1 介绍
ResourceManager(RM)负责跟踪群集中的资源,并调度应用程序(例如MapReduce作业)。在Hadoop 2.4之前,ResourceManager是YARN群集中的单点故障。高可用性功能以“活动/备用ResourceManager”对的形式添加了冗余,以消除此单点故障。
2 YARN-HA工作机制
2.1 官方文档
https://hadoop.apache.org/docs/r2.7.4/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
2.2 工作机制
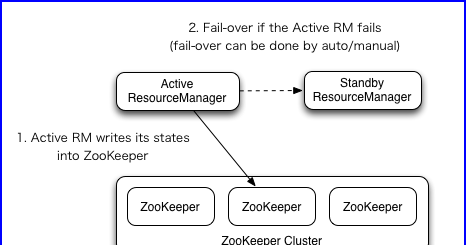
2.3 RM故障转移
ResourceManager HA通过Active / Standby体系结构实现-在任何时间,RM之一都处于活动状态,并且一个或多个RM处于Standby模式,等待活动发生任何事情。启用自动故障转移后,转换为活动状态的触发来自管理员(通过CLI)或集成的故障转移控制器。
手动转换和故障转移
如果未启用自动故障转移,则管理员必须手动将其中一个RM转换为Active。要从一个RM到另一个RM进行故障转移,他们应该先将Active-RM转换为Standby,然后将Standby-RM转换为Active。所有这些都可以使用“ yarn rmadmin ” CLI完成。
自动故障转移
RM可以选择嵌入基于Zookeeper的ActiveStandbyElector,以确定哪个RM应该是Active。当Active发生故障或无响应时,另一个RM被自动选为Active,然后接管。请注意,无需像HDFS那样运行单独的ZKFC守护程序,因为嵌入在RM中的ActiveStandbyElector充当故障检测器和领导选举人,而不是单独的ZKFC守护进程。
RM故障转移上的客户端,ApplicationMaster和NodeManager
当有多个RM时,预计客户端和节点使用的配置(yarn-site.xml)会列出所有RM。客户端,ApplicationMaster(AM)和NodeManager(NM)尝试以循环方式连接到RM,直到它们到达活动RM。如果活动服务器出现故障,他们将继续轮询,直到命中“新”活动服务器为止。此默认重试逻辑实现为org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider。您可以通过实现org.apache.hadoop.yarn.client.RMFailoverProxyProvider并将yarn.client.failover-proxy-provider的值设置为类名来覆盖逻辑。
3 配置YARN-HA集群
3.1 环境准备
(1)修改IP
(2)修改主机名及主机名和IP地址的映射
(3)关闭防火墙
(4)ssh免密登录
(5)安装JDK,配置环境变量等
(6)配置Zookeeper集群
3.2 集群规划
| master-node | slave-node1 | slave-node2 |
| NameNode JournalNode DataNode ZK ResourceManager NodeManager | NameNode JournalNode DataNode ZK ResourceManager NodeManager | JournalNode DataNode ZK NodeManager |
3.3 配置
(1)配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>myyarncluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master-node</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave-node1</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master-node:2181,slave-node1:2181,slave-node2:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
(2)同步更新其他节点的配置信息(分发脚本)
3.4 启动(hdfs,yarn)
1)启动hdfs
HDFS-HA配置参考:https://blog.csdn.net/weixin_38023225/article/details/101346493
2)启动yarn
(1)在master-node中执行:
[[email protected] hadoop-2.7.4]$ sbin/start-yarn.sh
(2)在slave-node1中执行:
[[email protected] hadoop-2.7.4]$ sbin/yarn-daemon.sh start resourcemanager
(3)查看服务状态
[[email protected] hadoop-2.7.4]$ bin/yarn rmadmin -getServiceState rm1
active
[[email protected] hadoop-2.7.4]$ bin/yarn rmadmin -getServiceState rm2
standby
