写在前面:
工作中发现大家经常写UDF,偶尔写UDAF,但几乎很少有人写UDTF。通常UDF、UDAF就能满足大多的工作需求了。
当然有很多同事喜欢写map来代替写UDF,这是可以达到同样效果的。map的功能很强大。
你会发现flatMap的功能也很强大。灵活使用它就完成可以实现写UDTF达到的效果。所以,这大概也是看同事代码的时候可以经常看到flatMap,而很少见到写UDTF的原因吧。
当然还有使用mapPartitions()的方法来达到UDAF同样效果的写法。我们在下一篇中介绍。
直接上代码来实例感受下flatMap达到UDTF功能效果的实现。
实例一:使用可变的listBuffer来缓存需要输出的多列数据
//in scala
import org.apache.spark.sql.SparkSession
object udtf {
def main(args:Array[String])={
//因为我用了本地core来运行,所以master设置了local模式
val spark = SparkSession.builder().appName("flatMap-UDTF-Test").master("local[2]")
.enableHiveSupport()
.getOrCreate()
val df =spark.createDataFrame(
Seq((1,"Hello world"),(2,"Toby Gao")
)).toDF("id","words")
df.show()
import spark.implicits._
val result = df.flatMap(row => {
val list = scala.collection.mutable.ListBuffer[(Int,String,String)]() //这里不能用case class ,用tuple来定义ListBuffer中的变量类型可以
val id = row.getAs[Int]("id")
val words = row.getAs[String]("words").split(" ")
for (word <- words) {
list.append((id, word,"flatMap"))
}
list
}).toDF("id","word","flag")
result.printSchema()
result.show(false)
}
}
解读:
输入的DF是2行*2列的:
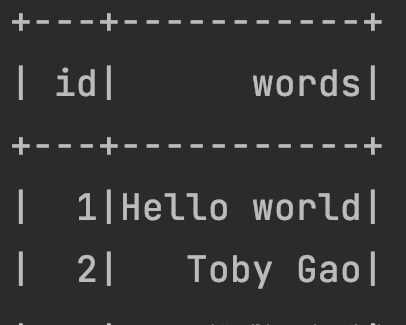
输出的DF的Schema是:

输出的DF结果是:4行*3列的
实例二:使用zip将需要输出的多列数据对应起来
//in scala
package com.jd.datamill9n.goal.metrics.JD
import org.apache.spark.sql.SparkSession
object udtf {
def main(args:Array[String])={
//因为我用了本地core来运行,所以master设置了local模式
val spark = SparkSession.builder().appName("flatMap-UDTF-Test").master("local[2]")
.enableHiveSupport()
.getOrCreate()
val df =spark.createDataFrame(
Seq((1,"Hello world"),(2,"Toby Gao")
)).toDF("id","words")
df.show()
//注意import进来implicits
import spark.implicits._
//使用zip将需要输出的多列对应起来
df.flatMap{row =>{val id=row.getAs[Int]("id")
val words = row.getAs[String]("words")
Array(id,id).zip(words.split(" "))}
}.toDF("id","word").show()
}
}