- 实验一 词法分析程序
一、实验目的:
加深对词法分析器的工作过程的理解;
加强对词法分析方法的掌握。
二、实验内容:
用C语言实现简单的词法分析程序;
能够使用自己编写的分析程序对简单的程序段进行词法分析。
三、实验要求:
- 输入源程序。
- 对源程序进行扫描与分解。
- 按照词法规则,正确识别源程序中的单词符号;
- 识别出的单词以<种别码,值>的形式输出;
- 对于源程序中的词法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成整个源程序的词法分析。
三、简单高级语言
为方便同学们完成编程任务,我们定义了一个简单版本的高级语言。
该语言包含的单词符号、对应的种别码如下表所示:
| 单词符号 | 种别码 | ||
| begin | 1 | : | 17 |
| if | 2 | := | 18 |
| then | 3 | < | 20 |
| while | 4 | <= | 21 |
| do | 5 | <> | 22 |
| end | 6 | > | 23 |
| l(l|d)* | 10 | >= | 24 |
| dd* | 11 | = | 25 |
| + | 13 | ; | 26 |
| - | 14 | ( | 27 |
| * | 15 | ) | 28 |
| / | 16 | # |
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
char prog[80],token[8],ch;
int syn,p,m,n,sum;
char *rwtab[6]={"begin","if","then","while","do","end"};
scaner();
main()
{p=0;
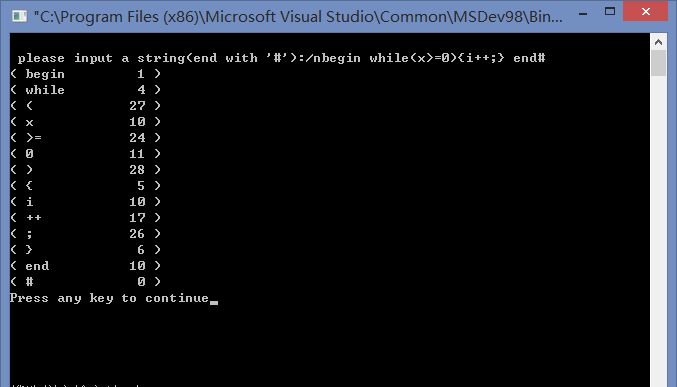
printf("\n please input a string(end with '#'):/n");
do{
scanf("%c",&ch);
prog[p++]=ch;
}while(ch!='#');
p=0;
scaner();
switch(syn)
{case 11:printf("( %-10d%5d )\n",sum,syn);
break;
case -1:printf("you have input a wrong string\n");
getchar();
exit(0);
default: printf("( %-10s%5d )\n",token,syn);
}
}while(syn!=0);
getchar();
}
scaner()
{ sum=0;
for(m=0;m<8;m++)token[m++]=NULL;
ch=prog[p++];
m=0;
while((ch==' ')||(ch=='\n'))ch=prog[p++];
if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A')))
{ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9')))
{token[m++]=ch;
ch=prog[p++];
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{ syn=n+1;
break;
}
else if((ch>='0')&&(ch<='9'))
{ while((ch>='0')&&(ch<='9'))
{ sum=sum*10+ch-'0';
ch=prog[p++];
}
p--;
syn=11;
else switch(ch)
{ case '<':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{ syn=22;
token[m++]=ch;
}
else
{ syn=20;
p--;
case '>':token[m++]=ch;
if(ch=='=')
{ syn=24;
token[m++]=ch;
{ syn=23;
p--;
case '+': token[m++]=ch;
if(ch=='+')
{ syn=17;
{ syn=13;
case '-':token[m++]=ch;
if(ch=='-')
{ syn=29;
{ syn=14;
case '!':ch=prog[p++];
{ syn=21;
token[m++]=ch;
}
{ syn=31;
p--;
}
case '=':token[m++]=ch;
{ syn=25;
}
{ syn=18;
case '*': syn=15;
token[m++]=ch;
break;
case '/': syn=16;
case '(': syn=27;
token[m++]=ch;
case ')': syn=28;
case '{': syn=5;
case '}': syn=6;
case ';': syn=26;
token[m++]=ch;
case '\"': syn=30;
case '#': syn=0;
case ':':syn=17;
default: syn=-1;
token[m++]='\0';
结果: