// 重新设置节点数组的引用,就是把newHeadNode数组的地址赋给HeadNode(可以理解为让HeadNode指向newHeadNode)
hashMap = newHeadNode;
}
// 获取插入的位置下标(取模运算)
public int indexFor(int hashValue,int length){
return hashValue % length;
}
// 获取插入的位置,根据Obeject对象的hashcode 获取hash值
public int hash(Object key){
int h;
//返回值必须是整数
return Math.abs((key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16));
}
static class Node implements EasyMap.Entry{
int hashCode;//hash值
Object key;
Object value;
Node next;//下一个节点
Node(int hashCode, Object key, Object value){
this.hashCode=hashCode;
this.key=key;
this.value=value;
}
@Override
public Object getKey() {
return null;
}
@Override
public Object getValue() {
return null;
}
}
}
2、LinkList:
public interface EasyList {
//集合大小
int size();
//集合是否为空
boolean isEmpty();
//是否存在某个值
boolean contians(Object o);
//清空集合
void clear();
//添加
boolean add(Object o);
//移除某个
boolean remove(int index);
Object get(int index);
}
public class EasyLinkedList implements EasyList {
class Node {
Object obj;
Node previous;//前一个
Node next;//下一个
public Object getObj() {
return obj;
}
public void setObj(Object obj) {
this.obj = obj;
}
public Node getPrevious() {
return previous;
}
public void setPrevious(Node previous) {
this.previous = previous;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
public Node(Object obj, Node previous, Node next) {
this.previous = previous;
this.next = next;
this.obj = obj;
}
public Node() {
}
}
// LinkedList相应属性
private Node first = null;
private Node last = null;
private int size = 0;
@Override
public int size() {
return size;
}
@Override
public boolean isEmpty() {
return size == 0;
}
@Override
public boolean contians(Object o) {
for (int i = 0; i < size; i++) {
if (first != null) {
o.equals(first.next.obj);
return true;
}
}
return false;
}
@Override
public void clear() {
first.next = null;
first.previous = null;
last.next = null;
last.previous = null;
first.obj = null;
last.obj = null;
size = 0;
}
@Override
public boolean add(Object o) {
/**
* 1.当第一个元素为空的时候则不存在前一个,设置前一个为空然后第一个和最后一个都是当前的值
* 2、当存在第一个的时候,前一个则是之前集合的最后一个,当前新增的就是目前集合的最后一个元素,
* 前一个的下一个就是当前元素
*/
Node n = new Node();
if (first == null) {
n.setPrevious(null);
n.setObj(o);
n.setNext(null);
first = n;
last = n;
} else {
n.setPrevious(last);
n.setObj(o);
n.setNext(null);
last.setNext(n);
last = n;
}
size++;
return true;
}
@Override
public boolean remove(int index) {
Node temp = node(index);
if (temp == first || temp == last) {
if (temp == first) {
//如果是第一个,则把第一个的下个的前一个元素设为空,下个元素设为第一个
temp.next.previous = null;
first = temp.next;
} else {
//如果是最后一个,则把最后个的的前一个元素设为空,前一个元素设为最后一个
temp.previous.next = null;
last = temp.previous;
}
} else {
temp.next.previous = temp.previous;
temp.previous.next = temp.next;
}
return true;
}
@Override
public Object get(int index) {
rangeCheck(index);
Node temp = node(index);
return temp.obj;
}
/**
* 简单的遍历链表获取到对应下标的值
*
* @param index
* @return
*/
public Node node(int index) {
Node temp = null;
if (first != null) {
temp = first;
}
for (int i = 0; i < index; i++) {
temp = temp.next;
}
return temp;
}
// 对索引下标进行合法性检查
private void rangeCheck(int index) {
if (index < 0 || index >= size) {
try {
throw new IndexOutOfBoundsException();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
3、ArrayList:
public interface EasyList {
public void add(T object);
public void add(int index,T object);
public Object remove(int index);
public int size();
public Object get(int index);
public void update(int index,Object obj);
}
public class EasyArrayList implements EasyList {
private transient Object[] elementData;
private int size;
public EasyArrayList(){
this(10);
}
public EasyArrayList(int initialCapacity) {
if(initialCapacity<0)
throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);
elementData = new Object[initialCapacity];
}
@Override
public void add(T object) {
elementData[size++]=object;
}
@Override
public void add(int index, T object) {
rangeCheck(index);
System.arraycopy(elementData, index, elementData, index+1, size);
elementData[index]=object;
size++;
}
@Override
public Object remove(int index) {
Object object=get(index);
int numMoved = elementData.length-index-1;
if(numMoved>0){
System.arraycopy(elementData, index+1, elementData, index, numMoved);
}
elementData[--size]=null;
return object;
}
@Override
public int size() {
return size;
}
@Override
public Object get(int index) {
rangeCheck(index);
return elementData[index];
}
@Override
public void update(int index, Object obj) {
rangeCheck(index);
elementData[index]=obj;
}
/**
* 检测数组是否下标越界
* @param index
*/
private void rangeCheck(int index) {
if (index >= size) {
throw new IndexOutOfBoundsException("length--->"+index);
}
}
}
总结:
ArrayList:数组集合。 查询、修改、新增(尾部新增)快,删除、新增(队列中间)慢,适用于查询、修改较多的场景。
LinkedList:双向链表集合。查询、修改慢(需要遍历集合),新增,删除快(只需要修改前后节点的链接即可),适用于新增、删除较多的场景。
HashMap:结合数组和链表的优势,期望做到增删改查都快速,时间复杂度接近于O(1)。当hash算法较好时,hash冲突较低。适用于增删改查所有场景。
扩展:
HashTable:
底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
初始size为11,扩容:newsize = olesize*2+1
计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
ConcurrentHashMap:
底层采用分段的数组+链表实现,线程安全
通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容